 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Planning with Jumpy World Models
Feb 23, 2026The ability to plan with temporal abstractions is central to intelligent decision-making. Rather than reasoning over primitive actions, we study agents that compose pre-trained policies as temporally extended actions, enabling solutions to complex tasks that no constituent alone can solve. Such compositional planning remains elusive as compounding errors in long-horizon predictions make it challenging to estimate the visitation distribution induced by sequencing policies. Motivated by the geometric policy composition framework introduced in arXiv:2206.08736, we address these challenges by learning predictive models of multi-step dynamics -- so-called jumpy world models -- that capture state occupancies induced by pre-trained policies across multiple timescales in an off-policy manner. Building on Temporal Difference Flows (arXiv:2503.09817), we enhance these models with a novel consistency objective that aligns predictions across timescales, improving long-horizon predictive accuracy. We further demonstrate how to combine these generative predictions to estimate the value of executing arbitrary sequences of policies over varying timescales. Empirically, we find that compositional planning with jumpy world models significantly improves zero-shot performance across a wide range of base policies on challenging manipulation and navigation tasks, yielding, on average, a 200% relative improvement over planning with primitive actions on long-horizon tasks.
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models
Apr 15, 2025Unsupervised reinforcement learning (RL) aims at pre-training agents that can solve a wide range of downstream tasks in complex environments. Despite recent advancements, existing approaches suffer from several limitations: they may require running an RL process on each downstream task to achieve a satisfactory performance, they may need access to datasets with good coverage or well-curated task-specific samples, or they may pre-train policies with unsupervised losses that are poorly correlated with the downstream tasks of interest. In this paper, we introduce a novel algorithm regularizing unsupervised RL towards imitating trajectories from unlabeled behavior datasets. The key technical novelty of our method, called Forward-Backward Representations with Conditional-Policy Regularization, is to train forward-backward representations to embed the unlabeled trajectories to the same latent space used to represent states, rewards, and policies, and use a latent-conditional discriminator to encourage policies to ``cover'' the states in the unlabeled behavior dataset. As a result, we can learn policies that are well aligned with the behaviors in the dataset, while retaining zero-shot generalization capabilities for reward-based and imitation tasks. We demonstrate the effectiveness of this new approach in a challenging humanoid control problem: leveraging observation-only motion capture datasets, we train Meta Motivo, the first humanoid behavioral foundation model that can be prompted to solve a variety of whole-body tasks, including motion tracking, goal reaching, and reward optimization. The resulting model is capable of expressing human-like behaviors and it achieves competitive performance with task-specific methods while outperforming state-of-the-art unsupervised RL and model-based baselines.
Temporal Difference Flows
Mar 12, 2025Predictive models of the future are fundamental for an agent's ability to reason and plan. A common strategy learns a world model and unrolls it step-by-step at inference, where small errors can rapidly compound. Geometric Horizon Models (GHMs) offer a compelling alternative by directly making predictions of future states, avoiding cumulative inference errors. While GHMs can be conveniently learned by a generative analog to temporal difference (TD) learning, existing methods are negatively affected by bootstrapping predictions at train time and struggle to generate high-quality predictions at long horizons. This paper introduces Temporal Difference Flows (TD-Flow), which leverages the structure of a novel Bellman equation on probability paths alongside flow-matching techniques to learn accurate GHMs at over 5x the horizon length of prior methods. Theoretically, we establish a new convergence result and primarily attribute TD-Flow's efficacy to reduced gradient variance during training. We further show that similar arguments can be extended to diffusion-based methods. Empirically, we validate TD-Flow across a diverse set of domains on both generative metrics and downstream tasks including policy evaluation. Moreover, integrating TD-Flow with recent behavior foundation models for planning over pre-trained policies demonstrates substantial performance gains, underscoring its promise for long-horizon decision-making.
Non-Adversarial Inverse Reinforcement Learning via Successor Feature Matching
Nov 11, 2024



In inverse reinforcement learning (IRL), an agent seeks to replicate expert demonstrations through interactions with the environment. Traditionally, IRL is treated as an adversarial game, where an adversary searches over reward models, and a learner optimizes the reward through repeated RL procedures. This game-solving approach is both computationally expensive and difficult to stabilize. In this work, we propose a novel approach to IRL by direct policy optimization: exploiting a linear factorization of the return as the inner product of successor features and a reward vector, we design an IRL algorithm by policy gradient descent on the gap between the learner and expert features. Our non-adversarial method does not require learning a reward function and can be solved seamlessly with existing actor-critic RL algorithms. Remarkably, our approach works in state-only settings without expert action labels, a setting which behavior cloning (BC) cannot solve. Empirical results demonstrate that our method learns from as few as a single expert demonstration and achieves improved performance on various control tasks.
CALE: Continuous Arcade Learning Environment
Oct 31, 2024



We introduce the Continuous Arcade Learning Environment (CALE), an extension of the well-known Arcade Learning Environment (ALE) [Bellemare et al., 2013]. The CALE uses the same underlying emulator of the Atari 2600 gaming system (Stella), but adds support for continuous actions. This enables the benchmarking and evaluation of continuous-control agents (such as PPO [Schulman et al., 2017] and SAC [Haarnoja et al., 2018]) and value-based agents (such as DQN [Mnih et al., 2015] and Rainbow [Hessel et al., 2018]) on the same environment suite. We provide a series of open questions and research directions that CALE enables, as well as initial baseline results using Soft Actor-Critic. CALE is available as part of the ALE athttps://github.com/Farama-Foundation/Arcade-Learning-Environment.
Foundations of Multivariate Distributional Reinforcement Learning
Aug 31, 2024



In reinforcement learning (RL), the consideration of multivariate reward signals has led to fundamental advancements in multi-objective decision-making, transfer learning, and representation learning. This work introduces the first oracle-free and computationally-tractable algorithms for provably convergent multivariate distributional dynamic programming and temporal difference learning. Our convergence rates match the familiar rates in the scalar reward setting, and additionally provide new insights into the fidelity of approximate return distribution representations as a function of the reward dimension. Surprisingly, when the reward dimension is larger than $1$, we show that standard analysis of categorical TD learning fails, which we resolve with a novel projection onto the space of mass-$1$ signed measures. Finally, with the aid of our technical results and simulations, we identify tradeoffs between distribution representations that influence the performance of multivariate distributional RL in practice.
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
Mar 06, 2024



Value functions are a central component of deep reinforcement learning (RL). These functions, parameterized by neural networks, are trained using a mean squared error regression objective to match bootstrapped target values. However, scaling value-based RL methods that use regression to large networks, such as high-capacity Transformers, has proven challenging. This difficulty is in stark contrast to supervised learning: by leveraging a cross-entropy classification loss, supervised methods have scaled reliably to massive networks. Observing this discrepancy, in this paper, we investigate whether the scalability of deep RL can also be improved simply by using classification in place of regression for training value functions. We demonstrate that value functions trained with categorical cross-entropy significantly improves performance and scalability in a variety of domains. These include: single-task RL on Atari 2600 games with SoftMoEs, multi-task RL on Atari with large-scale ResNets, robotic manipulation with Q-transformers, playing Chess without search, and a language-agent Wordle task with high-capacity Transformers, achieving state-of-the-art results on these domains. Through careful analysis, we show that the benefits of categorical cross-entropy primarily stem from its ability to mitigate issues inherent to value-based RL, such as noisy targets and non-stationarity. Overall, we argue that a simple shift to training value functions with categorical cross-entropy can yield substantial improvements in the scalability of deep RL at little-to-no cost.
A Distributional Analogue to the Successor Representation
Feb 13, 2024



This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
Mixtures of Experts Unlock Parameter Scaling for Deep RL
Feb 13, 2024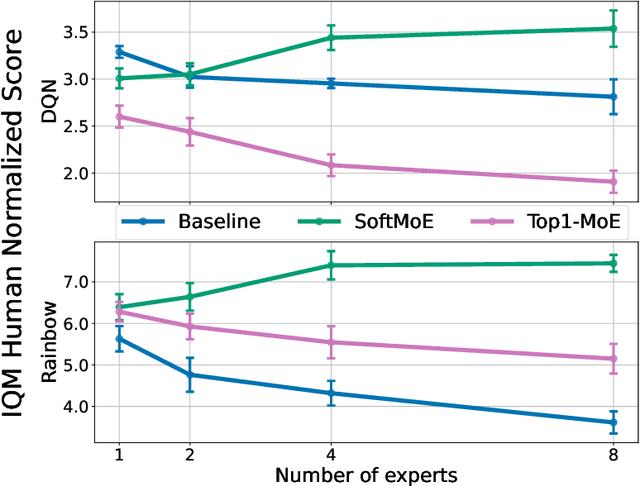
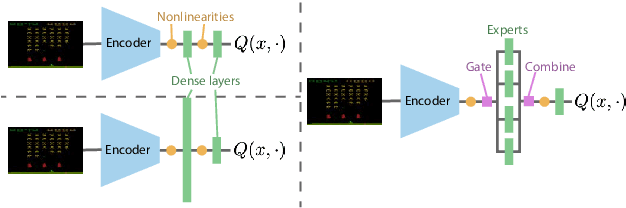
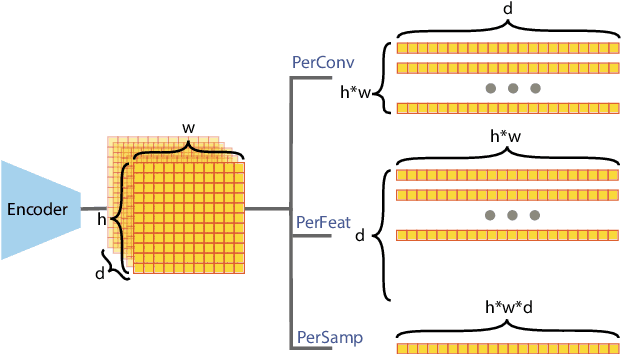

The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.
Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy
Nov 21, 2023We introduce a machine learning approach to determine the transition dynamics of silicon atoms on a single layer of carbon atoms, when stimulated by the electron beam of a scanning transmission electron microscope (STEM). Our method is data-centric, leveraging data collected on a STEM. The data samples are processed and filtered to produce symbolic representations, which we use to train a neural network to predict transition probabilities. These learned transition dynamics are then leveraged to guide a single silicon atom throughout the lattice to pre-determined target destinations. We present empirical analyses that demonstrate the efficacy and generality of our approach.