 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers
May 21, 2024



We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models. We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video. Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Open-Vocabulary Temporal Action Detection with Off-the-Shelf Image-Text Features
Dec 20, 2022Detecting actions in untrimmed videos should not be limited to a small, closed set of classes. We present a simple, yet effective strategy for open-vocabulary temporal action detection utilizing pretrained image-text co-embeddings. Despite being trained on static images rather than videos, we show that image-text co-embeddings enable openvocabulary performance competitive with fully-supervised models. We show that the performance can be further improved by ensembling the image-text features with features encoding local motion, like optical flow based features, or other modalities, like audio. In addition, we propose a more reasonable open-vocabulary evaluation setting for the ActivityNet data set, where the category splits are based on similarity rather than random assignment.
What's in a Caption? Dataset-Specific Linguistic Diversity and Its Effect on Visual Description Models and Metrics
May 12, 2022
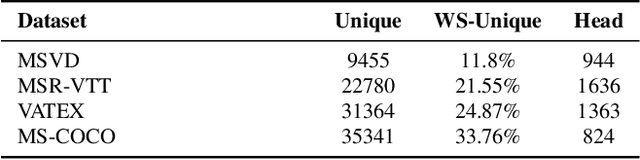
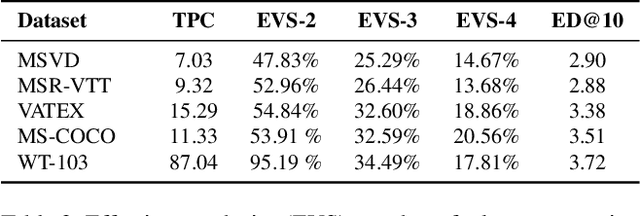
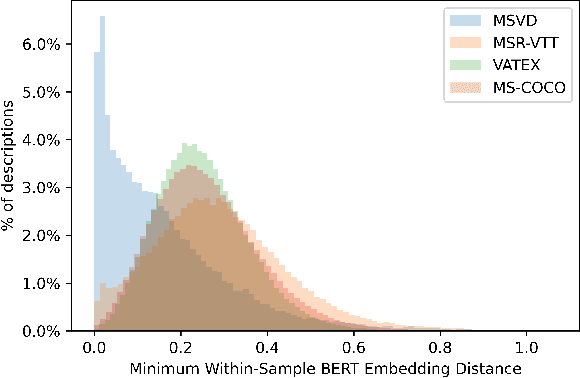
While there have been significant gains in the field of automated video description, the generalization performance of automated description models to novel domains remains a major barrier to using these systems in the real world. Most visual description methods are known to capture and exploit patterns in the training data leading to evaluation metric increases, but what are those patterns? In this work, we examine several popular visual description datasets, and capture, analyze, and understand the dataset-specific linguistic patterns that models exploit but do not generalize to new domains. At the token level, sample level, and dataset level, we find that caption diversity is a major driving factor behind the generation of generic and uninformative captions. We further show that state-of-the-art models even outperform held-out ground truth captions on modern metrics, and that this effect is an artifact of linguistic diversity in datasets. Understanding this linguistic diversity is key to building strong captioning models, we recommend several methods and approaches for maintaining diversity in the collection of new data, and dealing with the consequences of limited diversity when using current models and metrics.
Learning Audio-Video Modalities from Image Captions
Apr 01, 2022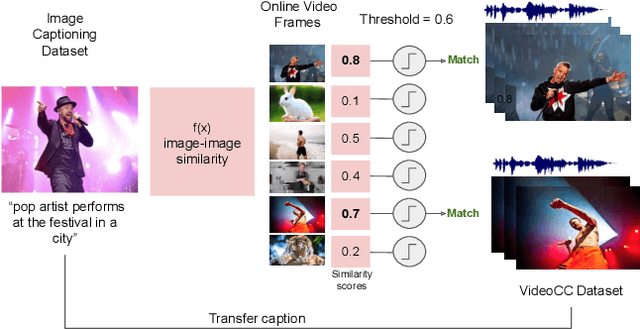
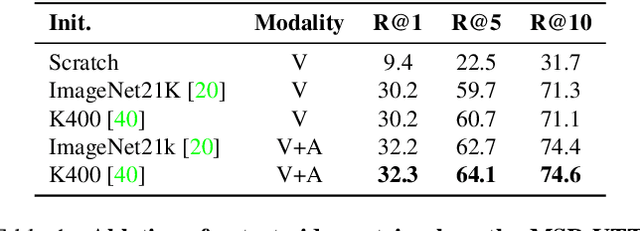

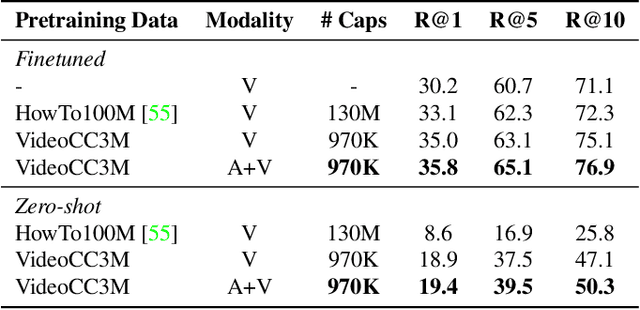
A major challenge in text-video and text-audio retrieval is the lack of large-scale training data. This is unlike image-captioning, where datasets are in the order of millions of samples. To close this gap we propose a new video mining pipeline which involves transferring captions from image captioning datasets to video clips with no additional manual effort. Using this pipeline, we create a new large-scale, weakly labelled audio-video captioning dataset consisting of millions of paired clips and captions. We show that training a multimodal transformed based model on this data achieves competitive performance on video retrieval and video captioning, matching or even outperforming HowTo100M pretraining with 20x fewer clips. We also show that our mined clips are suitable for text-audio pretraining, and achieve state of the art results for the task of audio retrieval.
Optical Mouse: 3D Mouse Pose From Single-View Video
Jun 17, 2021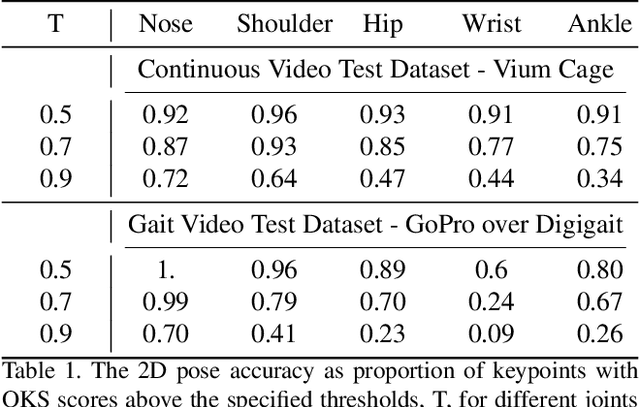

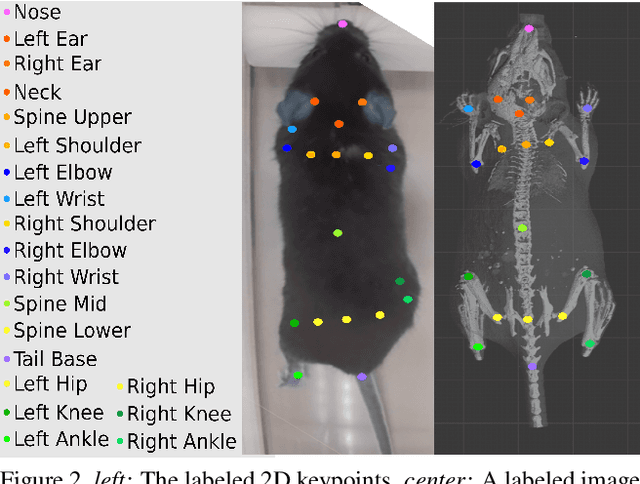
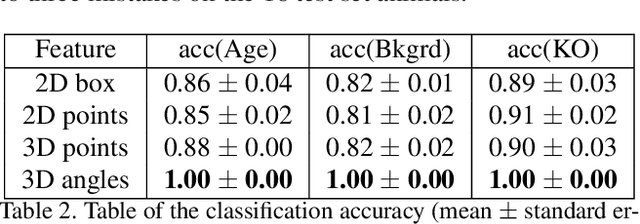
We present a method to infer the 3D pose of mice, including the limbs and feet, from monocular videos. Many human clinical conditions and their corresponding animal models result in abnormal motion, and accurately measuring 3D motion at scale offers insights into health. The 3D poses improve classification of health-related attributes over 2D representations. The inferred poses are accurate enough to estimate stride length even when the feet are mostly occluded. This method could be applied as part of a continuous monitoring system to non-invasively measure animal health.
Dueling Decoders: Regularizing Variational Autoencoder Latent Spaces
May 17, 2019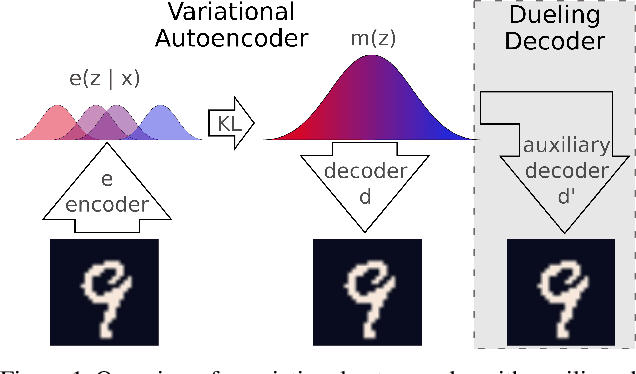
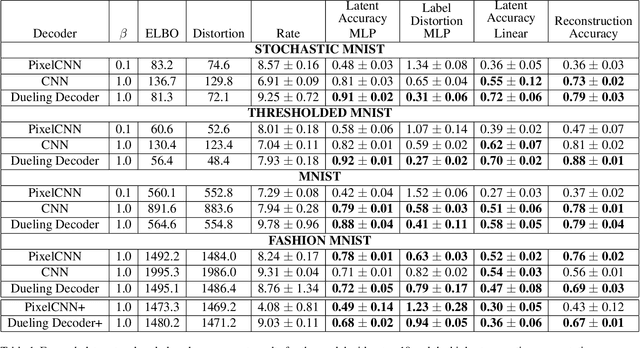

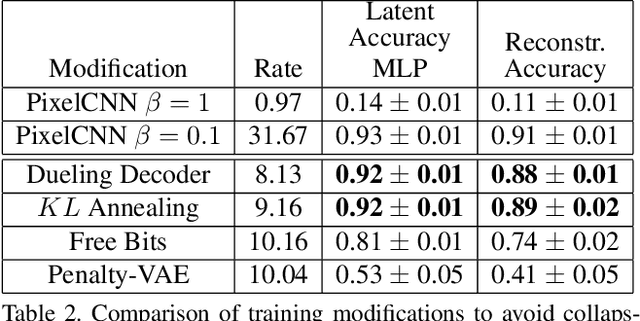
Variational autoencoders learn unsupervised data representations, but these models frequently converge to minima that fail to preserve meaningful semantic information. For example, variational autoencoders with autoregressive decoders often collapse into autodecoders, where they learn to ignore the encoder input. In this work, we demonstrate that adding an auxiliary decoder to regularize the latent space can prevent this collapse, but successful auxiliary decoding tasks are domain dependent. Auxiliary decoders can increase the amount of semantic information encoded in the latent space and visible in the reconstructions. The semantic information in the variational autoencoder's representation is only weakly correlated with its rate, distortion, or evidence lower bound. Compared to other popular strategies that modify the training objective, our regularization of the latent space generally increased the semantic information content.
Rethinking the Faster R-CNN Architecture for Temporal Action Localization
Apr 20, 2018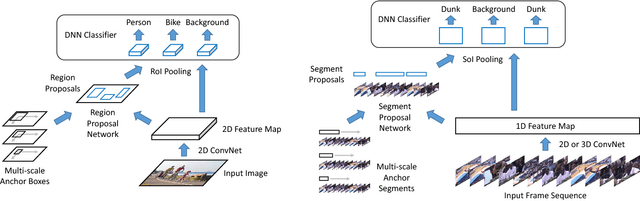
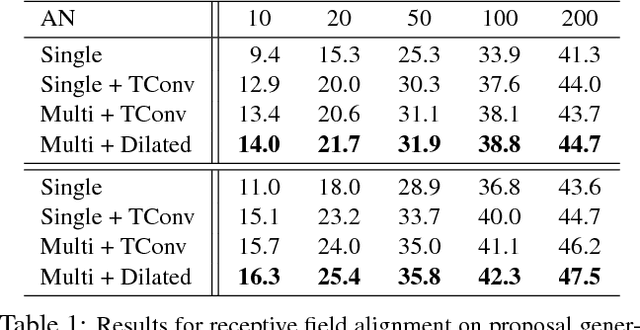
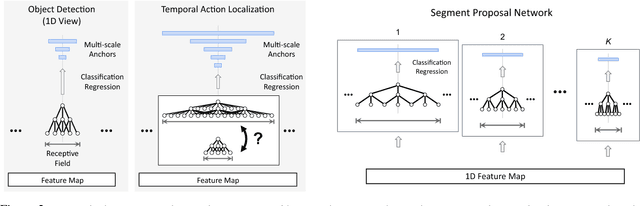
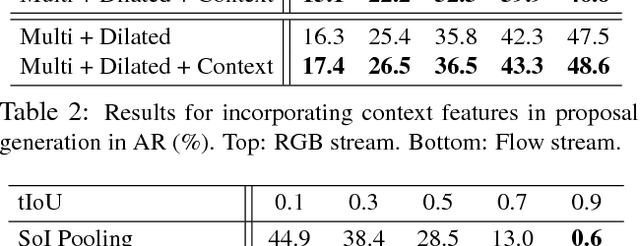
We propose TAL-Net, an improved approach to temporal action localization in video that is inspired by the Faster R-CNN object detection framework. TAL-Net addresses three key shortcomings of existing approaches: (1) we improve receptive field alignment using a multi-scale architecture that can accommodate extreme variation in action durations; (2) we better exploit the temporal context of actions for both proposal generation and action classification by appropriately extending receptive fields; and (3) we explicitly consider multi-stream feature fusion and demonstrate that fusing motion late is important. We achieve state-of-the-art performance for both action proposal and localization on THUMOS'14 detection benchmark and competitive performance on ActivityNet challenge.
Instance Embedding Transfer to Unsupervised Video Object Segmentation
Feb 27, 2018

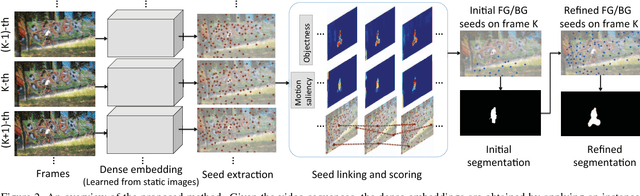

We propose a method for unsupervised video object segmentation by transferring the knowledge encapsulated in image-based instance embedding networks. The instance embedding network produces an embedding vector for each pixel that enables identifying all pixels belonging to the same object. Though trained on static images, the instance embeddings are stable over consecutive video frames, which allows us to link objects together over time. Thus, we adapt the instance networks trained on static images to video object segmentation and incorporate the embeddings with objectness and optical flow features, without model retraining or online fine-tuning. The proposed method outperforms state-of-the-art unsupervised segmentation methods in the DAVIS dataset and the FBMS dataset.
CNN Architectures for Large-Scale Audio Classification
Jan 10, 2017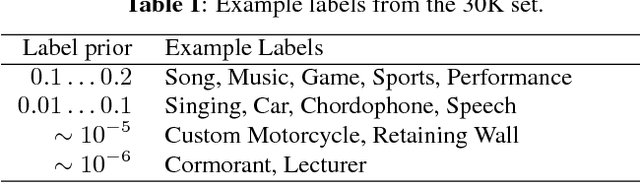
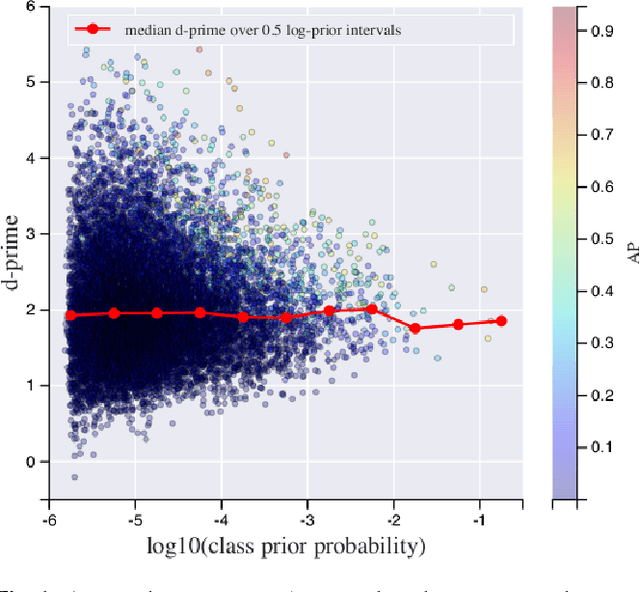
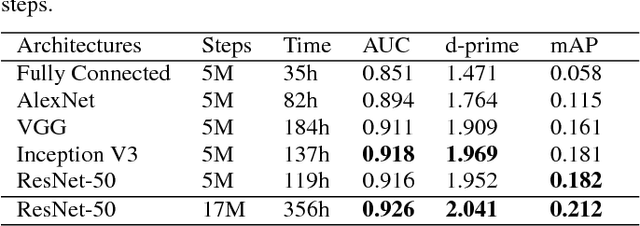
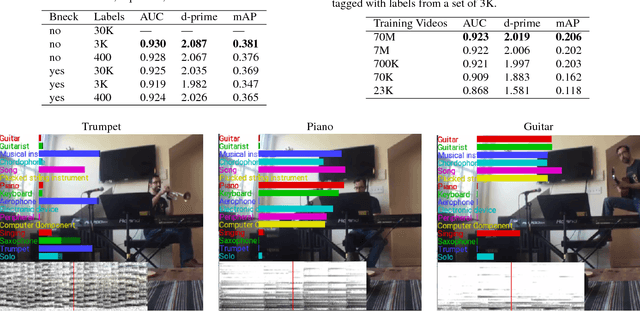
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.