 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrigami-based Zygote structure enables pluripotent shape-transforming deployable structure
Aug 08, 2022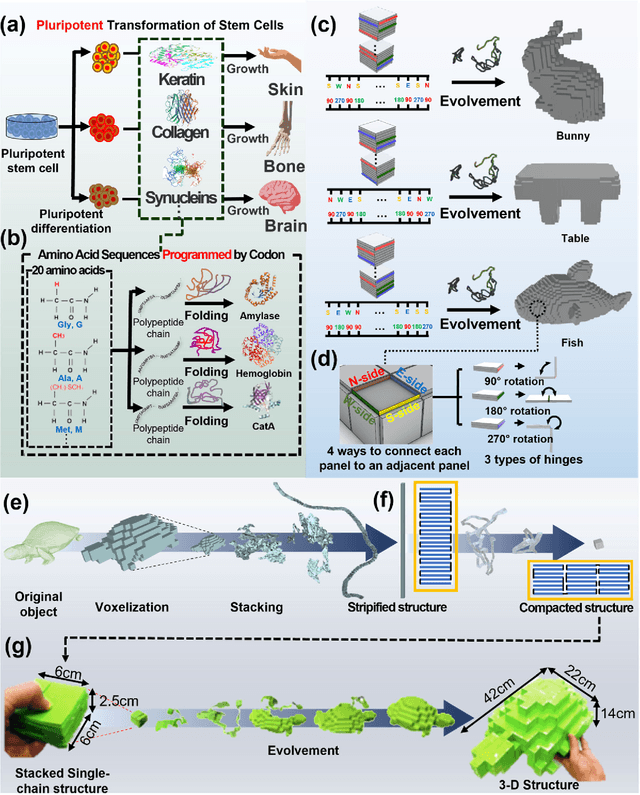


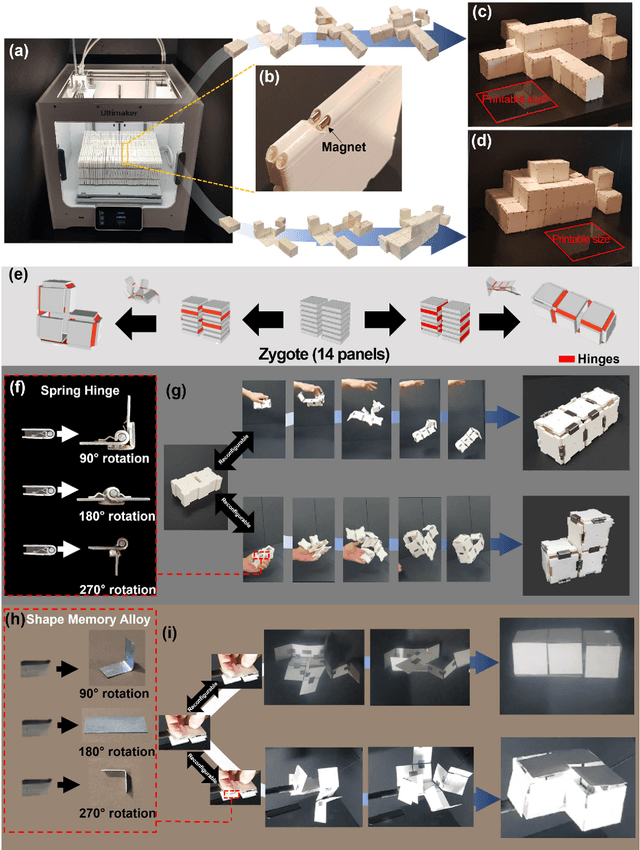
We propose an algorithmic framework of a pluripotent structure evolving from a simple compact structure into diverse complex 3-D structures for designing the shape transformable, reconfigurable, and deployable structures and robots. Our algorithmic approach suggests a way of transforming a compact structure consisting of uniform building blocks into a large, desired 3-D shape. Analogous to the pluripotent stem cells that can grow into a preprogrammed shape according to coded information, which we call DNA, compactly stacked panels named the zygote structure can evolve into arbitrary 3-D structures by programming their connection path. Our stacking algorithm obtains this coded sequence by inversely stacking the voxelized surface of the desired structure into a tree. Applying the connection path obtained by the stacking algorithm, the compactly stacked panels named the zygote structure can be deployed into diverse large 3-D structures. We conceptually demonstrated our pluripotent evolving structure by energy releasing commercial spring hinges and thermally actuated shape memory alloy (SMA) hinges, respectively. We also show that the proposed concept enables the fabrication of large structures in a significantly smaller workspace.
AVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Jan 05, 2019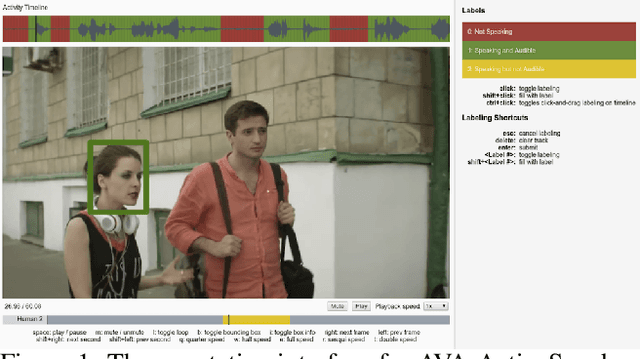
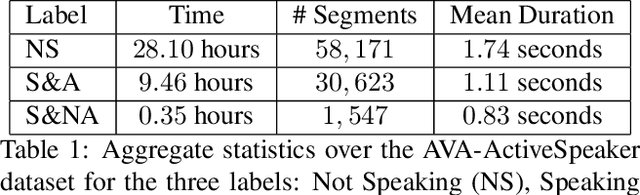

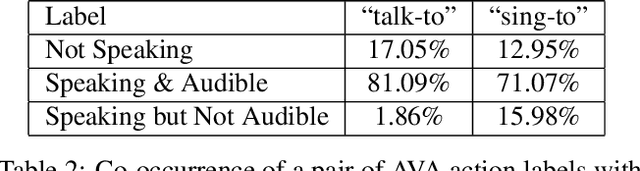
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled audio-visual dataset for this task has constrained algorithm evaluations with respect to data diversity, environments, and accuracy. This has made comparisons and improvements difficult. In this paper, we present the AVA Active Speaker detection dataset (AVA-ActiveSpeaker) that will be released publicly to facilitate algorithm development and enable comparisons. The dataset contains temporally labeled face tracks in video, where each face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tracks, and the corresponding audio. We also present a new audio-visual approach for active speaker detection, and analyze its performance, demonstrating both its strength and the contributions of the dataset.