 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Immiscible Diffusion: Accelerate Diffusion Training by Reducing Its Miscibility
May 24, 2025The substantial training cost of diffusion models hinders their deployment. Immiscible Diffusion recently showed that reducing diffusion trajectory mixing in the noise space via linear assignment accelerates training by simplifying denoising. To extend immiscible diffusion beyond the inefficient linear assignment under high batch sizes and high dimensions, we refine this concept to a broader miscibility reduction at any layer and by any implementation. Specifically, we empirically demonstrate the bijective nature of the denoising process with respect to immiscible diffusion, ensuring its preservation of generative diversity. Moreover, we provide thorough analysis and show step-by-step how immiscibility eases denoising and improves efficiency. Extending beyond linear assignment, we propose a family of implementations including K-nearest neighbor (KNN) noise selection and image scaling to reduce miscibility, achieving up to >4x faster training across diverse models and tasks including unconditional/conditional generation, image editing, and robotics planning. Furthermore, our analysis of immiscibility offers a novel perspective on how optimal transport (OT) enhances diffusion training. By identifying trajectory miscibility as a fundamental bottleneck, we believe this work establishes a potentially new direction for future research into high-efficiency diffusion training. The code is available at https://github.com/yhli123/Immiscible-Diffusion.
MALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
CamViG: Camera Aware Image-to-Video Generation with Multimodal Transformers
May 21, 2024



We extend multimodal transformers to include 3D camera motion as a conditioning signal for the task of video generation. Generative video models are becoming increasingly powerful, thus focusing research efforts on methods of controlling the output of such models. We propose to add virtual 3D camera controls to generative video methods by conditioning generated video on an encoding of three-dimensional camera movement over the course of the generated video. Results demonstrate that we are (1) able to successfully control the camera during video generation, starting from a single frame and a camera signal, and (2) we demonstrate the accuracy of the generated 3D camera paths using traditional computer vision methods.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Alternating Gradient Descent and Mixture-of-Experts for Integrated Multimodal Perception
May 10, 2023



We present Integrated Multimodal Perception (IMP), a simple and scalable multimodal multi-task training and modeling approach. IMP integrates multimodal inputs including image, video, text, and audio into a single Transformer encoder with minimal modality-specific components. IMP makes use of a novel design that combines Alternating Gradient Descent (AGD) and Mixture-of-Experts (MoE) for efficient model \& task scaling. We conduct extensive empirical studies about IMP and reveal the following key insights: 1) performing gradient descent updates by alternating on diverse heterogeneous modalities, loss functions, and tasks, while also varying input resolutions, efficiently improves multimodal understanding. 2) model sparsification with MoE on a single modality-agnostic encoder substantially improves the performance, outperforming dense models that use modality-specific encoders or additional fusion layers and greatly mitigating the conflicts between modalities. IMP achieves competitive performance on a wide range of downstream tasks including image classification, video classification, image-text, and video-text retrieval. Most notably, we train a sparse IMP-MoE-L focusing on video tasks that achieves new state-of-the-art in zero-shot video classification. Our model achieves 77.0% on Kinetics-400, 76.8% on Kinetics-600, and 76.8% on Kinetics-700 zero-shot classification accuracy, improving the previous state-of-the-art by +5%, +6.7%, and +5.8%, respectively, while using only 15% of their total training computational cost.
Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text
Dec 14, 2021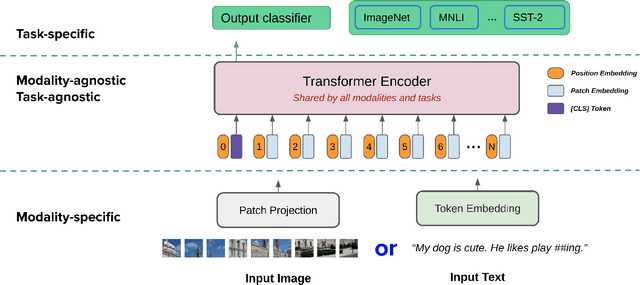
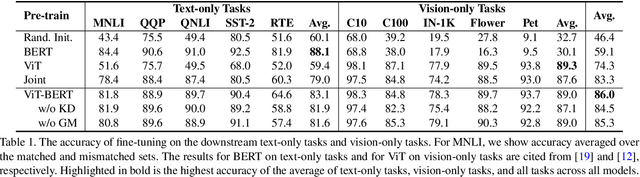
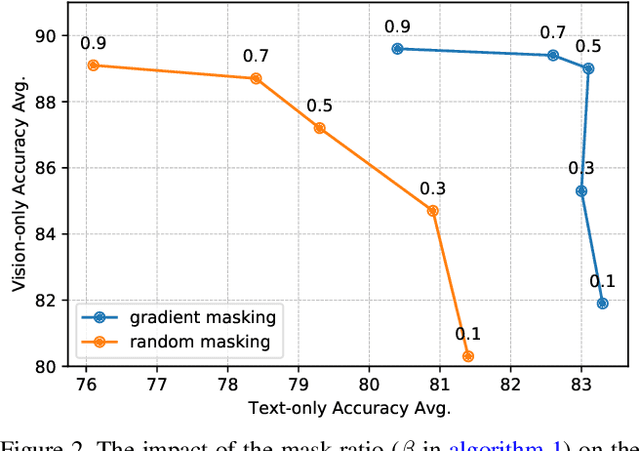
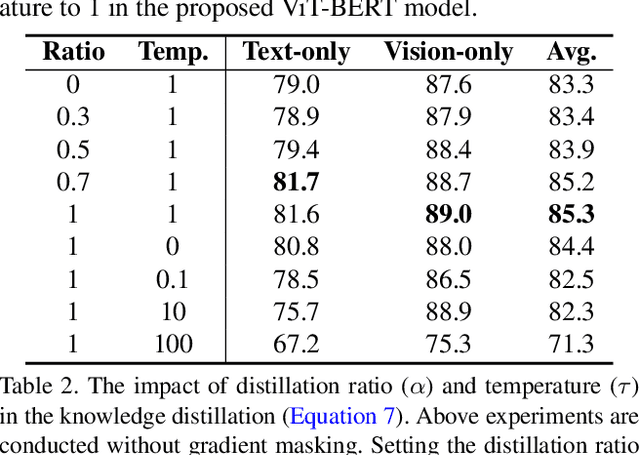
In this paper, we explore the possibility of building a unified foundation model that can be adapted to both vision-only and text-only tasks. Starting from BERT and ViT, we design a unified transformer consisting of modality-specific tokenizers, a shared transformer encoder, and task-specific output heads. To efficiently pre-train the proposed model jointly on unpaired images and text, we propose two novel techniques: (i) We employ the separately-trained BERT and ViT models as teachers and apply knowledge distillation to provide additional, accurate supervision signals for the joint training; (ii) We propose a novel gradient masking strategy to balance the parameter updates from the image and text pre-training losses. We evaluate the jointly pre-trained transformer by fine-tuning it on image classification tasks and natural language understanding tasks, respectively. The experiments show that the resultant unified foundation transformer works surprisingly well on both the vision-only and text-only tasks, and the proposed knowledge distillation and gradient masking strategy can effectively lift the performance to approach the level of separately-trained models.
MoViNets: Mobile Video Networks for Efficient Video Recognition
Apr 18, 2021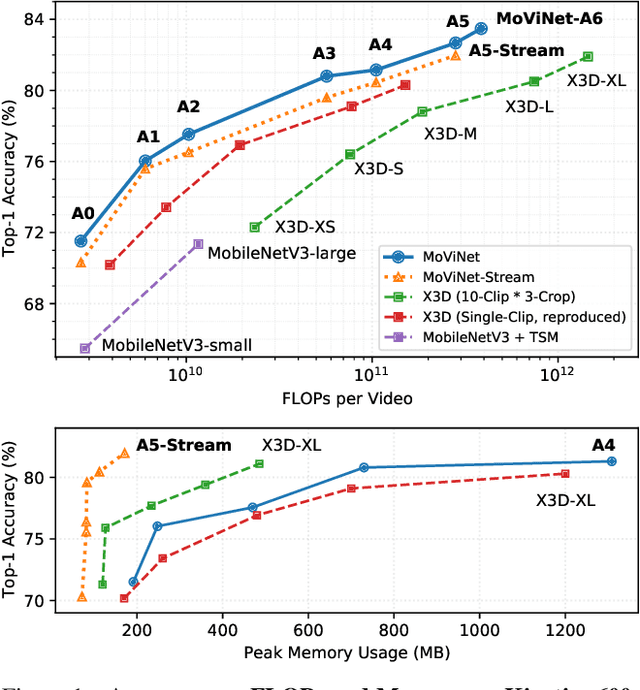


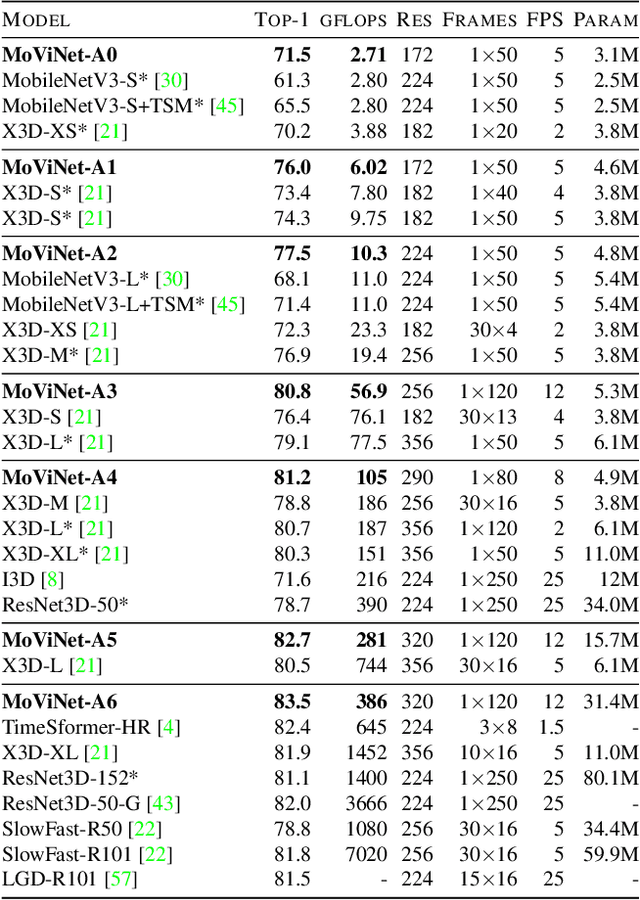
We present Mobile Video Networks (MoViNets), a family of computation and memory efficient video networks that can operate on streaming video for online inference. 3D convolutional neural networks (CNNs) are accurate at video recognition but require large computation and memory budgets and do not support online inference, making them difficult to work on mobile devices. We propose a three-step approach to improve computational efficiency while substantially reducing the peak memory usage of 3D CNNs. First, we design a video network search space and employ neural architecture search to generate efficient and diverse 3D CNN architectures. Second, we introduce the Stream Buffer technique that decouples memory from video clip duration, allowing 3D CNNs to embed arbitrary-length streaming video sequences for both training and inference with a small constant memory footprint. Third, we propose a simple ensembling technique to improve accuracy further without sacrificing efficiency. These three progressive techniques allow MoViNets to achieve state-of-the-art accuracy and efficiency on the Kinetics, Moments in Time, and Charades video action recognition datasets. For instance, MoViNet-A5-Stream achieves the same accuracy as X3D-XL on Kinetics 600 while requiring 80% fewer FLOPs and 65% less memory. Code will be made available at https://github.com/tensorflow/models/tree/master/official/vision.
Multiple Networks are More Efficient than One: Fast and Accurate Models via Ensembles and Cascades
Dec 03, 2020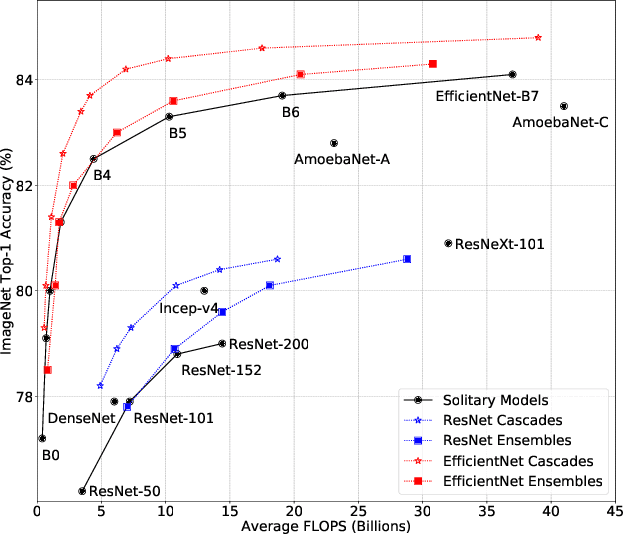
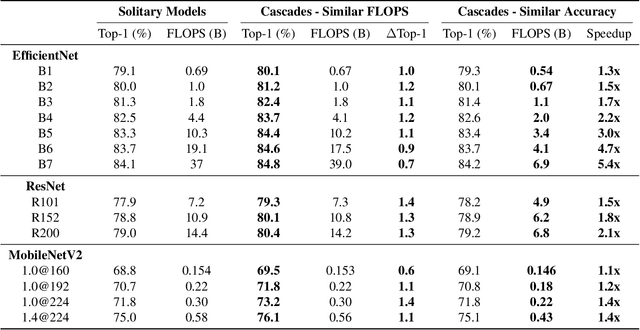
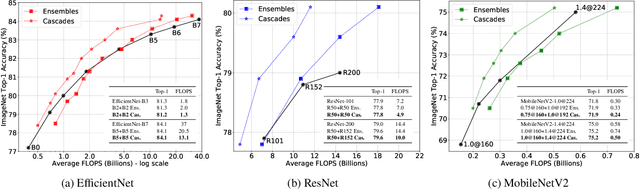
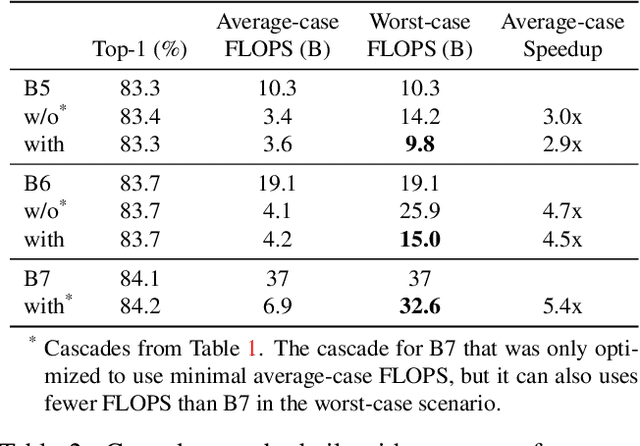
Recent work on efficient neural network architectures focuses on discovering a solitary network that can achieve superior computational efficiency and accuracy. While this paradigm has yielded impressive results, the search for novel architectures usually requires significant computational resources. In this work, we demonstrate a simple complementary paradigm to obtain efficient and accurate models that requires no architectural tuning. We show that committee-based models, i.e., ensembles or cascades of models, can easily obtain higher accuracy with less computation when compared to a single model. We extensively investigate the benefits of committee-based models on various vision tasks and architecture families. Our results suggest that in the large computation regime, model ensembles are a more cost-effective way to improve accuracy than using a large solitary model. We also find that the computational cost of an ensemble can be significantly reduced by converting them to cascades, while often retaining the original accuracy of the full ensemble.
When Ensembling Smaller Models is More Efficient than Single Large Models
May 01, 2020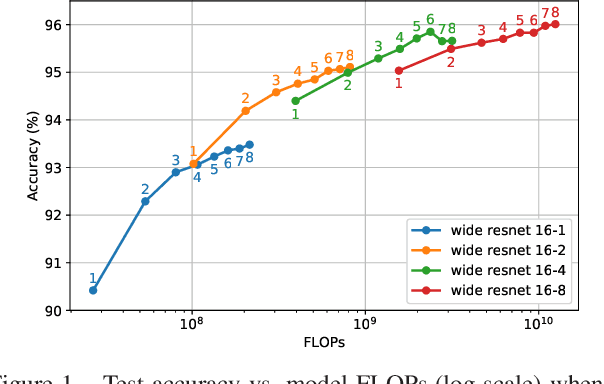
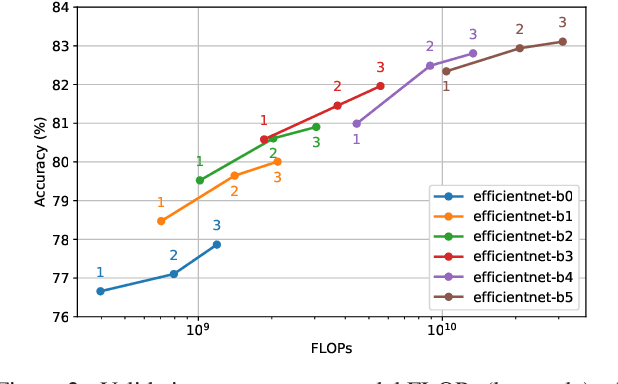
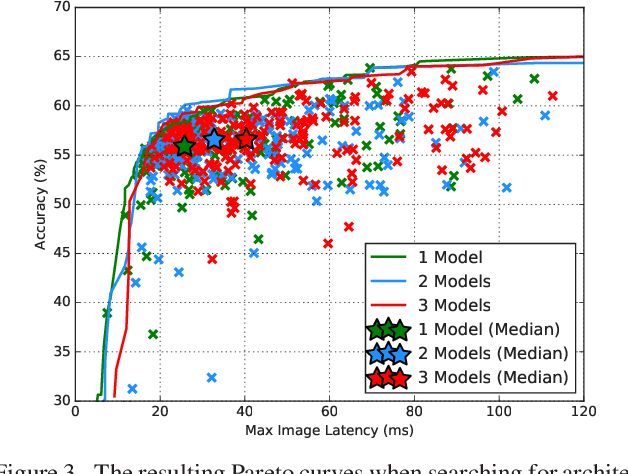
Ensembling is a simple and popular technique for boosting evaluation performance by training multiple models (e.g., with different initializations) and aggregating their predictions. This approach is commonly reserved for the largest models, as it is commonly held that increasing the model size provides a more substantial reduction in error than ensembling smaller models. However, we show results from experiments on CIFAR-10 and ImageNet that ensembles can outperform single models with both higher accuracy and requiring fewer total FLOPs to compute, even when those individual models' weights and hyperparameters are highly optimized. Furthermore, this gap in improvement widens as models become large. This presents an interesting observation that output diversity in ensembling can often be more efficient than training larger models, especially when the models approach the size of what their dataset can foster. Instead of using the common practice of tuning a single large model, one can use ensembles as a more flexible trade-off between a model's inference speed and accuracy. This also potentially eases hardware design, e.g., an easier way to parallelize the model across multiple workers for real-time or distributed inference.