 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Jan 05, 2019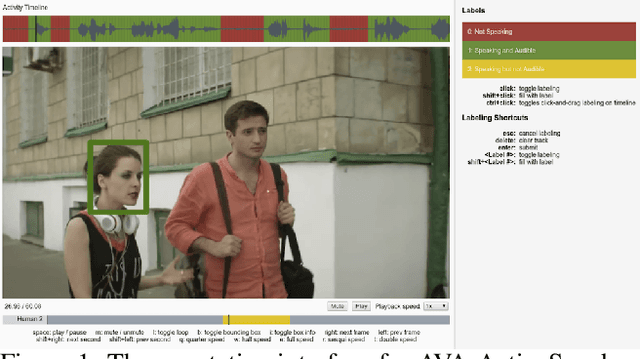
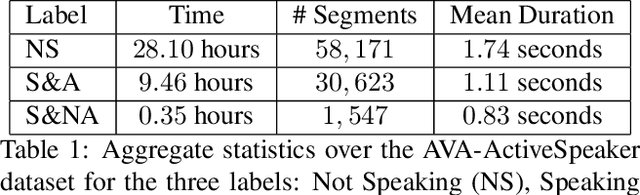

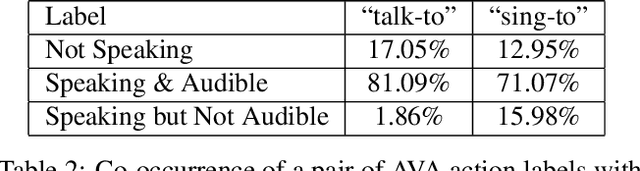
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled audio-visual dataset for this task has constrained algorithm evaluations with respect to data diversity, environments, and accuracy. This has made comparisons and improvements difficult. In this paper, we present the AVA Active Speaker detection dataset (AVA-ActiveSpeaker) that will be released publicly to facilitate algorithm development and enable comparisons. The dataset contains temporally labeled face tracks in video, where each face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tracks, and the corresponding audio. We also present a new audio-visual approach for active speaker detection, and analyze its performance, demonstrating both its strength and the contributions of the dataset.
Putting a Face to the Voice: Fusing Audio and Visual Signals Across a Video to Determine Speakers
May 31, 2017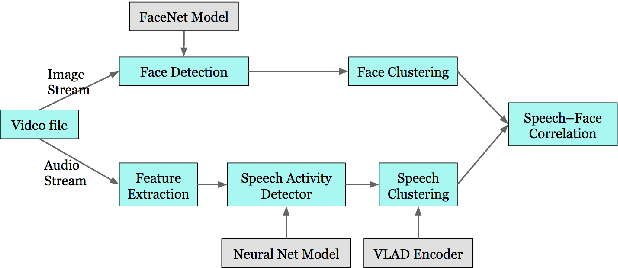
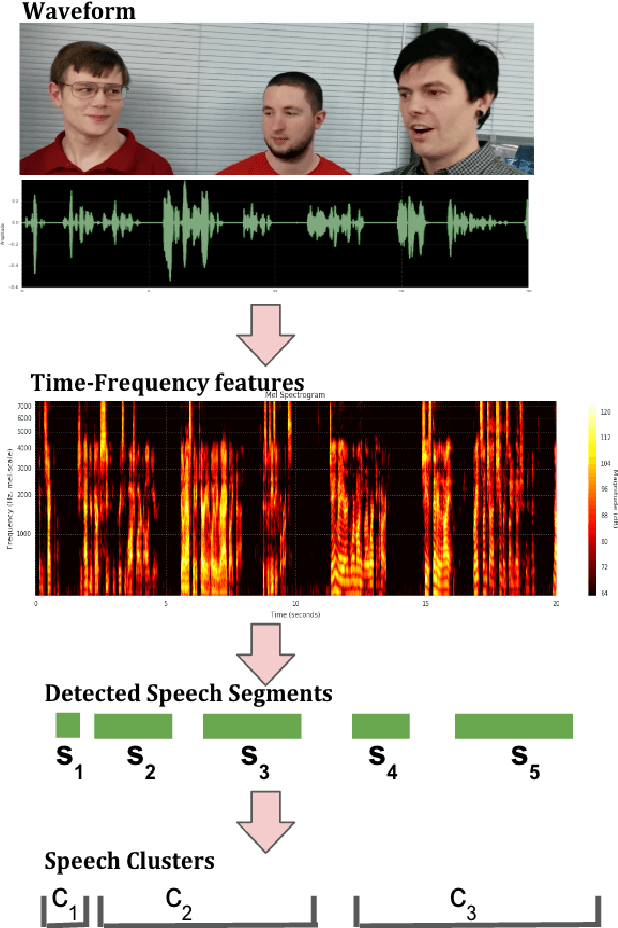
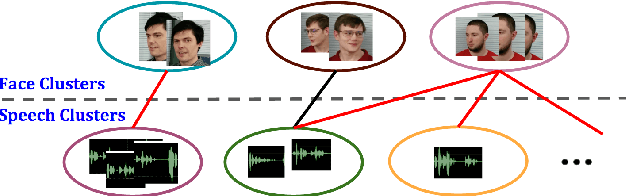
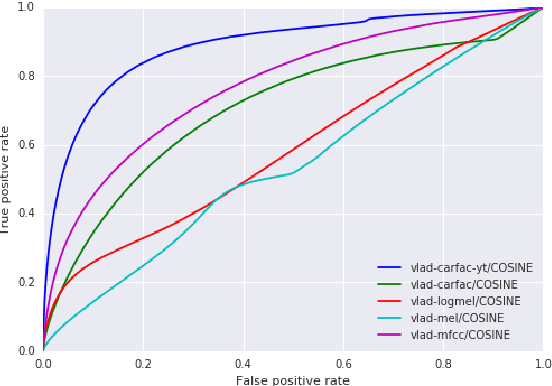
In this paper, we present a system that associates faces with voices in a video by fusing information from the audio and visual signals. The thesis underlying our work is that an extremely simple approach to generating (weak) speech clusters can be combined with visual signals to effectively associate faces and voices by aggregating statistics across a video. This approach does not need any training data specific to this task and leverages the natural coherence of information in the audio and visual streams. It is particularly applicable to tracking speakers in videos on the web where a priori information about the environment (e.g., number of speakers, spatial signals for beamforming) is not available. We performed experiments on a real-world dataset using this analysis framework to determine the speaker in a video. Given a ground truth labeling determined by human rater consensus, our approach had ~71% accuracy.
CNN Architectures for Large-Scale Audio Classification
Jan 10, 2017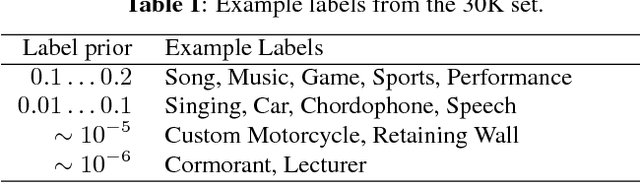
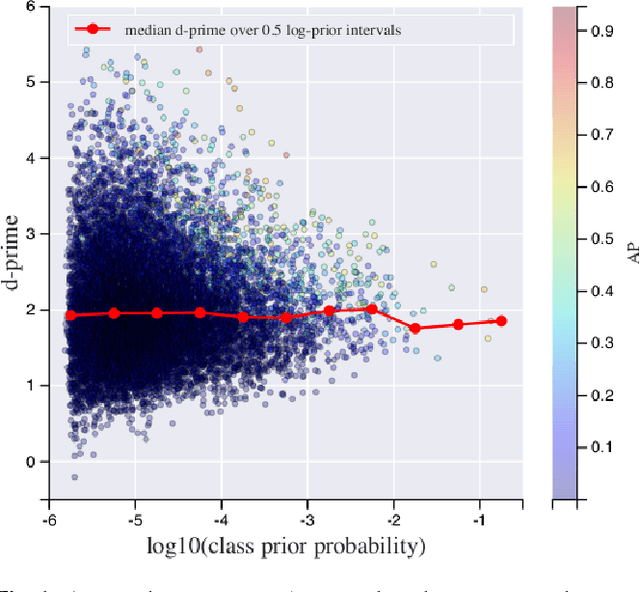
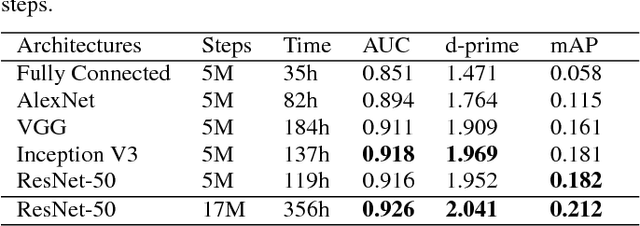
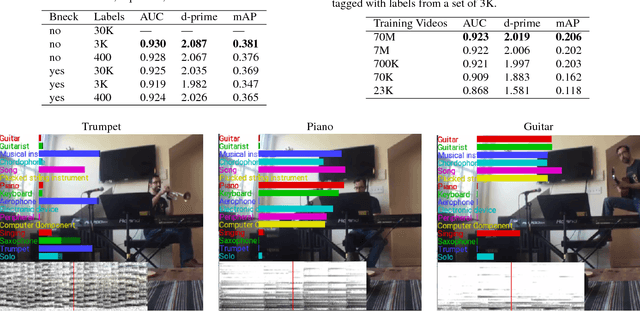
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.
Plagiarism Detection in Polyphonic Music using Monaural Signal Separation
Feb 27, 2015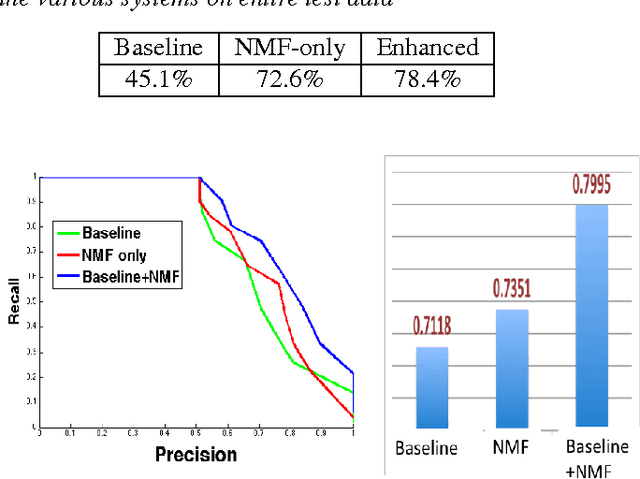
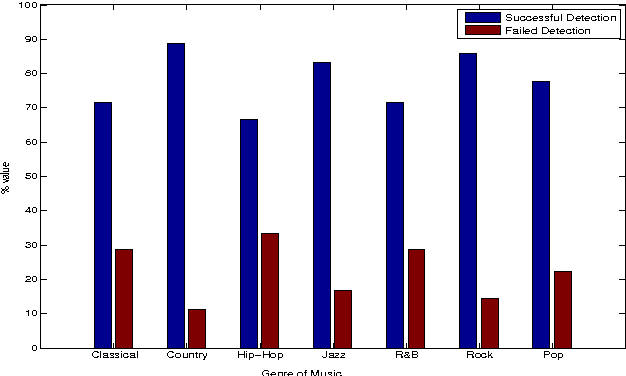
Given the large number of new musical tracks released each year, automated approaches to plagiarism detection are essential to help us track potential violations of copyright. Most current approaches to plagiarism detection are based on musical similarity measures, which typically ignore the issue of polyphony in music. We present a novel feature space for audio derived from compositional modelling techniques, commonly used in signal separation, that provides a mechanism to account for polyphony without incurring an inordinate amount of computational overhead. We employ this feature representation in conjunction with traditional audio feature representations in a classification framework which uses an ensemble of distance features to characterize pairs of songs as being plagiarized or not. Our experiments on a database of about 3000 musical track pairs show that the new feature space characterization produces significant improvements over standard baselines.
* Preprint version