 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Knowledge via Neighborhood-Aware Optimal Transport for Low-Resource Hate Speech Detection
Oct 17, 2022
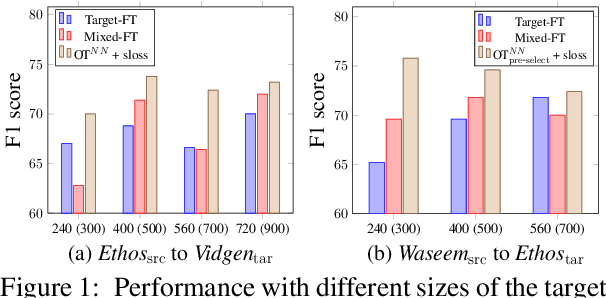

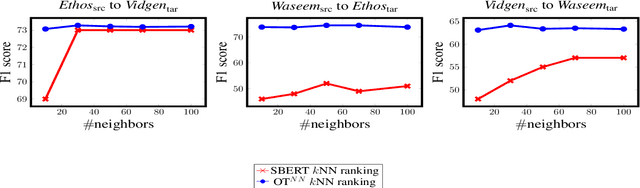
The concerning rise of hateful content on online platforms has increased the attention towards automatic hate speech detection, commonly formulated as a supervised classification task. State-of-the-art deep learning-based approaches usually require a substantial amount of labeled resources for training. However, annotating hate speech resources is expensive, time-consuming, and often harmful to the annotators. This creates a pressing need to transfer knowledge from the existing labeled resources to low-resource hate speech corpora with the goal of improving system performance. For this, neighborhood-based frameworks have been shown to be effective. However, they have limited flexibility. In our paper, we propose a novel training strategy that allows flexible modeling of the relative proximity of neighbors retrieved from a resource-rich corpus to learn the amount of transfer. In particular, we incorporate neighborhood information with Optimal Transport, which permits exploiting the geometry of the data embedding space. By aligning the joint embedding and label distributions of neighbors, we demonstrate substantial improvements over strong baselines, in low-resource scenarios, on different publicly available hate speech corpora.
Domain Classification-based Source-specific Term Penalization for Domain Adaptation in Hate-speech Detection
Sep 18, 2022
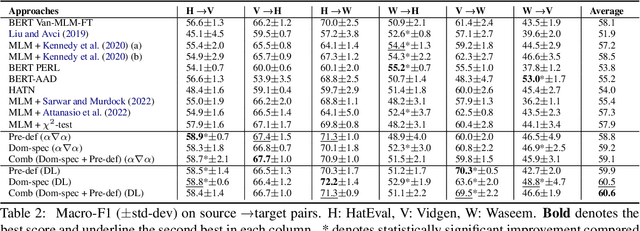


State-of-the-art approaches for hate-speech detection usually exhibit poor performance in out-of-domain settings. This occurs, typically, due to classifiers overemphasizing source-specific information that negatively impacts its domain invariance. Prior work has attempted to penalize terms related to hate-speech from manually curated lists using feature attribution methods, which quantify the importance assigned to input terms by the classifier when making a prediction. We, instead, propose a domain adaptation approach that automatically extracts and penalizes source-specific terms using a domain classifier, which learns to differentiate between domains, and feature-attribution scores for hate-speech classes, yielding consistent improvements in cross-domain evaluation.
Dynamically Refined Regularization for Improving Cross-corpora Hate Speech Detection
Mar 23, 2022
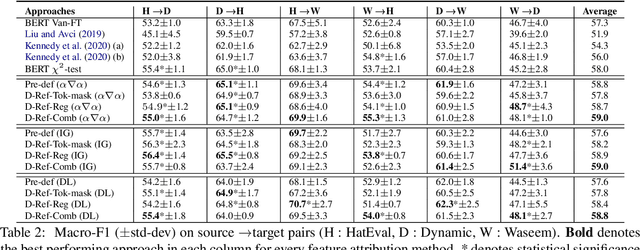
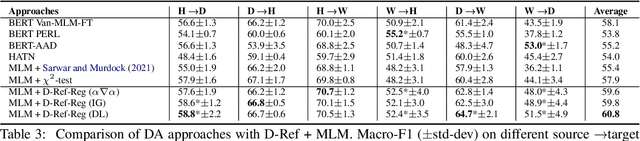

Hate speech classifiers exhibit substantial performance degradation when evaluated on datasets different from the source. This is due to learning spurious correlations between words that are not necessarily relevant to hateful language, and hate speech labels from the training corpus. Previous work has attempted to mitigate this problem by regularizing specific terms from pre-defined static dictionaries. While this has been demonstrated to improve the generalizability of classifiers, the coverage of such methods is limited and the dictionaries require regular manual updates from human experts. In this paper, we propose to automatically identify and reduce spurious correlations using attribution methods with dynamic refinement of the list of terms that need to be regularized during training. Our approach is flexible and improves the cross-corpora performance over previous work independently and in combination with pre-defined dictionaries.