 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of weak labels for embedding and tagging
Paper and Code
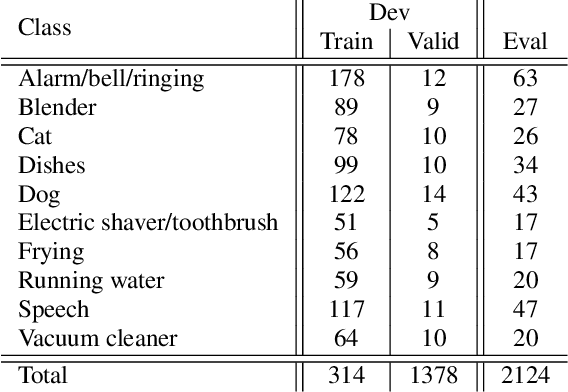
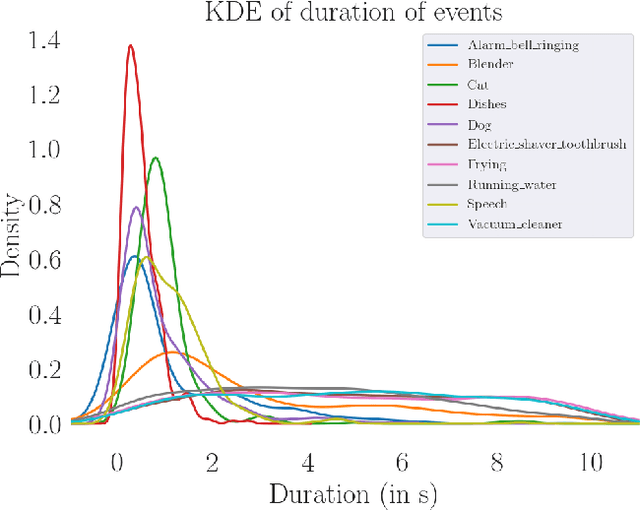
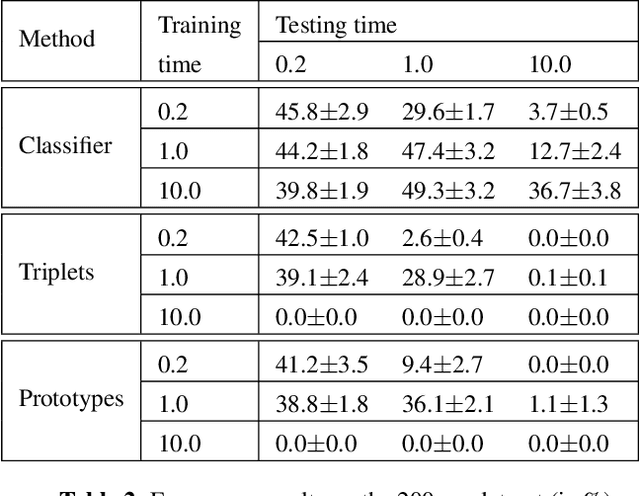
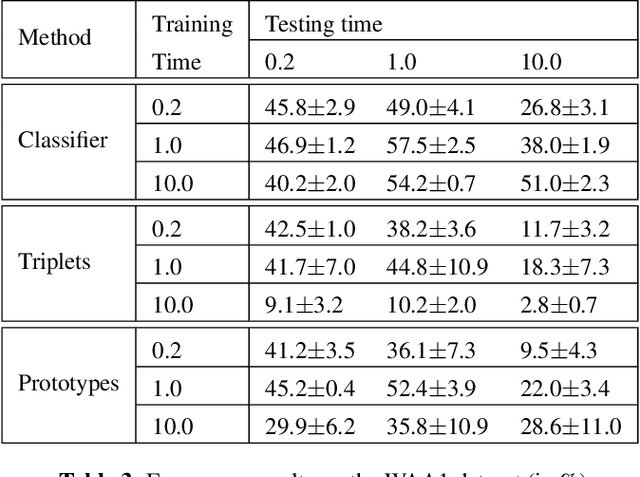
While many datasets and approaches in ambient sound analysis use weakly labeled data, the impact of weak labels on the performance in comparison to strong labels remains unclear. Indeed, weakly labeled data is usually used because it is too expensive to annotate every data with a strong label and for some use cases strong labels are not sure to give better results. Moreover, weak labels are usually mixed with various other challenges like multilabels, unbalanced classes, overlapping events. In this paper, we formulate a supervised problem which involves weak labels. We create a dataset that focuses on difference between strong and weak labels. We investigate the impact of weak labels when training an embedding or an end-to-end classi-fier. Different experimental scenarios are discussed to give insights into which type of applications are most sensitive to weakly labeled data.