 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022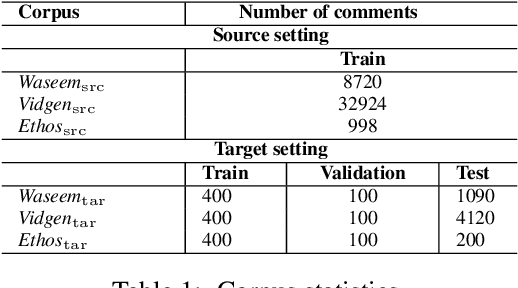
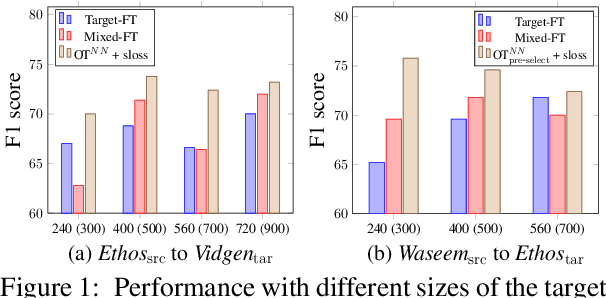

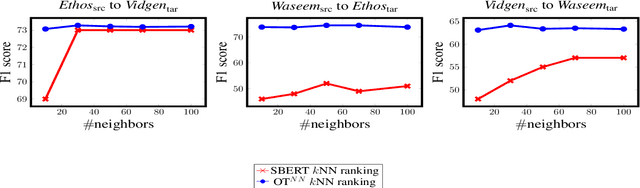
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Domain Classification-based Source-specific Term Penalization for Domain Adaptation in Hate-speech Detection
Sep 18, 2022
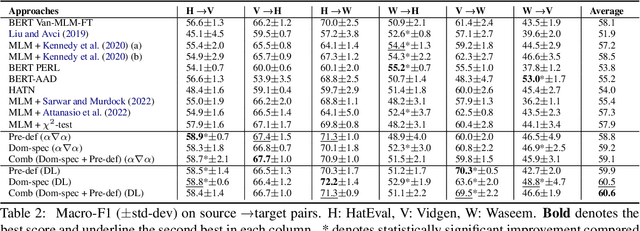


State-of-the-art approaches for hate-speech detection usually exhibit poor performance in out-of-domain settings. This occurs, typically, due to classifiers overemphasizing source-specific information that negatively impacts its domain invariance. Prior work has attempted to penalize terms related to hate-speech from manually curated lists using feature attribution methods, which quantify the importance assigned to input terms by the classifier when making a prediction. We, instead, propose a domain adaptation approach that automatically extracts and penalizes source-specific terms using a domain classifier, which learns to differentiate between domains, and feature-attribution scores for hate-speech classes, yielding consistent improvements in cross-domain evaluation.
Placing M-Phasis on the Plurality of Hate: A Feature-Based Corpus of Hate Online
Apr 28, 2022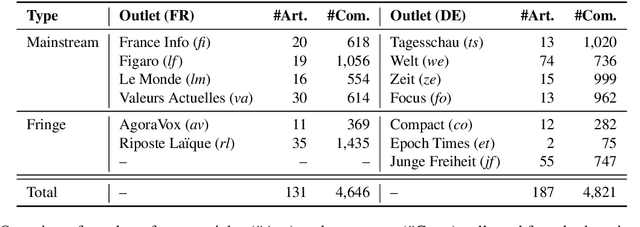

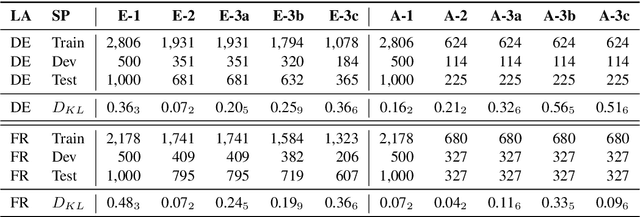
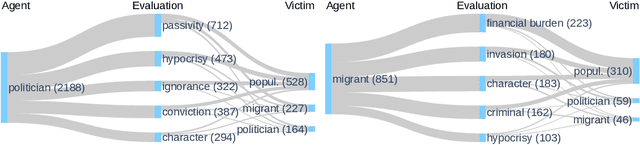
Even though hate speech (HS) online has been an important object of research in the last decade, most HS-related corpora over-simplify the phenomenon of hate by attempting to label user comments as "hate" or "neutral". This ignores the complex and subjective nature of HS, which limits the real-life applicability of classifiers trained on these corpora. In this study, we present the M-Phasis corpus, a corpus of ~9k German and French user comments collected from migration-related news articles. It goes beyond the "hate"-"neutral" dichotomy and is instead annotated with 23 features, which in combination become descriptors of various types of speech, ranging from critical comments to implicit and explicit expressions of hate. The annotations are performed by 4 native speakers per language and achieve high (0.77 <= k <= 1) inter-annotator agreements. Besides describing the corpus creation and presenting insights from a content, error and domain analysis, we explore its data characteristics by training several classification baselines.
Dynamically Refined Regularization for Improving Cross-corpora Hate Speech Detection
Mar 23, 2022
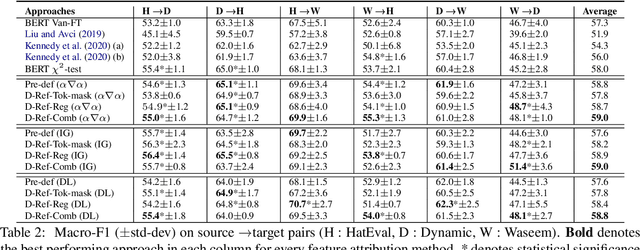
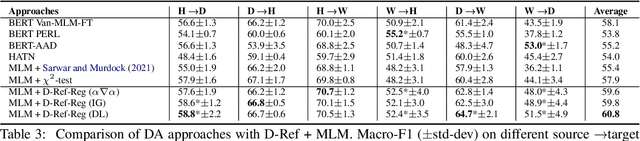

Hate speech classifiers exhibit substantial performance degradation when evaluated on datasets different from the source. This is due to learning spurious correlations between words that are not necessarily relevant to hateful language, and hate speech labels from the training corpus. Previous work has attempted to mitigate this problem by regularizing specific terms from pre-defined static dictionaries. While this has been demonstrated to improve the generalizability of classifiers, the coverage of such methods is limited and the dictionaries require regular manual updates from human experts. In this paper, we propose to automatically identify and reduce spurious correlations using attribution methods with dynamic refinement of the list of terms that need to be regularized during training. Our approach is flexible and improves the cross-corpora performance over previous work independently and in combination with pre-defined dictionaries.
Improving Automatic Hate Speech Detection with Multiword Expression Features
Jun 01, 2021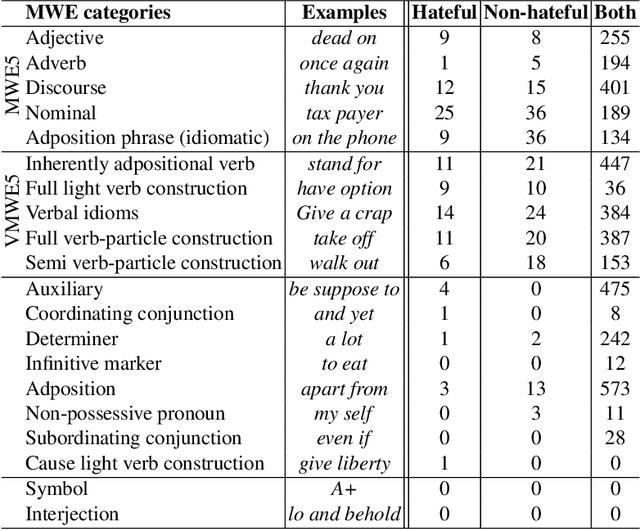
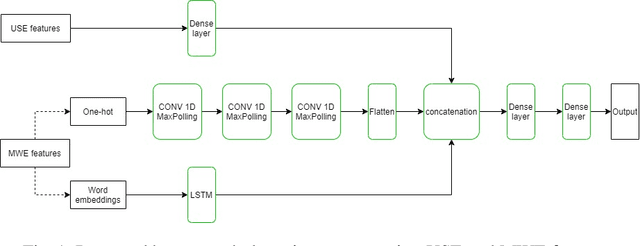

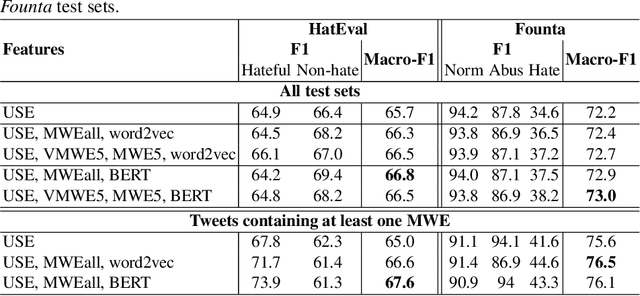
The task of automatically detecting hate speech in social media is gaining more and more attention. Given the enormous volume of content posted daily, human monitoring of hate speech is unfeasible. In this work, we propose new word-level features for automatic hate speech detection (HSD): multiword expressions (MWEs). MWEs are lexical units greater than a word that have idiomatic and compositional meanings. We propose to integrate MWE features in a deep neural network-based HSD framework. Our baseline HSD system relies on Universal Sentence Encoder (USE). To incorporate MWE features, we create a three-branch deep neural network: one branch for USE, one for MWE categories, and one for MWE embeddings. We conduct experiments on two hate speech tweet corpora with different MWE categories and with two types of MWE embeddings, word2vec and BERT. Our experiments demonstrate that the proposed HSD system with MWE features significantly outperforms the baseline system in terms of macro-F1.
DNN-Based Semantic Model for Rescoring N-best Speech Recognition List
Nov 02, 2020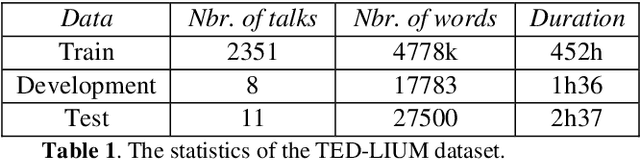
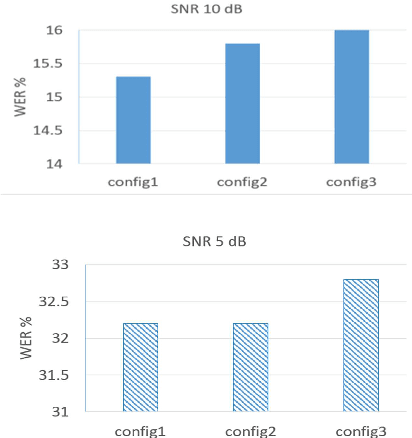
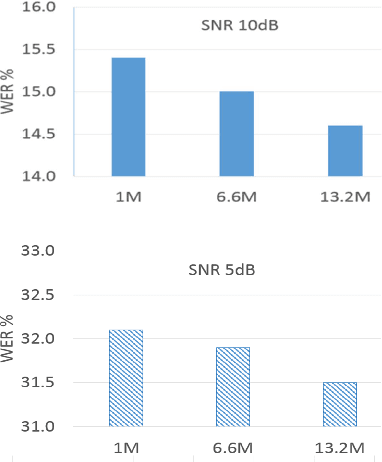
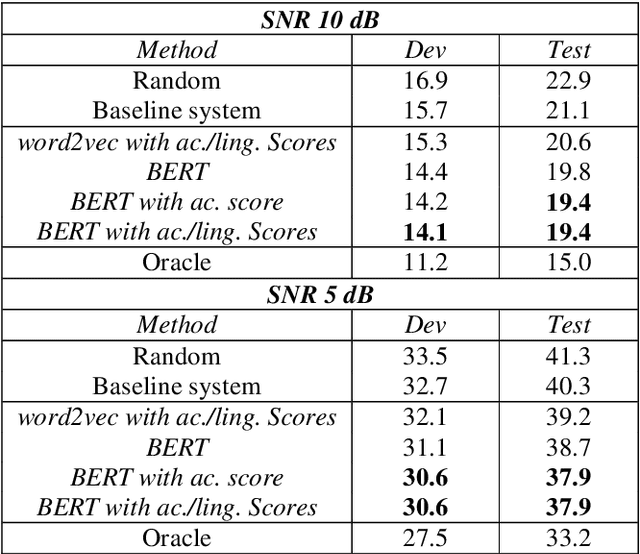
The word error rate (WER) of an automatic speech recognition (ASR) system increases when a mismatch occurs between the training and the testing conditions due to the noise, etc. In this case, the acoustic information can be less reliable. This work aims to improve ASR by modeling long-term semantic relations to compensate for distorted acoustic features. We propose to perform this through rescoring of the ASR N-best hypotheses list. To achieve this, we train a deep neural network (DNN). Our DNN rescoring model is aimed at selecting hypotheses that have better semantic consistency and therefore lower WER. We investigate two types of representations as part of input features to our DNN model: static word embeddings (from word2vec) and dynamic contextual embeddings (from BERT). Acoustic and linguistic features are also included. We perform experiments on the publicly available dataset TED-LIUM mixed with real noise. The proposed rescoring approaches give significant improvement of the WER over the ASR system without rescoring models in two noisy conditions and with n-gram and RNNLM.
Towards non-toxic landscapes: Automatic toxic comment detection using DNN
Nov 19, 2019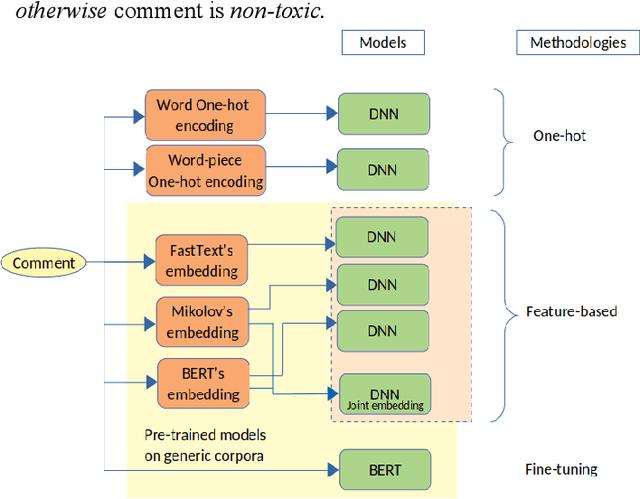
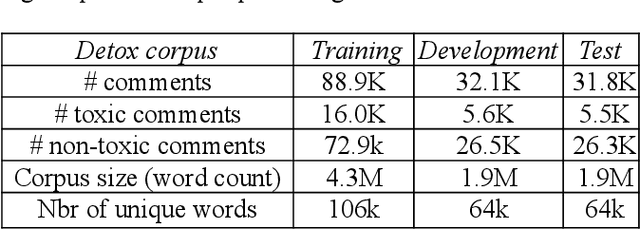
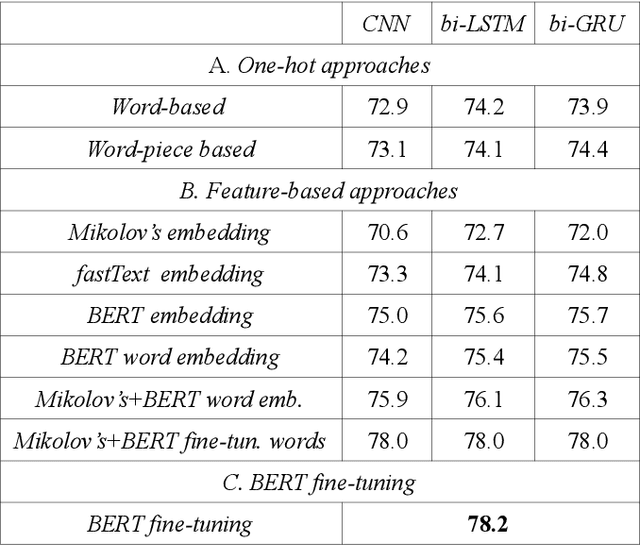
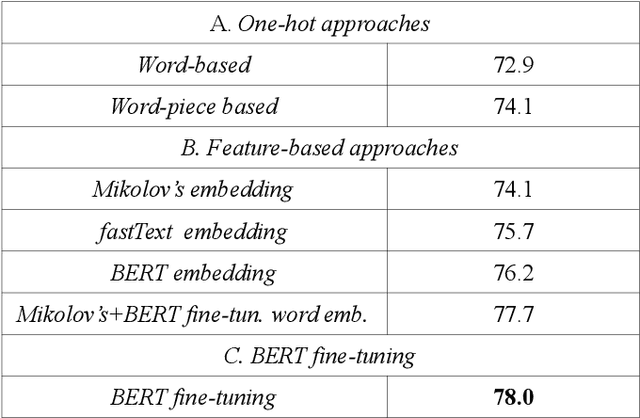
The spectacular expansion of the Internet led to the development of a new research problem in the natural language processing field: automatic toxic comment detection, since many countries prohibit hate speech in public media. There is no clear and formal definition of hate, offensive, toxic and abusive speeches. In this article, we put all these terms under the "umbrella" of toxic speech. The contribution of this paper is the design of binary classification and regression-based approaches aiming to predict whether a comment is toxic or not. We compare different unsupervised word representations and different DNN classifiers. Moreover, we study the robustness of the proposed approaches to adversarial attacks by adding one (healthy or toxic) word. We evaluate the proposed methodology on the English Wikipedia Detox corpus. Our experiments show that using BERT fine-tuning outperforms feature-based BERT, Mikolov's word embedding or fastText representations with different DNN classifiers.
Learning to retrieve out-of-vocabulary words in speech recognition
Mar 01, 2016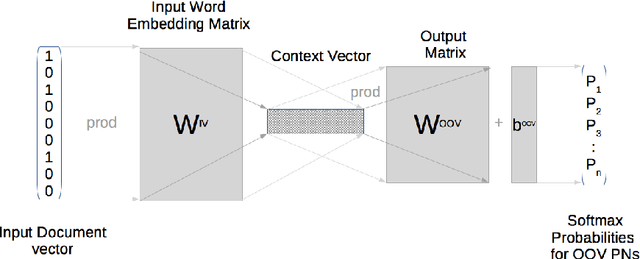

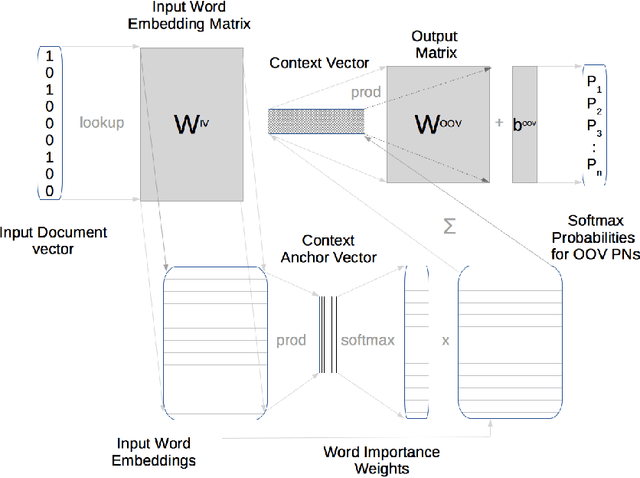
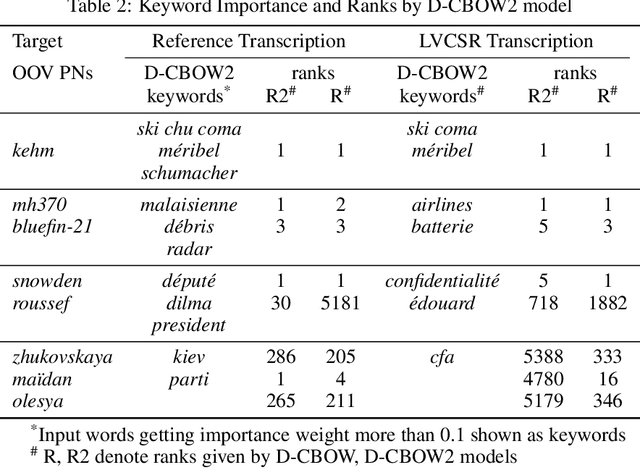
Many Proper Names (PNs) are Out-Of-Vocabulary (OOV) words for speech recognition systems used to process diachronic audio data. To help recovery of the PNs missed by the system, relevant OOV PNs can be retrieved out of the many OOVs by exploiting semantic context of the spoken content. In this paper, we propose two neural network models targeted to retrieve OOV PNs relevant to an audio document: (a) Document level Continuous Bag of Words (D-CBOW), (b) Document level Continuous Bag of Weighted Words (D-CBOW2). Both these models take document words as input and learn with an objective to maximise the retrieval of co-occurring OOV PNs. With the D-CBOW2 model we propose a new approach in which the input embedding layer is augmented with a context anchor layer. This layer learns to assign importance to input words and has the ability to capture (task specific) key-words in a bag-of-word neural network model. With experiments on French broadcast news videos we show that these two models outperform the baseline methods based on raw embeddings from LDA, Skip-gram and Paragraph Vectors. Combining the D-CBOW and D-CBOW2 models gives faster convergence during training.
Amélioration des Performances des Systèmes Automatiques de Reconnaissance de la Parole pour la Parole Non Native
Nov 07, 2007

In this article, we present an approach for non native automatic speech recognition (ASR). We propose two methods to adapt existing ASR systems to the non-native accents. The first method is based on the modification of acoustic models through integration of acoustic models from the mother tong. The phonemes of the target language are pronounced in a similar manner to the native language of speakers. We propose to combine the models of confused phonemes so that the ASR system could recognize both concurrent pronounciations. The second method we propose is a refinment of the pronounciation error detection through the introduction of graphemic constraints. Indeed, non native speakers may rely on the writing of words in their uttering. Thus, the pronounctiation errors might depend on the characters composing the words. The average error rate reduction that we observed is (22.5%) relative for the sentence error rate, and 34.5% (relative) in word error rate.
Combined Acoustic and Pronunciation Modelling for Non-Native Speech Recognition
Nov 06, 2007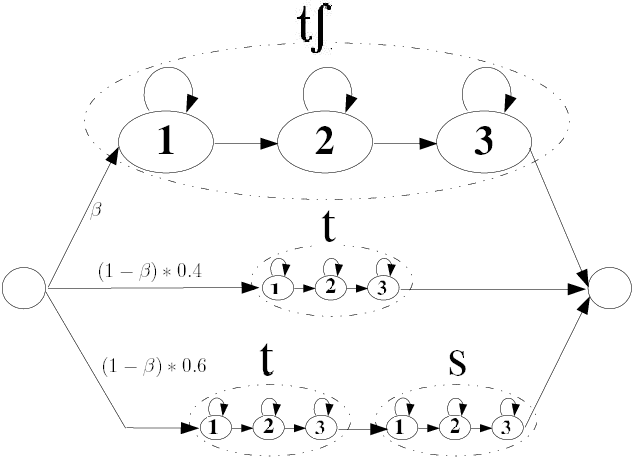



In this paper, we present several adaptation methods for non-native speech recognition. We have tested pronunciation modelling, MLLR and MAP non-native pronunciation adaptation and HMM models retraining on the HIWIRE foreign accented English speech database. The ``phonetic confusion'' scheme we have developed consists in associating to each spoken phone several sequences of confused phones. In our experiments, we have used different combinations of acoustic models representing the canonical and the foreign pronunciations: spoken and native models, models adapted to the non-native accent with MAP and MLLR. The joint use of pronunciation modelling and acoustic adaptation led to further improvements in recognition accuracy. The best combination of the above mentioned techniques resulted in a relative word error reduction ranging from 46% to 71%.