 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset balancing can hurt model performance
Paper and Code
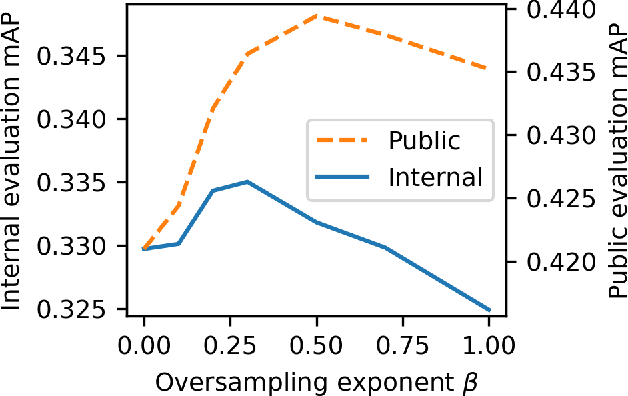
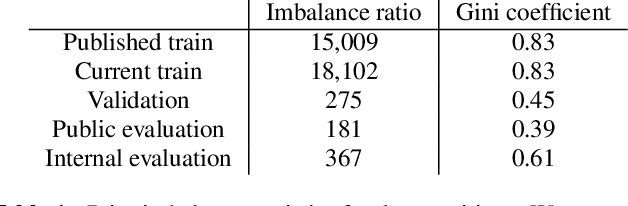

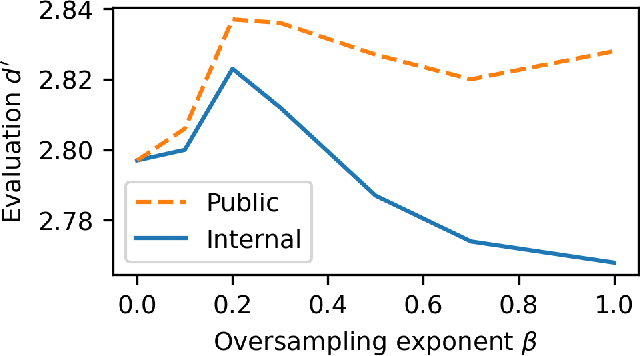
Machine learning from training data with a skewed distribution of examples per class can lead to models that favor performance on common classes at the expense of performance on rare ones. AudioSet has a very wide range of priors over its 527 sound event classes. Classification performance on AudioSet is usually evaluated by a simple average over per-class metrics, meaning that performance on rare classes is equal in importance to the performance on common ones. Several recent papers have used dataset balancing techniques to improve performance on AudioSet. We find, however, that while balancing improves performance on the public AudioSet evaluation data it simultaneously hurts performance on an unpublished evaluation set collected under the same conditions. By varying the degree of balancing, we show that its benefits are fragile and depend on the evaluation set. We also do not find evidence indicating that balancing improves rare class performance relative to common classes. We therefore caution against blind application of balancing, as well as against paying too much attention to small improvements on a public evaluation set.