 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
Dataset balancing can hurt model performance
Jun 30, 2023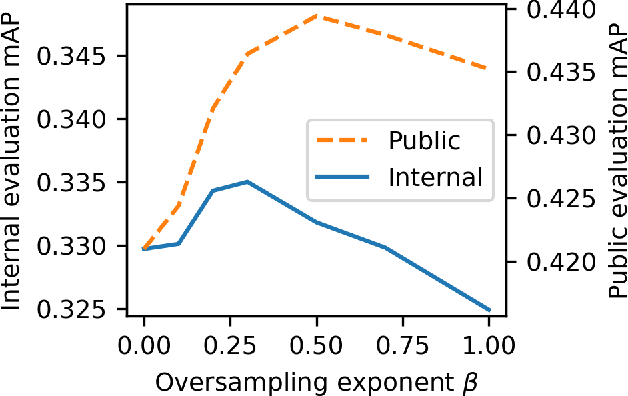
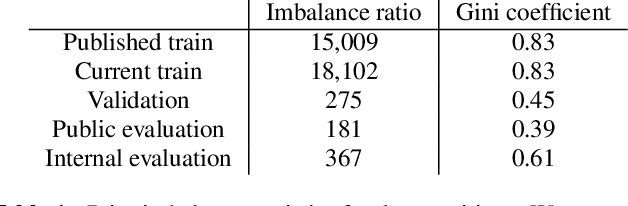

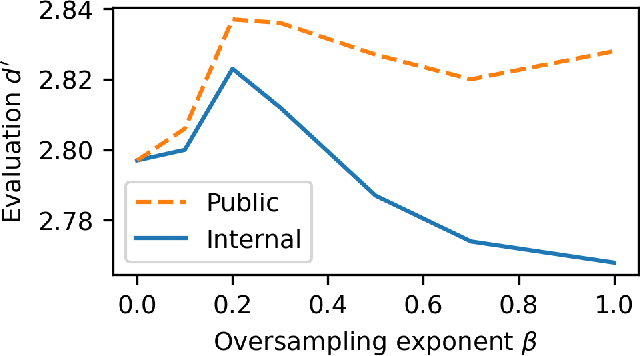
Machine learning from training data with a skewed distribution of examples per class can lead to models that favor performance on common classes at the expense of performance on rare ones. AudioSet has a very wide range of priors over its 527 sound event classes. Classification performance on AudioSet is usually evaluated by a simple average over per-class metrics, meaning that performance on rare classes is equal in importance to the performance on common ones. Several recent papers have used dataset balancing techniques to improve performance on AudioSet. We find, however, that while balancing improves performance on the public AudioSet evaluation data it simultaneously hurts performance on an unpublished evaluation set collected under the same conditions. By varying the degree of balancing, we show that its benefits are fragile and depend on the evaluation set. We also do not find evidence indicating that balancing improves rare class performance relative to common classes. We therefore caution against blind application of balancing, as well as against paying too much attention to small improvements on a public evaluation set.
* 5 pages, 3 figures, ICASSP 2023
Description and analysis of novelties introduced in DCASE Task 4 2022 on the baseline system
Oct 14, 2022
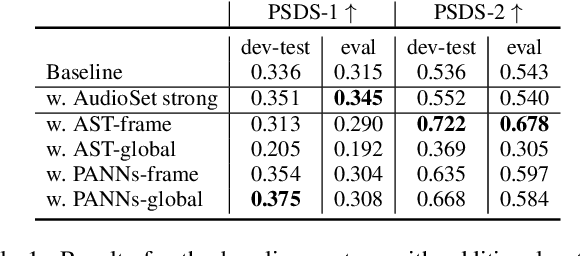
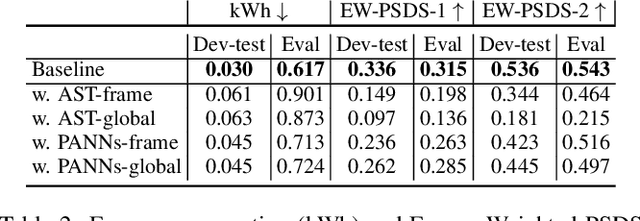
The aim of the Detection and Classification of Acoustic Scenes and Events Challenge Task 4 is to evaluate systems for the detection of sound events in domestic environments using an heterogeneous dataset. The systems need to be able to correctly detect the sound events present in a recorded audio clip, as well as localize the events in time. This year's task is a follow-up of DCASE 2021 Task 4, with some important novelties. The goal of this paper is to describe and motivate these new additions, and report an analysis of their impact on the baseline system. We introduced three main novelties: the use of external datasets, including recently released strongly annotated clips from Audioset, the possibility of leveraging pre-trained models, and a new energy consumption metric to raise awareness about the ecological impact of training sound events detectors. The results on the baseline system show that leveraging open-source pretrained on AudioSet improves the results significantly in terms of event classification but not in terms of event segmentation.
MuLan: A Joint Embedding of Music Audio and Natural Language
Aug 26, 2022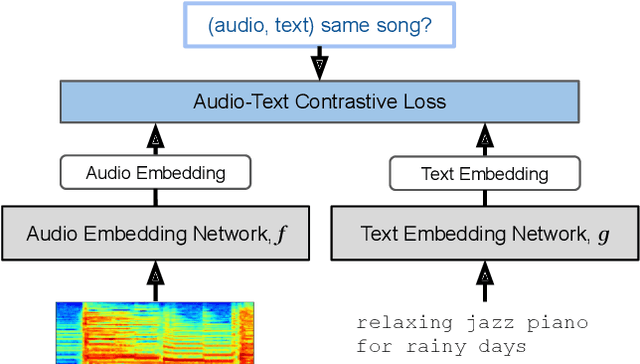


Music tagging and content-based retrieval systems have traditionally been constructed using pre-defined ontologies covering a rigid set of music attributes or text queries. This paper presents MuLan: a first attempt at a new generation of acoustic models that link music audio directly to unconstrained natural language music descriptions. MuLan takes the form of a two-tower, joint audio-text embedding model trained using 44 million music recordings (370K hours) and weakly-associated, free-form text annotations. Through its compatibility with a wide range of music genres and text styles (including conventional music tags), the resulting audio-text representation subsumes existing ontologies while graduating to true zero-shot functionalities. We demonstrate the versatility of the MuLan embeddings with a range of experiments including transfer learning, zero-shot music tagging, language understanding in the music domain, and cross-modal retrieval applications.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021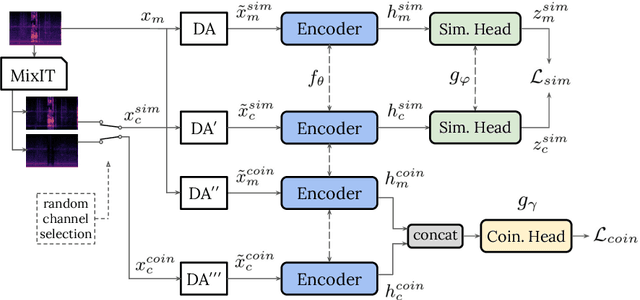



Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
Into the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds
Nov 02, 2020
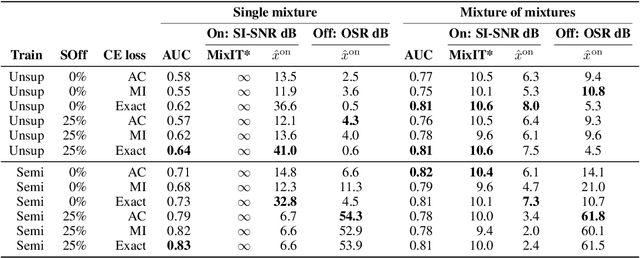
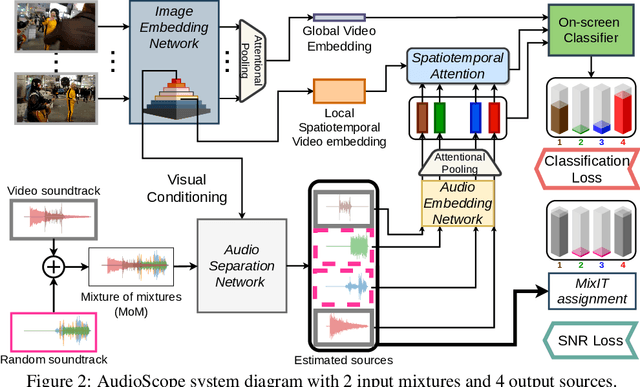
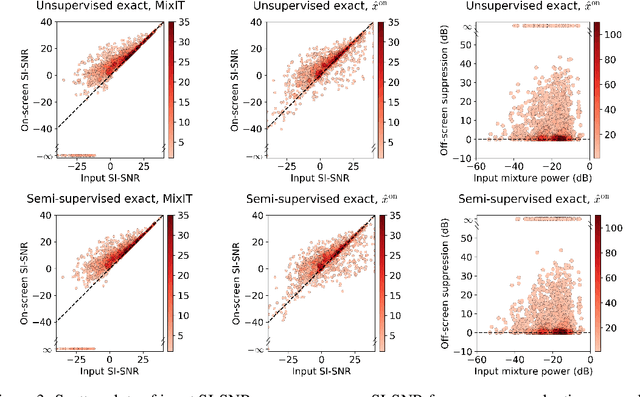
Recent progress in deep learning has enabled many advances in sound separation and visual scene understanding. However, extracting sound sources which are apparent in natural videos remains an open problem. In this work, we present AudioScope, a novel audio-visual sound separation framework that can be trained without supervision to isolate on-screen sound sources from real in-the-wild videos. Prior audio-visual separation work assumed artificial limitations on the domain of sound classes (e.g., to speech or music), constrained the number of sources, and required strong sound separation or visual segmentation labels. AudioScope overcomes these limitations, operating on an open domain of sounds, with variable numbers of sources, and without labels or prior visual segmentation. The training procedure for AudioScope uses mixture invariant training (MixIT) to separate synthetic mixtures of mixtures (MoMs) into individual sources, where noisy labels for mixtures are provided by an unsupervised audio-visual coincidence model. Using the noisy labels, along with attention between video and audio features, AudioScope learns to identify audio-visual similarity and to suppress off-screen sounds. We demonstrate the effectiveness of our approach using a dataset of video clips extracted from open-domain YFCC100m video data. This dataset contains a wide diversity of sound classes recorded in unconstrained conditions, making the application of previous methods unsuitable. For evaluation and semi-supervised experiments, we collected human labels for presence of on-screen and off-screen sounds on a small subset of clips.
Addressing Missing Labels in Large-scale Sound Event Recognition using a Teacher-student Framework with Loss Masking
May 02, 2020
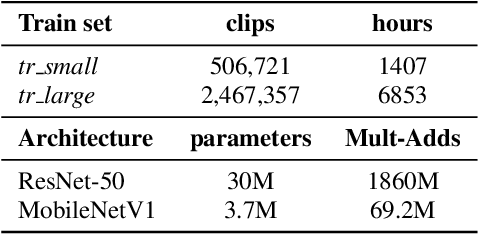
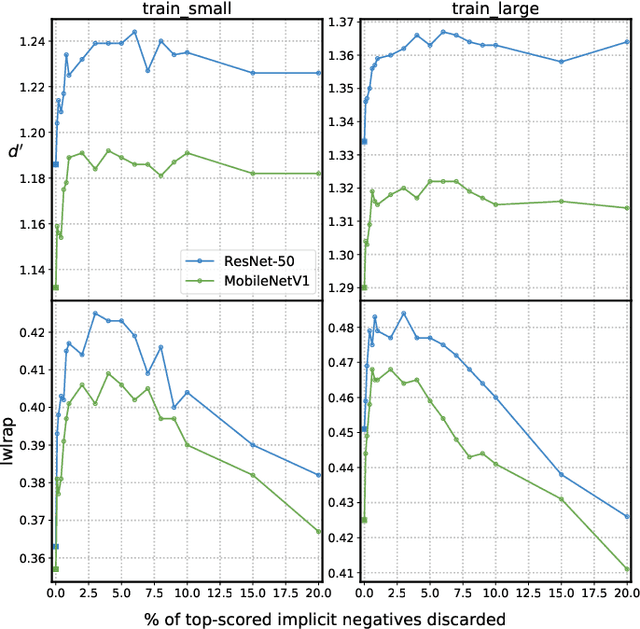
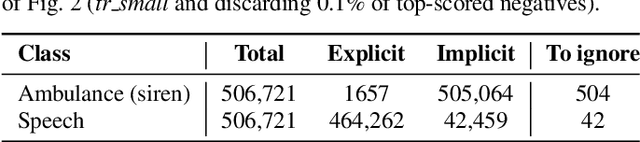
The study of label noise in sound event recognition has recently gained attention with the advent of larger and noisier datasets. This work addresses the problem of missing labels, one of the big weaknesses of large audio datasets, and one of the most conspicuous issues for AudioSet. We propose a simple and model-agnostic method based on a teacher-student framework with loss masking to first identify the most critical missing label candidates, and then ignore their contribution during the learning process. We find that a simple optimisation of the training label set improves recognition performance without additional compute. We discover that most of the improvement comes from ignoring a critical tiny portion of the missing labels. We also show that the damage done by missing labels is larger as the training set gets smaller, yet it can still be observed even when training with massive amounts of audio. We believe these insights can generalize to other large-scale datasets.
Improving Universal Sound Separation Using Sound Classification
Nov 18, 2019
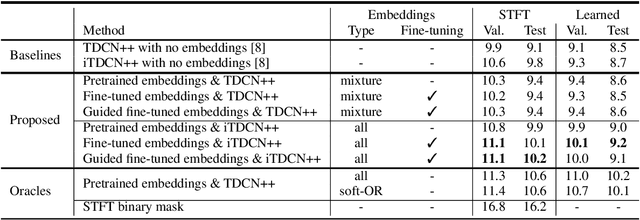


Deep learning approaches have recently achieved impressive performance on both audio source separation and sound classification. Most audio source separation approaches focus only on separating sources belonging to a restricted domain of source classes, such as speech and music. However, recent work has demonstrated the possibility of "universal sound separation", which aims to separate acoustic sources from an open domain, regardless of their class. In this paper, we utilize the semantic information learned by sound classifier networks trained on a vast amount of diverse sounds to improve universal sound separation. In particular, we show that semantic embeddings extracted from a sound classifier can be used to condition a separation network, providing it with useful additional information. This approach is especially useful in an iterative setup, where source estimates from an initial separation stage and their corresponding classifier-derived embeddings are fed to a second separation network. By performing a thorough hyperparameter search consisting of over a thousand experiments, we find that classifier embeddings from clean sources provide nearly one dB of SNR gain, and our best iterative models achieve a significant fraction of this oracle performance, establishing a new state-of-the-art for universal sound separation.
Coincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision
Nov 14, 2019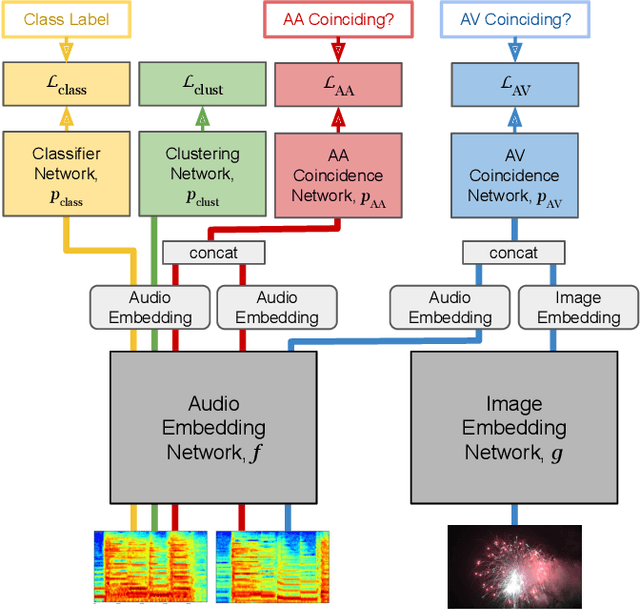
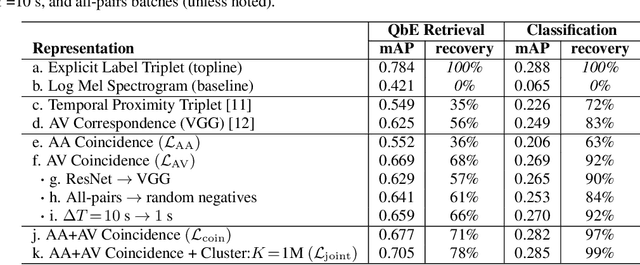
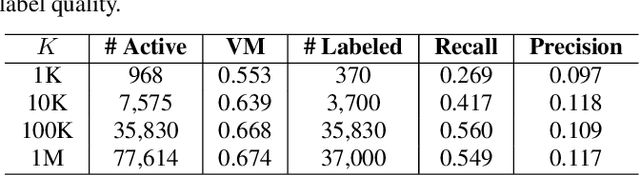
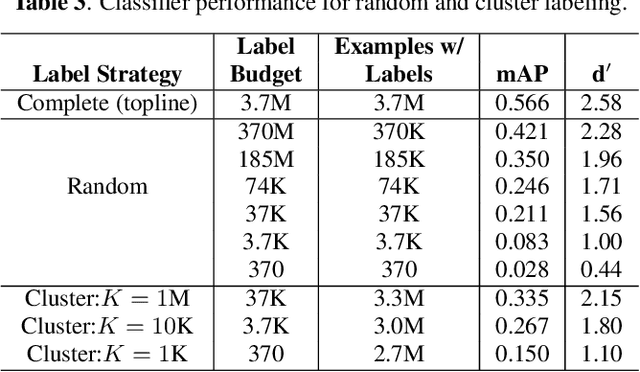
Humans do not acquire perceptual abilities in the way we train machines. While machine learning algorithms typically operate on large collections of randomly-chosen, explicitly-labeled examples, human acquisition relies more heavily on multimodal unsupervised learning (as infants) and active learning (as children). With this motivation, we present a learning framework for sound representation and recognition that combines (i) a self-supervised objective based on a general notion of unimodal and cross-modal coincidence, (ii) a clustering objective that reflects our need to impose categorical structure on our experiences, and (iii) a cluster-based active learning procedure that solicits targeted weak supervision to consolidate categories into relevant semantic classes. By training a combined sound embedding/clustering/classification network according to these criteria, we achieve a new state-of-the-art unsupervised audio representation and demonstrate up to a 20-fold reduction in the number of labels required to reach a desired classification performance.
Audio tagging with noisy labels and minimal supervision
Jul 14, 2019
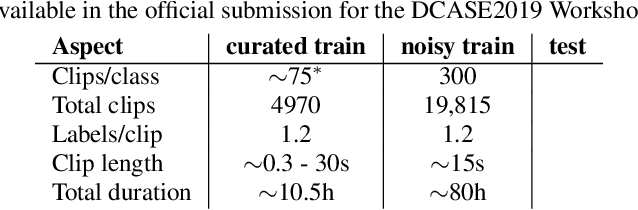


This paper introduces Task 2 of the DCASE2019 Challenge, titled "Audio tagging with noisy labels and minimal supervision". This task was hosted on the Kaggle platform as "Freesound Audio Tagging 2019". The task evaluates systems for multi-label audio tagging using a large set of noisy-labeled data, and a much smaller set of manually-labeled data, under a large vocabulary setting of 80 everyday sound classes. In addition, the proposed dataset poses an acoustic mismatch problem between the noisy train set and the test set due to the fact that they come from different web audio sources. This can correspond to a realistic scenario given by the difficulty in gathering large amounts of manually labeled data. We present the task setup, the FSDKaggle2019 dataset prepared for this scientific evaluation, and a baseline system consisting of a convolutional neural network. All these resources are freely available.