 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined Acoustic and Pronunciation Modelling for Non-Native Speech Recognition
Paper and Code
Nov 06, 2007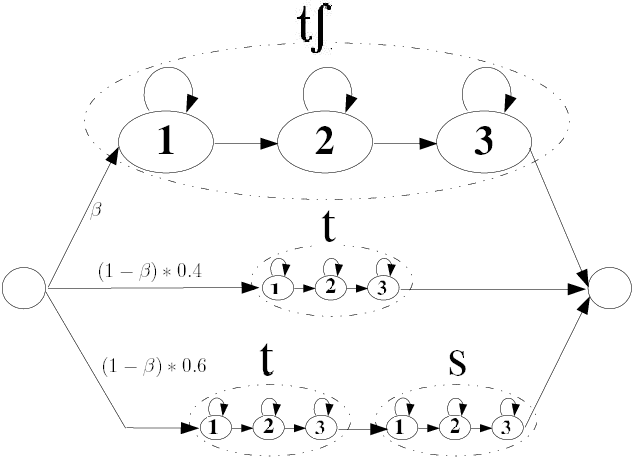



In this paper, we present several adaptation methods for non-native speech recognition. We have tested pronunciation modelling, MLLR and MAP non-native pronunciation adaptation and HMM models retraining on the HIWIRE foreign accented English speech database. The ``phonetic confusion'' scheme we have developed consists in associating to each spoken phone several sequences of confused phones. In our experiments, we have used different combinations of acoustic models representing the canonical and the foreign pronunciations: spoken and native models, models adapted to the non-native accent with MAP and MLLR. The joint use of pronunciation modelling and acoustic adaptation led to further improvements in recognition accuracy. The best combination of the above mentioned techniques resulted in a relative word error reduction ranging from 46% to 71%.