 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Complex Non-Rigid Image Edits from Multimodal Conditioning
Dec 13, 2024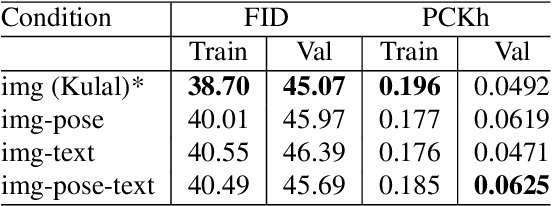


In this paper we focus on inserting a given human (specifically, a single image of a person) into a novel scene. Our method, which builds on top of Stable Diffusion, yields natural looking images while being highly controllable with text and pose. To accomplish this we need to train on pairs of images, the first a reference image with the person, the second a "target image" showing the same person (with a different pose and possibly in a different background). Additionally we require a text caption describing the new pose relative to that in the reference image. In this paper we present a novel dataset following this criteria, which we create using pairs of frames from human-centric and action-rich videos and employing a multimodal LLM to automatically summarize the difference in human pose for the text captions. We demonstrate that identity preservation is a more challenging task in scenes "in-the-wild", and especially scenes where there is an interaction between persons and objects. Combining the weak supervision from noisy captions, with robust 2D pose improves the quality of person-object interactions.
Sample what you cant compress
Sep 04, 2024



For learned image representations, basic autoencoders often produce blurry results. Reconstruction quality can be improved by incorporating additional penalties such as adversarial (GAN) and perceptual losses. Arguably, these approaches lack a principled interpretation. Concurrently, in generative settings diffusion has demonstrated a remarkable ability to create crisp, high quality results and has solid theoretical underpinnings (from variational inference to direct study as the Fisher Divergence). Our work combines autoencoder representation learning with diffusion and is, to our knowledge, the first to demonstrate the efficacy of jointly learning a continuous encoder and decoder under a diffusion-based loss. We demonstrate that this approach yields better reconstruction quality as compared to GAN-based autoencoders while being easier to tune. We also show that the resulting representation is easier to model with a latent diffusion model as compared to the representation obtained from a state-of-the-art GAN-based loss. Since our decoder is stochastic, it can generate details not encoded in the otherwise deterministic latent representation; we therefore name our approach "Sample what you can't compress", or SWYCC for short.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023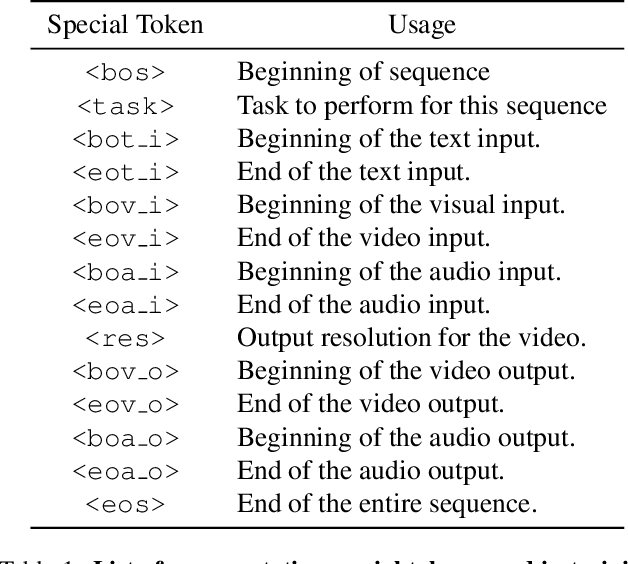



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Text and Click inputs for unambiguous open vocabulary instance segmentation
Nov 24, 2023



Segmentation localizes objects in an image on a fine-grained per-pixel scale. Segmentation benefits by humans-in-the-loop to provide additional input of objects to segment using a combination of foreground or background clicks. Tasks include photoediting or novel dataset annotation, where human annotators leverage an existing segmentation model instead of drawing raw pixel level annotations. We propose a new segmentation process, Text + Click segmentation, where a model takes as input an image, a text phrase describing a class to segment, and a single foreground click specifying the instance to segment. Compared to previous approaches, we leverage open-vocabulary image-text models to support a wide-range of text prompts. Conditioning segmentations on text prompts improves the accuracy of segmentations on novel or unseen classes. We demonstrate that the combination of a single user-specified foreground click and a text prompt allows a model to better disambiguate overlapping or co-occurring semantic categories, such as "tie", "suit", and "person". We study these results across common segmentation datasets such as refCOCO, COCO, VOC, and OpenImages. Source code available here.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Open-Vocabulary Temporal Action Detection with Off-the-Shelf Image-Text Features
Dec 20, 2022Detecting actions in untrimmed videos should not be limited to a small, closed set of classes. We present a simple, yet effective strategy for open-vocabulary temporal action detection utilizing pretrained image-text co-embeddings. Despite being trained on static images rather than videos, we show that image-text co-embeddings enable openvocabulary performance competitive with fully-supervised models. We show that the performance can be further improved by ensembling the image-text features with features encoding local motion, like optical flow based features, or other modalities, like audio. In addition, we propose a more reasonable open-vocabulary evaluation setting for the ActivityNet data set, where the category splits are based on similarity rather than random assignment.
Proper Reuse of Image Classification Features Improves Object Detection
Apr 01, 2022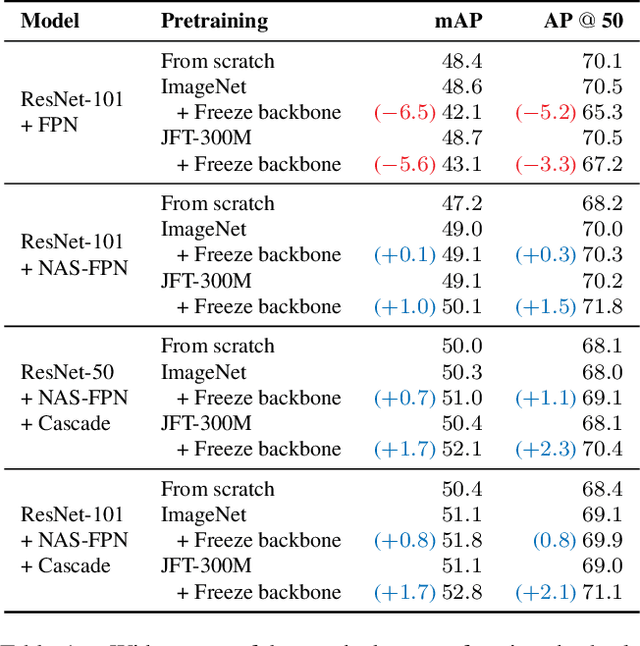
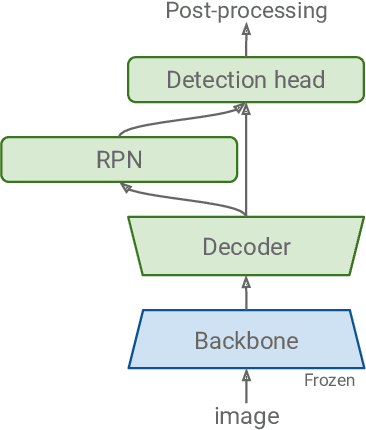
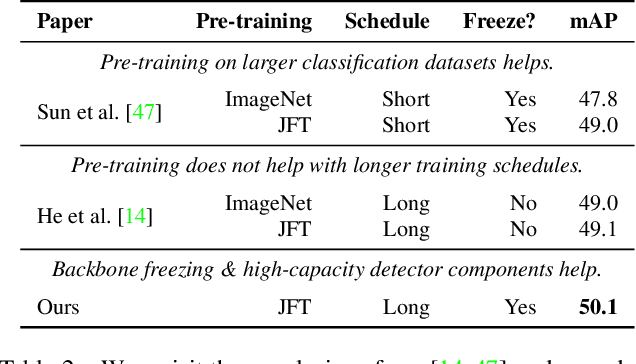

A common practice in transfer learning is to initialize the downstream model weights by pre-training on a data-abundant upstream task. In object detection specifically, the feature backbone is typically initialized with Imagenet classifier weights and fine-tuned on the object detection task. Recent works show this is not strictly necessary under longer training regimes and provide recipes for training the backbone from scratch. We investigate the opposite direction of this end-to-end training trend: we show that an extreme form of knowledge preservation -- freezing the classifier-initialized backbone -- consistently improves many different detection models, and leads to considerable resource savings. We hypothesize and corroborate experimentally that the remaining detector components capacity and structure is a crucial factor in leveraging the frozen backbone. Immediate applications of our findings include performance improvements on hard cases like detection of long-tail object classes and computational and memory resource savings that contribute to making the field more accessible to researchers with access to fewer computational resources.
Less is More: Generating Grounded Navigation Instructions from Landmarks
Nov 29, 2021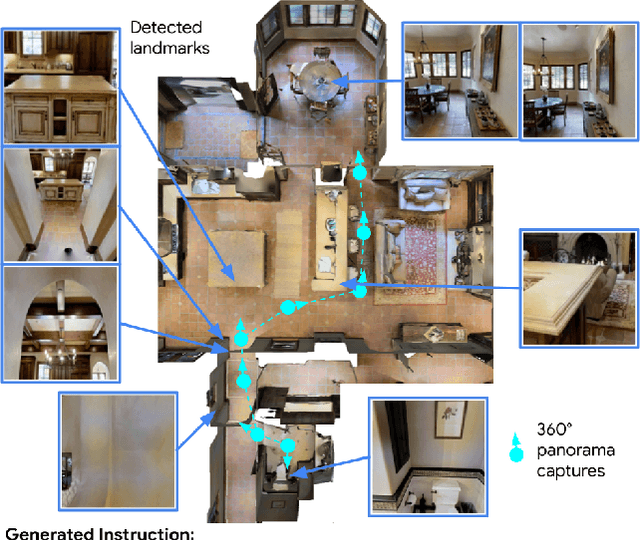
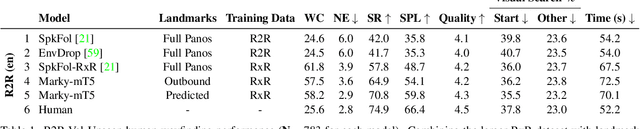


We study the automatic generation of navigation instructions from 360-degree images captured on indoor routes. Existing generators suffer from poor visual grounding, causing them to rely on language priors and hallucinate objects. Our MARKY-MT5 system addresses this by focusing on visual landmarks; it comprises a first stage landmark detector and a second stage generator -- a multimodal, multilingual, multitask encoder-decoder. To train it, we bootstrap grounded landmark annotations on top of the Room-across-Room (RxR) dataset. Using text parsers, weak supervision from RxR's pose traces, and a multilingual image-text encoder trained on 1.8b images, we identify 1.1m English, Hindi and Telugu landmark descriptions and ground them to specific regions in panoramas. On Room-to-Room, human wayfinders obtain success rates (SR) of 71% following MARKY-MT5's instructions, just shy of their 75% SR following human instructions -- and well above SRs with other generators. Evaluations on RxR's longer, diverse paths obtain 61-64% SRs on three languages. Generating such high-quality navigation instructions in novel environments is a step towards conversational navigation tools and could facilitate larger-scale training of instruction-following agents.
The iWildCam 2021 Competition Dataset
May 07, 2021


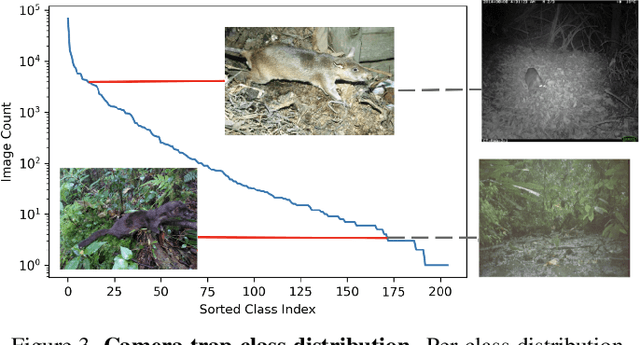
Camera traps enable the automatic collection of large quantities of image data. Ecologists use camera traps to monitor animal populations all over the world. In order to estimate the abundance of a species from camera trap data, ecologists need to know not just which species were seen, but also how many individuals of each species were seen. Object detection techniques can be used to find the number of individuals in each image. However, since camera traps collect images in motion-triggered bursts, simply adding up the number of detections over all frames is likely to lead to an incorrect estimate. Overcoming these obstacles may require incorporating spatio-temporal reasoning or individual re-identification in addition to traditional species detection and classification. We have prepared a challenge where the training data and test data are from different cameras spread across the globe. The set of species seen in each camera overlap, but are not identical. The challenge is to classify species and count individual animals across sequences in the test cameras.
The surprising impact of mask-head architecture on novel class segmentation
Apr 01, 2021
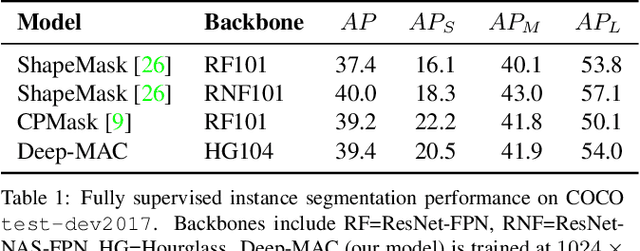
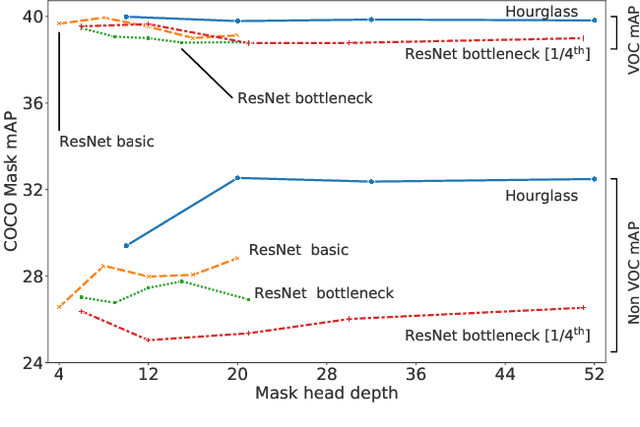
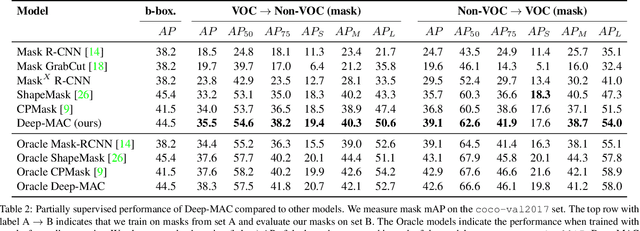
Instance segmentation models today are very accurate when trained on large annotated datasets, but collecting mask annotations at scale is prohibitively expensive. We address the partially supervised instance segmentation problem in which one can train on (significantly cheaper) bounding boxes for all categories but use masks only for a subset of categories. In this work, we focus on a popular family of models which apply differentiable cropping to a feature map and predict a mask based on the resulting crop. Within this family, we show that the architecture of the mask-head plays a surprisingly important role in generalization to classes for which we do not observe masks during training. While many architectures perform similarly when trained in fully supervised mode, we show that they often generalize to novel classes in dramatically different ways. We call this phenomenon the strong mask generalization effect, which we exploit by replacing the typical mask-head of 2-4 layers with significantly deeper off-the-shelf architectures (e.g. ResNet, Hourglass models). We also show that the choice of mask-head architecture alone can lead to SOTA results on the partially supervised COCO benchmark without the need of specialty modules or losses proposed by prior literature. Finally, we demonstrate that our effect is general, holding across underlying detection methodologies, (e.g. both anchor-based or anchor free or no detector at all) and across different backbone networks. Code and pre-trained models are available at https://git.io/deepmac.