 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to retrieve out-of-vocabulary words in speech recognition
Paper and Code
Mar 01, 2016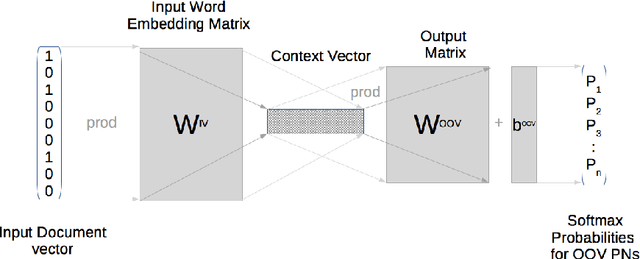

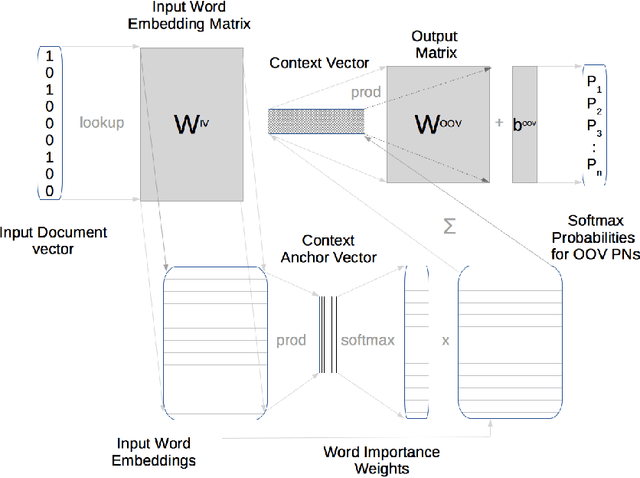
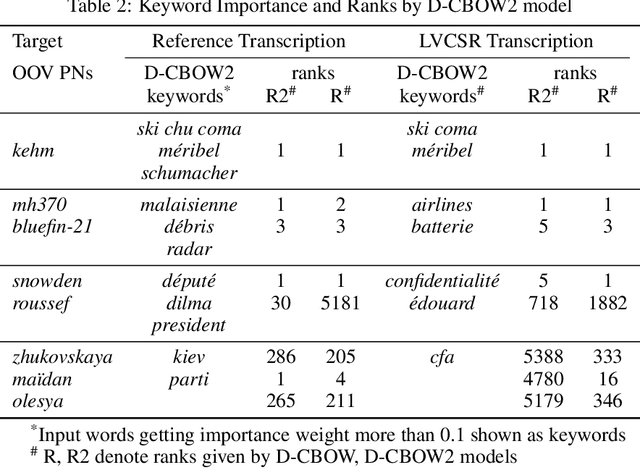
Many Proper Names (PNs) are Out-Of-Vocabulary (OOV) words for speech recognition systems used to process diachronic audio data. To help recovery of the PNs missed by the system, relevant OOV PNs can be retrieved out of the many OOVs by exploiting semantic context of the spoken content. In this paper, we propose two neural network models targeted to retrieve OOV PNs relevant to an audio document: (a) Document level Continuous Bag of Words (D-CBOW), (b) Document level Continuous Bag of Weighted Words (D-CBOW2). Both these models take document words as input and learn with an objective to maximise the retrieval of co-occurring OOV PNs. With the D-CBOW2 model we propose a new approach in which the input embedding layer is augmented with a context anchor layer. This layer learns to assign importance to input words and has the ability to capture (task specific) key-words in a bag-of-word neural network model. With experiments on French broadcast news videos we show that these two models outperform the baseline methods based on raw embeddings from LDA, Skip-gram and Paragraph Vectors. Combining the D-CBOW and D-CBOW2 models gives faster convergence during training.