 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
Dataset balancing can hurt model performance
Jun 30, 2023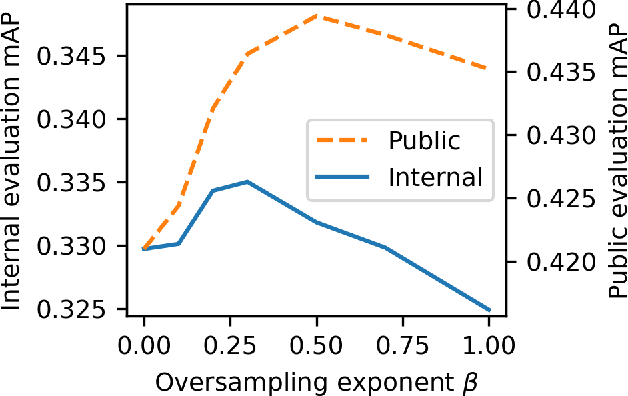
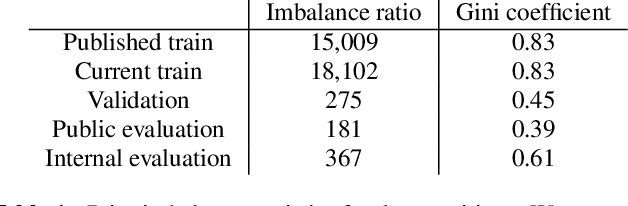

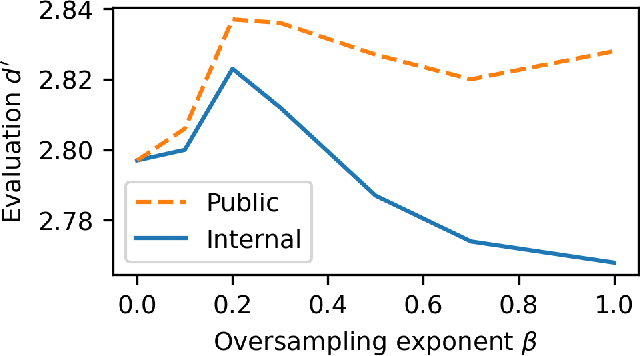
Machine learning from training data with a skewed distribution of examples per class can lead to models that favor performance on common classes at the expense of performance on rare ones. AudioSet has a very wide range of priors over its 527 sound event classes. Classification performance on AudioSet is usually evaluated by a simple average over per-class metrics, meaning that performance on rare classes is equal in importance to the performance on common ones. Several recent papers have used dataset balancing techniques to improve performance on AudioSet. We find, however, that while balancing improves performance on the public AudioSet evaluation data it simultaneously hurts performance on an unpublished evaluation set collected under the same conditions. By varying the degree of balancing, we show that its benefits are fragile and depend on the evaluation set. We also do not find evidence indicating that balancing improves rare class performance relative to common classes. We therefore caution against blind application of balancing, as well as against paying too much attention to small improvements on a public evaluation set.
* 5 pages, 3 figures, ICASSP 2023
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021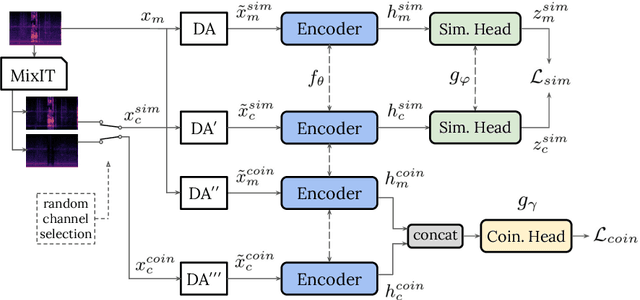



Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
Addressing Missing Labels in Large-scale Sound Event Recognition using a Teacher-student Framework with Loss Masking
May 02, 2020
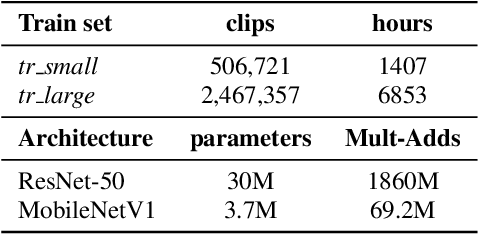
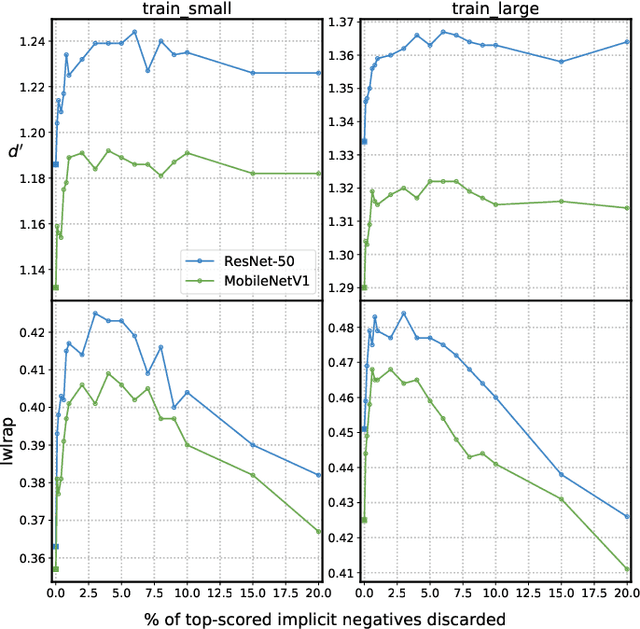
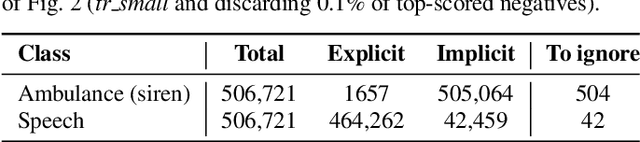
The study of label noise in sound event recognition has recently gained attention with the advent of larger and noisier datasets. This work addresses the problem of missing labels, one of the big weaknesses of large audio datasets, and one of the most conspicuous issues for AudioSet. We propose a simple and model-agnostic method based on a teacher-student framework with loss masking to first identify the most critical missing label candidates, and then ignore their contribution during the learning process. We find that a simple optimisation of the training label set improves recognition performance without additional compute. We discover that most of the improvement comes from ignoring a critical tiny portion of the missing labels. We also show that the damage done by missing labels is larger as the training set gets smaller, yet it can still be observed even when training with massive amounts of audio. We believe these insights can generalize to other large-scale datasets.
Coincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision
Nov 14, 2019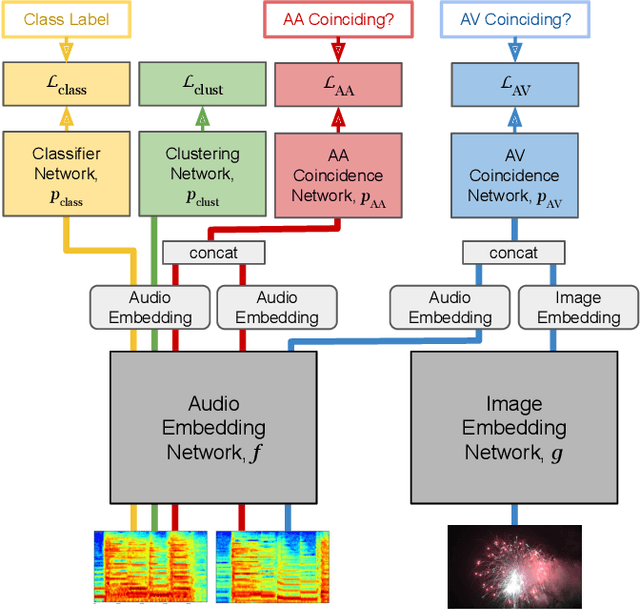
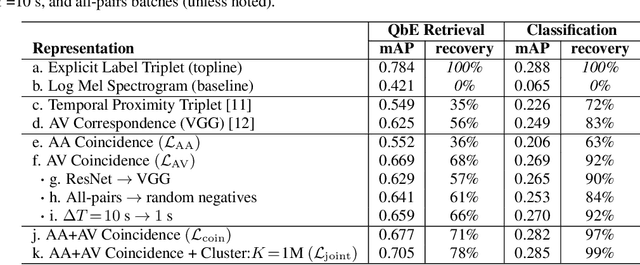
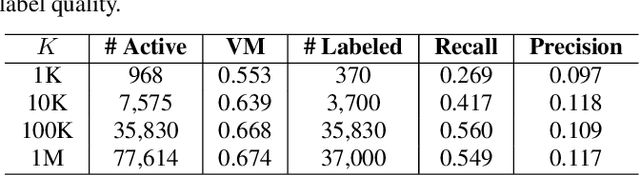
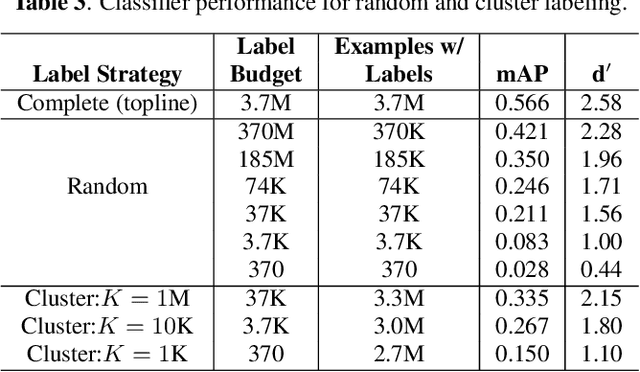
Humans do not acquire perceptual abilities in the way we train machines. While machine learning algorithms typically operate on large collections of randomly-chosen, explicitly-labeled examples, human acquisition relies more heavily on multimodal unsupervised learning (as infants) and active learning (as children). With this motivation, we present a learning framework for sound representation and recognition that combines (i) a self-supervised objective based on a general notion of unimodal and cross-modal coincidence, (ii) a clustering objective that reflects our need to impose categorical structure on our experiences, and (iii) a cluster-based active learning procedure that solicits targeted weak supervision to consolidate categories into relevant semantic classes. By training a combined sound embedding/clustering/classification network according to these criteria, we achieve a new state-of-the-art unsupervised audio representation and demonstrate up to a 20-fold reduction in the number of labels required to reach a desired classification performance.
Unsupervised Learning of Semantic Audio Representations
Nov 06, 2017
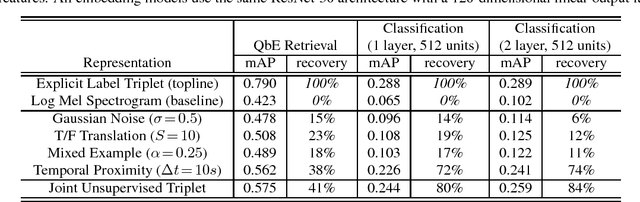
Even in the absence of any explicit semantic annotation, vast collections of audio recordings provide valuable information for learning the categorical structure of sounds. We consider several class-agnostic semantic constraints that apply to unlabeled nonspeech audio: (i) noise and translations in time do not change the underlying sound category, (ii) a mixture of two sound events inherits the categories of the constituents, and (iii) the categories of events in close temporal proximity are likely to be the same or related. Without labels to ground them, these constraints are incompatible with classification loss functions. However, they may still be leveraged to identify geometric inequalities needed for triplet loss-based training of convolutional neural networks. The result is low-dimensional embeddings of the input spectrograms that recover 41% and 84% of the performance of their fully-supervised counterparts when applied to downstream query-by-example sound retrieval and sound event classification tasks, respectively. Moreover, in limited-supervision settings, our unsupervised embeddings double the state-of-the-art classification performance.
CNN Architectures for Large-Scale Audio Classification
Jan 10, 2017
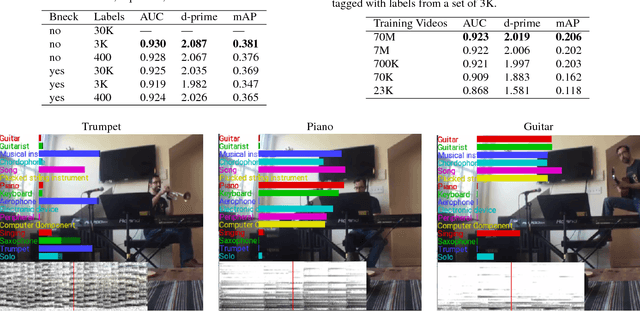
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.