 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking generative image pretraining: How far are we from scaling up next-pixel prediction?
Nov 11, 2025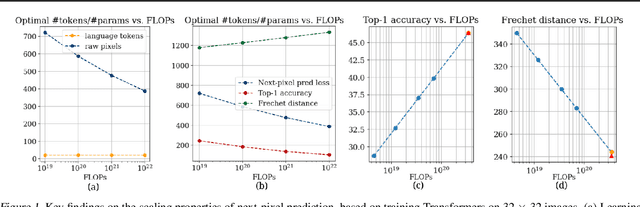
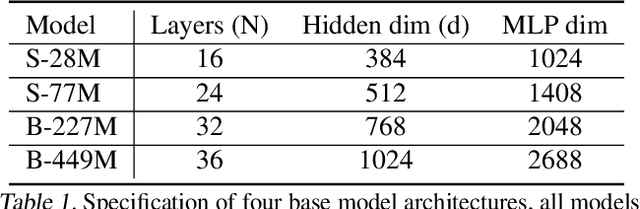

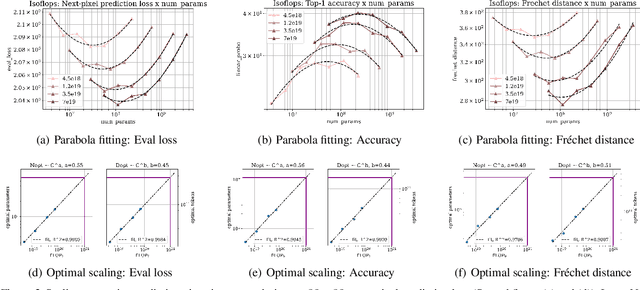
This paper investigates the scaling properties of autoregressive next-pixel prediction, a simple, end-to-end yet under-explored framework for unified vision models. Starting with images at resolutions of 32x32, we train a family of Transformers using IsoFlops profiles across compute budgets up to 7e19 FLOPs and evaluate three distinct target metrics: next-pixel prediction objective, ImageNet classification accuracy, and generation quality measured by Fr'echet Distance. First, optimal scaling strategy is critically task-dependent. At a fixed 32x32 resolution alone, the optimal scaling properties for image classification and image generation diverge, where generation optimal setup requires the data size grow three to five times faster than for the classification optimal setup. Second, as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size. Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years.
Tracing LLM Reasoning Processes with Strategic Games: A Framework for Planning, Revision, and Resource-Constrained Decision Making
Jun 13, 2025

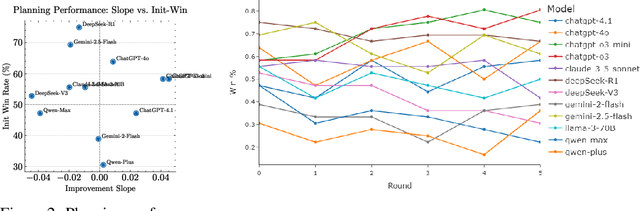
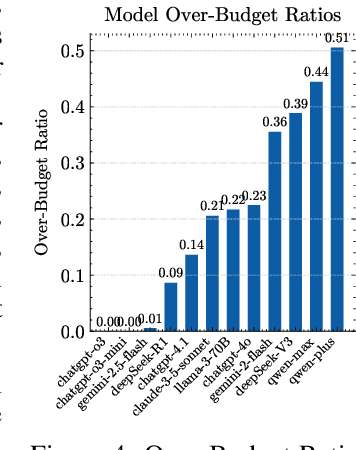
Large language models (LLMs) are increasingly used for tasks that require complex reasoning. Most benchmarks focus on final outcomes but overlook the intermediate reasoning steps - such as planning, revision, and decision making under resource constraints. We argue that measuring these internal processes is essential for understanding model behavior and improving reliability. We propose using strategic games as a natural evaluation environment: closed, rule-based systems with clear states, limited resources, and automatic feedback. We introduce a framework that evaluates LLMs along three core dimensions: planning, revision, and resource-constrained decision making. To operationalize this, we define metrics beyond win rate, including overcorrection risk rate, correction success rate, improvement slope, and over-budget ratio. In 4320 adversarial rounds across 12 leading models, ChatGPT-o3-mini achieves the top composite score, with a win rate of 74.7 percent, a correction success rate of 78.6 percent, and an improvement slope of 0.041. By contrast, Qwen-Plus, despite an overcorrection risk rate of 81.6 percent, wins only 25.6 percent of its matches - primarily due to excessive resource use. We also observe a negative correlation between overcorrection risk rate and correction success rate (Pearson r = -0.51, p = 0.093), suggesting that more frequent edits do not always improve outcomes. Our findings highlight the value of assessing not only what LLMs decide but how they arrive at those decisions
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Language-Guided Image Tokenization for Generation
Dec 08, 2024



Image tokenization, the process of transforming raw image pixels into a compact low-dimensional latent representation, has proven crucial for scalable and efficient image generation. However, mainstream image tokenization methods generally have limited compression rates, making high-resolution image generation computationally expensive. To address this challenge, we propose to leverage language for efficient image tokenization, and we call our method Text-Conditioned Image Tokenization (TexTok). TexTok is a simple yet effective tokenization framework that leverages language to provide high-level semantics. By conditioning the tokenization process on descriptive text captions, TexTok allows the tokenization process to focus on encoding fine-grained visual details into latent tokens, leading to enhanced reconstruction quality and higher compression rates. Compared to the conventional tokenizer without text conditioning, TexTok achieves average reconstruction FID improvements of 29.2% and 48.1% on ImageNet-256 and -512 benchmarks respectively, across varying numbers of tokens. These tokenization improvements consistently translate to 16.3% and 34.3% average improvements in generation FID. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system can achieve a 93.5x inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet-512. TexTok with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet-256 and -512 respectively. Furthermore, we demonstrate TexTok's superiority on the text-to-image generation task, effectively utilizing the off-the-shelf text captions in tokenization.
MaskBit: Embedding-free Image Generation via Bit Tokens
Sep 24, 2024



Masked transformer models for class-conditional image generation have become a compelling alternative to diffusion models. Typically comprising two stages - an initial VQGAN model for transitioning between latent space and image space, and a subsequent Transformer model for image generation within latent space - these frameworks offer promising avenues for image synthesis. In this study, we present two primary contributions: Firstly, an empirical and systematic examination of VQGANs, leading to a modernized VQGAN. Secondly, a novel embedding-free generation network operating directly on bit tokens - a binary quantized representation of tokens with rich semantics. The first contribution furnishes a transparent, reproducible, and high-performing VQGAN model, enhancing accessibility and matching the performance of current state-of-the-art methods while revealing previously undisclosed details. The second contribution demonstrates that embedding-free image generation using bit tokens achieves a new state-of-the-art FID of 1.52 on the ImageNet 256x256 benchmark, with a compact generator model of mere 305M parameters.
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
May 26, 2024



Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
May 22, 2024



Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
Efficient LLM Jailbreak via Adaptive Dense-to-sparse Constrained Optimization
May 15, 2024
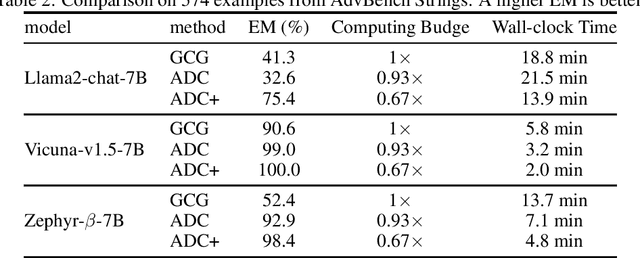


Recent research indicates that large language models (LLMs) are susceptible to jailbreaking attacks that can generate harmful content. This paper introduces a novel token-level attack method, Adaptive Dense-to-Sparse Constrained Optimization (ADC), which effectively jailbreaks several open-source LLMs. Our approach relaxes the discrete jailbreak optimization into a continuous optimization and progressively increases the sparsity of the optimizing vectors. Consequently, our method effectively bridges the gap between discrete and continuous space optimization. Experimental results demonstrate that our method is more effective and efficient than existing token-level methods. On Harmbench, our method achieves state of the art attack success rate on seven out of eight LLMs. Code will be made available. Trigger Warning: This paper contains model behavior that can be offensive in nature.
Improving and Unifying Discrete&Continuous-time Discrete Denoising Diffusion
Feb 06, 2024



Discrete diffusion models have seen a surge of attention with applications on naturally discrete data such as language and graphs. Although discrete-time discrete diffusion has been established for a while, only recently Campbell et al. (2022) introduced the first framework for continuous-time discrete diffusion. However, their training and sampling processes differ significantly from the discrete-time version, necessitating nontrivial approximations for tractability. In this paper, we first present a series of mathematical simplifications of the variational lower bound that enable more accurate and easy-to-optimize training for discrete diffusion. In addition, we derive a simple formulation for backward denoising that enables exact and accelerated sampling, and importantly, an elegant unification of discrete-time and continuous-time discrete diffusion. Thanks to simpler analytical formulations, both forward and now also backward probabilities can flexibly accommodate any noise distribution, including different noise distributions for multi-element objects. Experiments show that our proposed USD3 (for Unified Simplified Discrete Denoising Diffusion) outperform all SOTA baselines on established datasets. We open-source our unified code at https://github.com/LingxiaoShawn/USD3.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023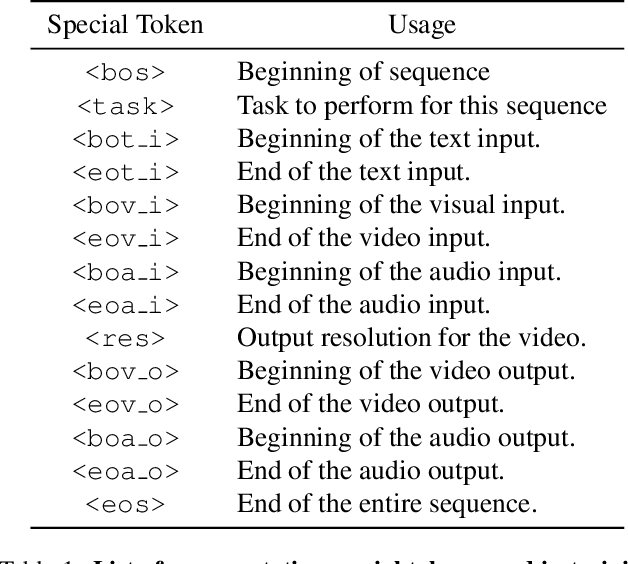



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/