 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Tongue Delineation from MRI Images with a Convolutional Neural Network Approach
Dec 06, 2024Tongue contour extraction from real-time magnetic resonance images is a nontrivial task due to the presence of artifacts manifesting in form of blurring or ghostly contours. In this work, we present results of automatic tongue delineation achieved by means of U-Net auto-encoder convolutional neural network. We present both intra- and inter-subject validation. We used real-time magnetic resonance images and manually annotated 1-pixel wide contours as inputs. Predicted probability maps were post-processed in order to obtain 1-pixel wide tongue contours. The results are very good and slightly outperform published results on automatic tongue segmentation.
Complete reconstruction of the tongue contour through acoustic to articulatory inversion using real-time MRI data
Nov 04, 2024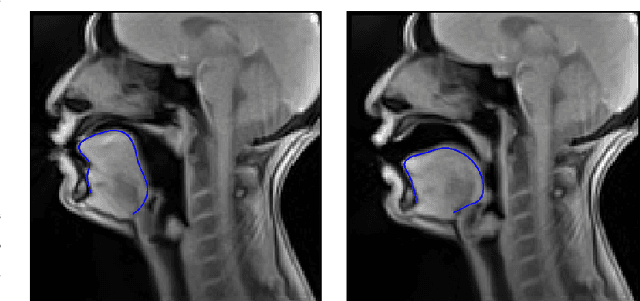
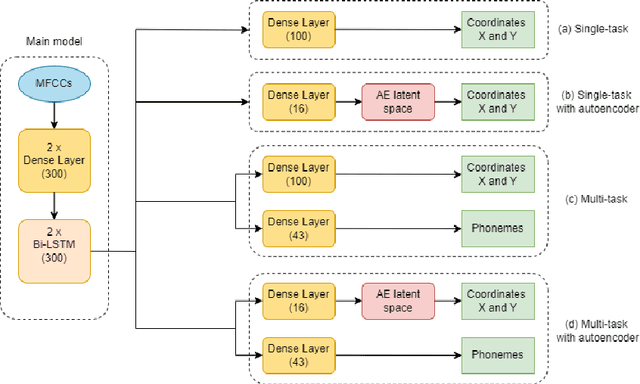
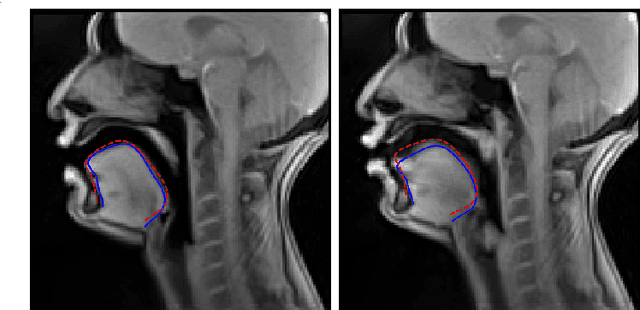
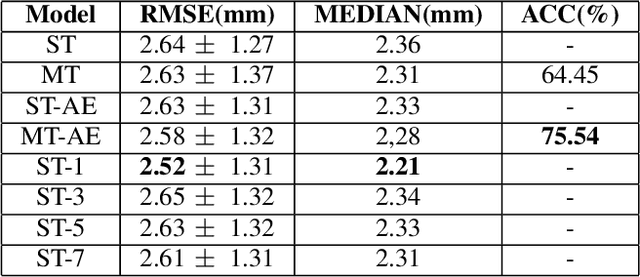
Acoustic articulatory inversion is a major processing challenge, with a wide range of applications from speech synthesis to feedback systems for language learning and rehabilitation. In recent years, deep learning methods have been applied to the inversion of less than a dozen geometrical positions corresponding to sensors glued to easily accessible articulators. It is therefore impossible to know the shape of the whole tongue from root to tip. In this work, we use high-quality real-time MRI data to track the contour of the tongue. The data used to drive the inversion are therefore the unstructured speech signal and the tongue contours. Several architectures relying on a Bi-MSTM including or not an autoencoder to reduce the dimensionality of the latent space, using or not the phonetic segmentation have been explored. The results show that the tongue contour can be recovered with a median accuracy of 2.21 mm (or 1.37 pixel) taking a context of 1 MFCC frame (static, delta and double-delta cepstral features).
An elitist approach for extracting automatically well-realized speech sounds with high confidence
Nov 22, 2005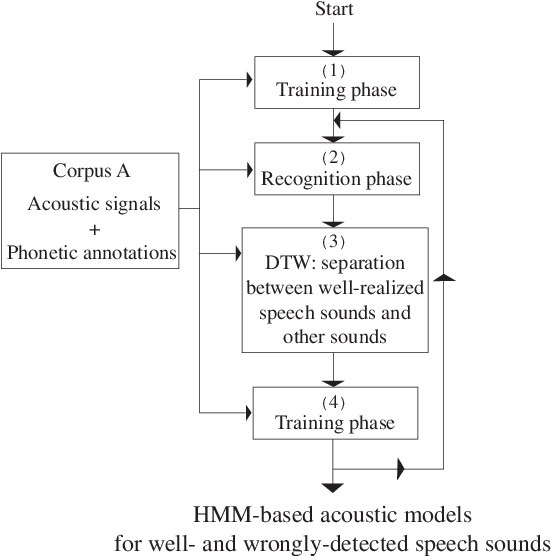
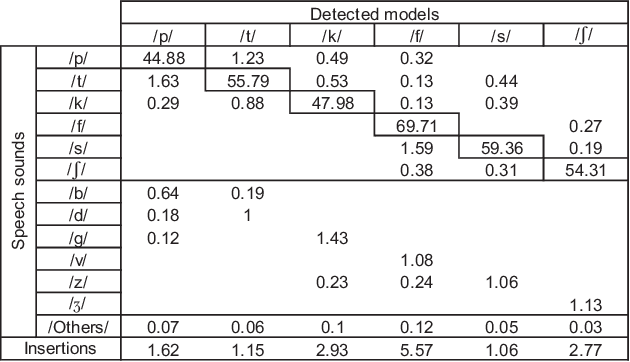
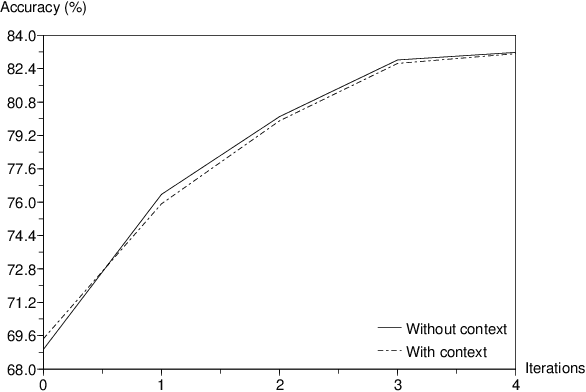
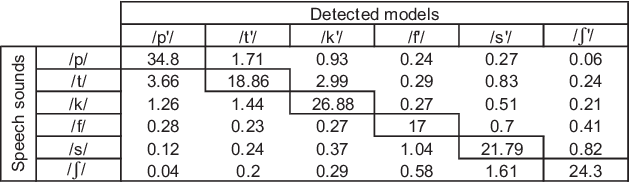
This paper presents an "elitist approach" for extracting automatically well-realized speech sounds with high confidence. The elitist approach uses a speech recognition system based on Hidden Markov Models (HMM). The HMM are trained on speech sounds which are systematically well-detected in an iterative procedure. The results show that, by using the HMM models defined in the training phase, the speech recognizer detects reliably specific speech sounds with a small rate of errors.
Using phonetic constraints in acoustic-to-articulatory inversion
Nov 21, 2005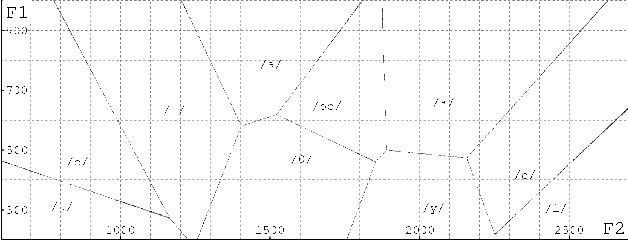
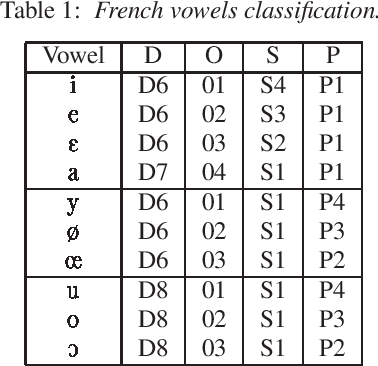

The goal of this work is to recover articulatory information from the speech signal by acoustic-to-articulatory inversion. One of the main difficulties with inversion is that the problem is underdetermined and inversion methods generally offer no guarantee on the phonetical realism of the inverse solutions. A way to adress this issue is to use additional phonetic constraints. Knowledge of the phonetic caracteristics of French vowels enable the derivation of reasonable articulatory domains in the space of Maeda parameters: given the formants frequencies (F1,F2,F3) of a speech sample, and thus the vowel identity, an "ideal" articulatory domain can be derived. The space of formants frequencies is partitioned into vowels, using either speaker-specific data or generic information on formants. Then, to each articulatory vector can be associated a phonetic score varying with the distance to the "ideal domain" associated with the corresponding vowel. Inversion experiments were conducted on isolated vowels and vowel-to-vowel transitions. Articulatory parameters were compared with those obtained without using these constraints and those measured from X-ray data.