 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Audio-Video Modalities from Image Captions
Apr 01, 2022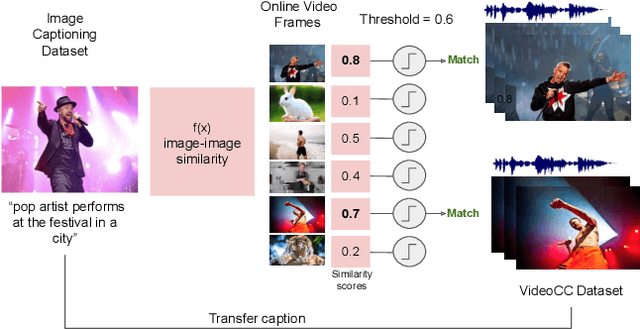
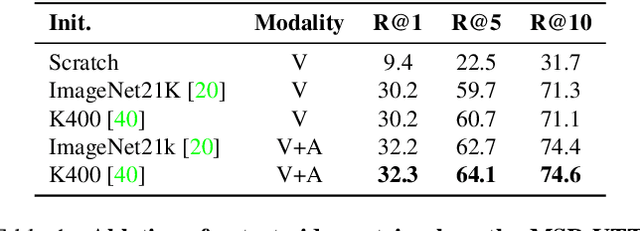

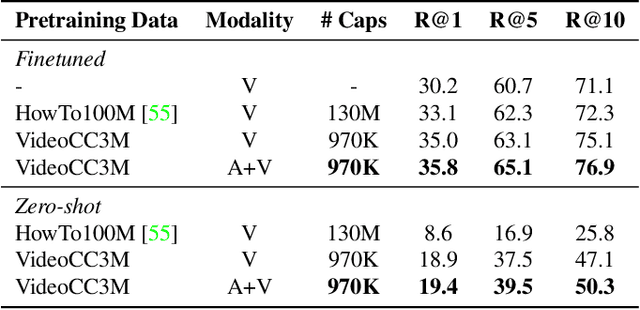
A major challenge in text-video and text-audio retrieval is the lack of large-scale training data. This is unlike image-captioning, where datasets are in the order of millions of samples. To close this gap we propose a new video mining pipeline which involves transferring captions from image captioning datasets to video clips with no additional manual effort. Using this pipeline, we create a new large-scale, weakly labelled audio-video captioning dataset consisting of millions of paired clips and captions. We show that training a multimodal transformed based model on this data achieves competitive performance on video retrieval and video captioning, matching or even outperforming HowTo100M pretraining with 20x fewer clips. We also show that our mined clips are suitable for text-audio pretraining, and achieve state of the art results for the task of audio retrieval.
PathTrack: Fast Trajectory Annotation with Path Supervision
Mar 22, 2017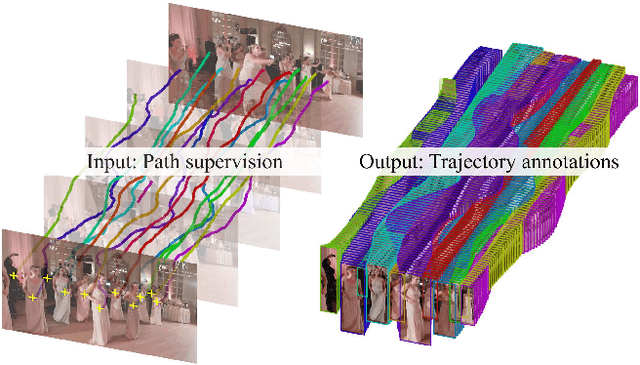
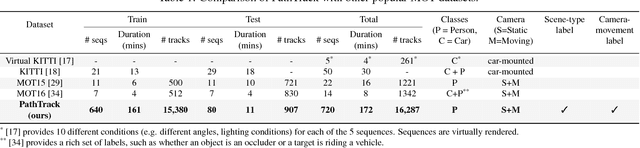


Progress in Multiple Object Tracking (MOT) has been historically limited by the size of the available datasets. We present an efficient framework to annotate trajectories and use it to produce a MOT dataset of unprecedented size. In our novel path supervision the annotator loosely follows the object with the cursor while watching the video, providing a path annotation for each object in the sequence. Our approach is able to turn such weak annotations into dense box trajectories. Our experiments on existing datasets prove that our framework produces more accurate annotations than the state of the art, in a fraction of the time. We further validate our approach by crowdsourcing the PathTrack dataset, with more than 15,000 person trajectories in 720 sequences. Tracking approaches can benefit training on such large-scale datasets, as did object recognition. We prove this by re-training an off-the-shelf person matching network, originally trained on the MOT15 dataset, almost halving the misclassification rate. Additionally, training on our data consistently improves tracking results, both on our dataset and on MOT15. On the latter, we improve the top-performing tracker (NOMT) dropping the number of IDSwitches by 18% and fragments by 5%.