 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Jan 05, 2019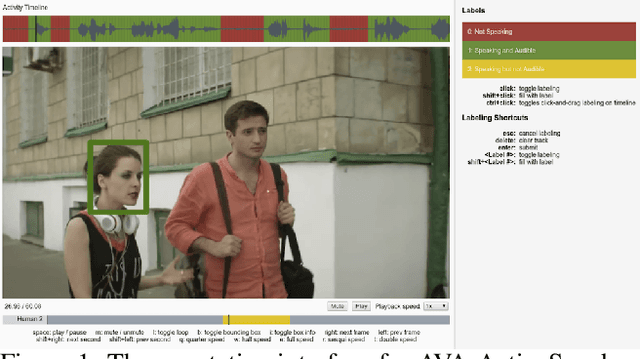
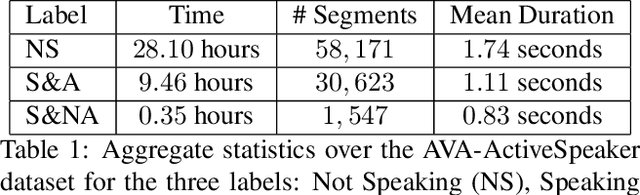

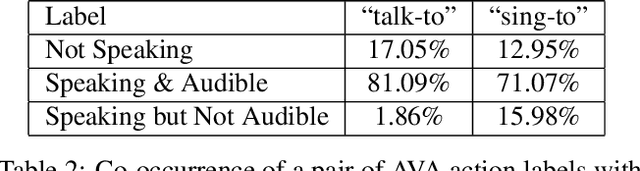
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled audio-visual dataset for this task has constrained algorithm evaluations with respect to data diversity, environments, and accuracy. This has made comparisons and improvements difficult. In this paper, we present the AVA Active Speaker detection dataset (AVA-ActiveSpeaker) that will be released publicly to facilitate algorithm development and enable comparisons. The dataset contains temporally labeled face tracks in video, where each face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tracks, and the corresponding audio. We also present a new audio-visual approach for active speaker detection, and analyze its performance, demonstrating both its strength and the contributions of the dataset.
Modeling Uncertainty with Hedged Instance Embedding
Oct 19, 2018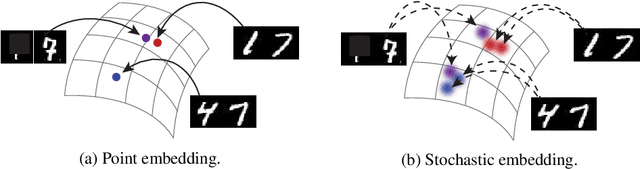
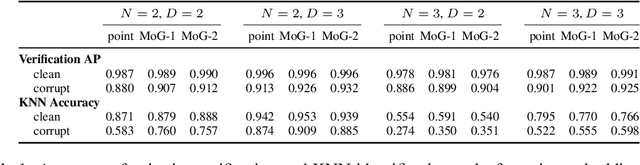
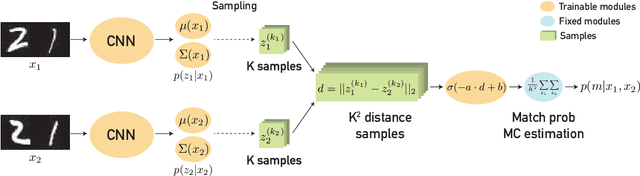
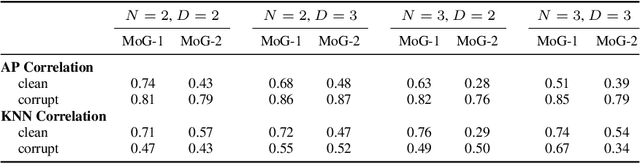
Instance embeddings are an efficient and versatile image representation that facilitates applications like recognition, verification, retrieval, and clustering. Many metric learning methods represent the input as a single point in the embedding space. Often the distance between points is used as a proxy for match confidence. However, this can fail to represent uncertainty arising when the input is ambiguous, e.g., due to occlusion or blurriness. This work addresses this issue and explicitly models the uncertainty by hedging the location of each input in the embedding space. We introduce the hedged instance embedding (HIB) in which embeddings are modeled as random variables and the model is trained under the variational information bottleneck principle. Empirical results on our new N-digit MNIST dataset show that our method leads to the desired behavior of hedging its bets across the embedding space upon encountering ambiguous inputs. This results in improved performance for image matching and classification tasks, more structure in the learned embedding space, and an ability to compute a per-exemplar uncertainty measure that is correlated with downstream performance.