 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
Mar 06, 2024



Value functions are a central component of deep reinforcement learning (RL). These functions, parameterized by neural networks, are trained using a mean squared error regression objective to match bootstrapped target values. However, scaling value-based RL methods that use regression to large networks, such as high-capacity Transformers, has proven challenging. This difficulty is in stark contrast to supervised learning: by leveraging a cross-entropy classification loss, supervised methods have scaled reliably to massive networks. Observing this discrepancy, in this paper, we investigate whether the scalability of deep RL can also be improved simply by using classification in place of regression for training value functions. We demonstrate that value functions trained with categorical cross-entropy significantly improves performance and scalability in a variety of domains. These include: single-task RL on Atari 2600 games with SoftMoEs, multi-task RL on Atari with large-scale ResNets, robotic manipulation with Q-transformers, playing Chess without search, and a language-agent Wordle task with high-capacity Transformers, achieving state-of-the-art results on these domains. Through careful analysis, we show that the benefits of categorical cross-entropy primarily stem from its ability to mitigate issues inherent to value-based RL, such as noisy targets and non-stationarity. Overall, we argue that a simple shift to training value functions with categorical cross-entropy can yield substantial improvements in the scalability of deep RL at little-to-no cost.
Less is More: Generating Grounded Navigation Instructions from Landmarks
Nov 29, 2021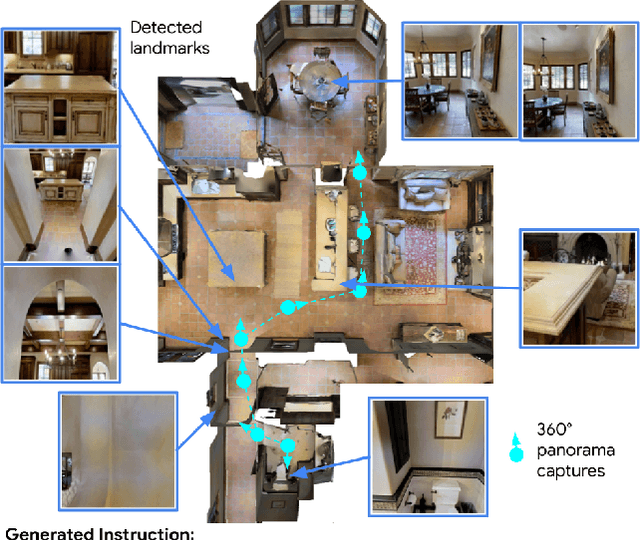
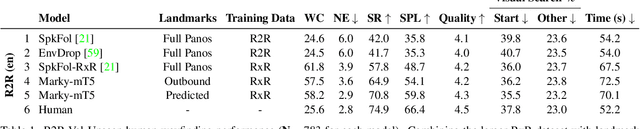


We study the automatic generation of navigation instructions from 360-degree images captured on indoor routes. Existing generators suffer from poor visual grounding, causing them to rely on language priors and hallucinate objects. Our MARKY-MT5 system addresses this by focusing on visual landmarks; it comprises a first stage landmark detector and a second stage generator -- a multimodal, multilingual, multitask encoder-decoder. To train it, we bootstrap grounded landmark annotations on top of the Room-across-Room (RxR) dataset. Using text parsers, weak supervision from RxR's pose traces, and a multilingual image-text encoder trained on 1.8b images, we identify 1.1m English, Hindi and Telugu landmark descriptions and ground them to specific regions in panoramas. On Room-to-Room, human wayfinders obtain success rates (SR) of 71% following MARKY-MT5's instructions, just shy of their 75% SR following human instructions -- and well above SRs with other generators. Evaluations on RxR's longer, diverse paths obtain 61-64% SRs on three languages. Generating such high-quality navigation instructions in novel environments is a step towards conversational navigation tools and could facilitate larger-scale training of instruction-following agents.