 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Embodied Foundation Models
Sep 18, 2025Foundation models trained on web-scale data have revolutionized robotics, but their application to low-level control remains largely limited to behavioral cloning. Drawing inspiration from the success of the reinforcement learning stage in fine-tuning large language models, we propose a two-stage post-training approach for robotics. The first stage, Supervised Fine-Tuning (SFT), fine-tunes pretrained foundation models using both: a) behavioral cloning, and b) steps-to-go prediction objectives. In the second stage, Self-Improvement, steps-to-go prediction enables the extraction of a well-shaped reward function and a robust success detector, enabling a fleet of robots to autonomously practice downstream tasks with minimal human supervision. Through extensive experiments on real-world and simulated robot embodiments, our novel post-training recipe unveils significant results on Embodied Foundation Models. First, we demonstrate that the combination of SFT and Self-Improvement is significantly more sample-efficient than scaling imitation data collection for supervised learning, and that it leads to policies with significantly higher success rates. Further ablations highlight that the combination of web-scale pretraining and Self-Improvement is the key to this sample-efficiency. Next, we demonstrate that our proposed combination uniquely unlocks a capability that current methods cannot achieve: autonomously practicing and acquiring novel skills that generalize far beyond the behaviors observed in the imitation learning datasets used during training. These findings highlight the transformative potential of combining pretrained foundation models with online Self-Improvement to enable autonomous skill acquisition in robotics. Our project website can be found at https://self-improving-efms.github.io .
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Jan 10, 2025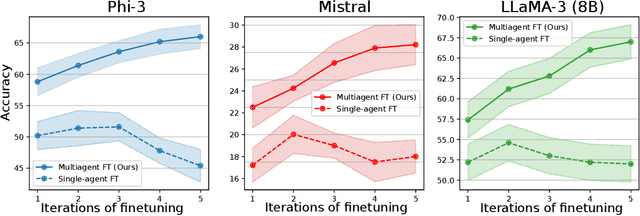
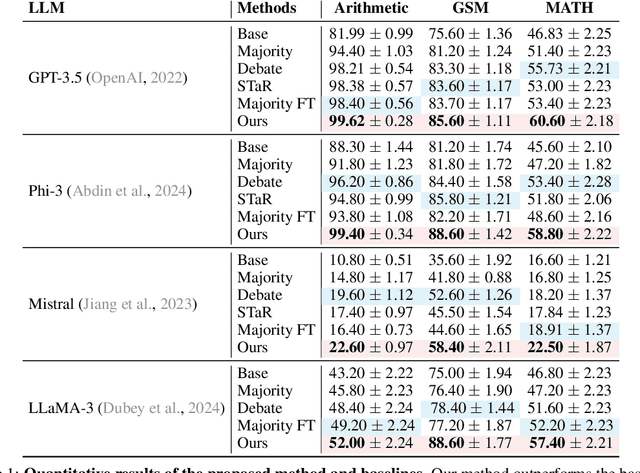
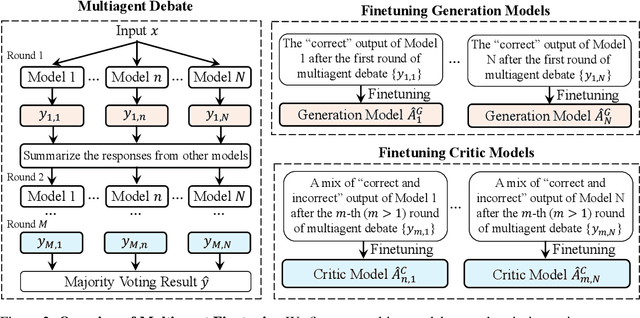
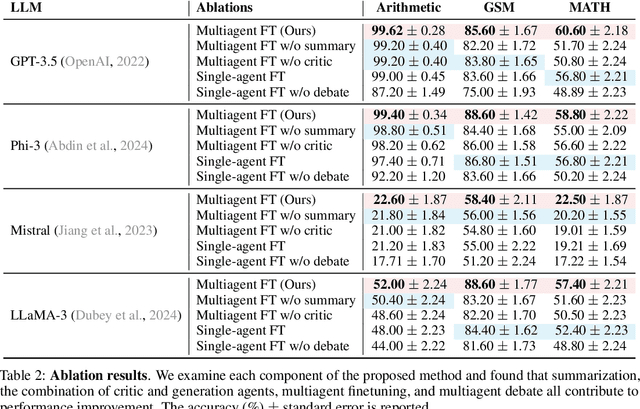
Large language models (LLMs) have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent works have explored how LLMs can be used to generate synthetic data for autonomous self-improvement. However, successive steps of self-improvement can reach a point of diminishing returns. In this work, we propose a complementary approach towards self-improvement where finetuning is applied to a multiagent society of language models. A group of language models, all starting from the same base model, are independently specialized by updating each one using data generated through multiagent interactions among the models. By training each model on independent sets of data, we illustrate how this approach enables specialization across models and diversification over the set of models. As a result, our overall system is able to preserve diverse reasoning chains and autonomously improve over many more rounds of fine-tuning than single-agent self-improvement methods. We quantitatively illustrate the efficacy of the approach across a wide suite of reasoning tasks.
Generative Hierarchical Materials Search
Sep 10, 2024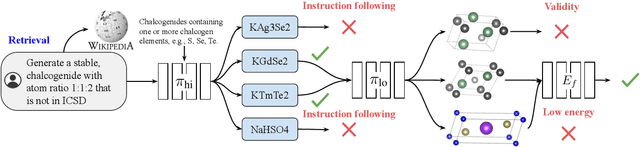



Generative models trained at scale can now produce text, video, and more recently, scientific data such as crystal structures. In applications of generative approaches to materials science, and in particular to crystal structures, the guidance from the domain expert in the form of high-level instructions can be essential for an automated system to output candidate crystals that are viable for downstream research. In this work, we formulate end-to-end language-to-structure generation as a multi-objective optimization problem, and propose Generative Hierarchical Materials Search (GenMS) for controllable generation of crystal structures. GenMS consists of (1) a language model that takes high-level natural language as input and generates intermediate textual information about a crystal (e.g., chemical formulae), and (2) a diffusion model that takes intermediate information as input and generates low-level continuous value crystal structures. GenMS additionally uses a graph neural network to predict properties (e.g., formation energy) from the generated crystal structures. During inference, GenMS leverages all three components to conduct a forward tree search over the space of possible structures. Experiments show that GenMS outperforms other alternatives of directly using language models to generate structures both in satisfying user request and in generating low-energy structures. We confirm that GenMS is able to generate common crystal structures such as double perovskites, or spinels, solely from natural language input, and hence can form the foundation for more complex structure generation in near future.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Semi-Supervised One-Shot Imitation Learning
Aug 09, 2024



One-shot Imitation Learning~(OSIL) aims to imbue AI agents with the ability to learn a new task from a single demonstration. To supervise the learning, OSIL typically requires a prohibitively large number of paired expert demonstrations -- i.e. trajectories corresponding to different variations of the same semantic task. To overcome this limitation, we introduce the semi-supervised OSIL problem setting, where the learning agent is presented with a large dataset of trajectories with no task labels (i.e. an unpaired dataset), along with a small dataset of multiple demonstrations per semantic task (i.e. a paired dataset). This presents a more realistic and practical embodiment of few-shot learning and requires the agent to effectively leverage weak supervision from a large dataset of trajectories. Subsequently, we develop an algorithm specifically applicable to this semi-supervised OSIL setting. Our approach first learns an embedding space where different tasks cluster uniquely. We utilize this embedding space and the clustering it supports to self-generate pairings between trajectories in the large unpaired dataset. Through empirical results on simulated control tasks, we demonstrate that OSIL models trained on such self-generated pairings are competitive with OSIL models trained with ground-truth labels, presenting a major advancement in the label-efficiency of OSIL.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023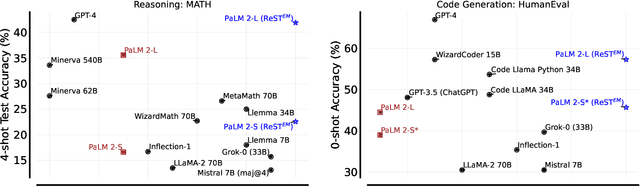
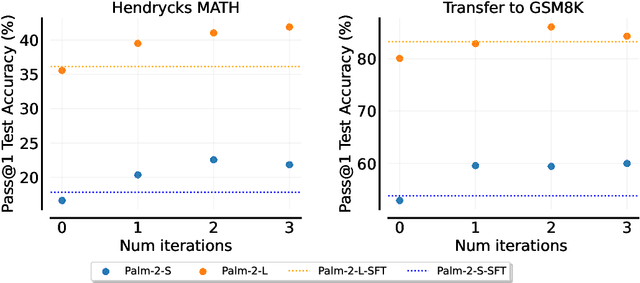
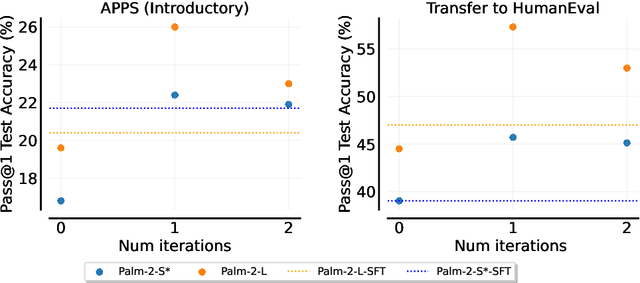
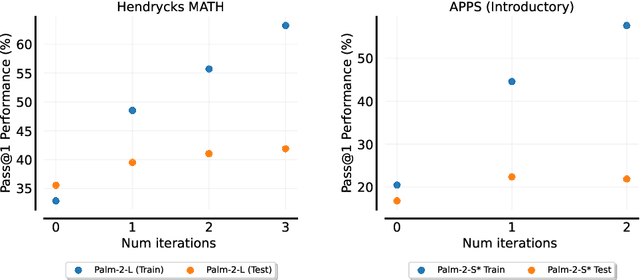
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy
Nov 21, 2023We introduce a machine learning approach to determine the transition dynamics of silicon atoms on a single layer of carbon atoms, when stimulated by the electron beam of a scanning transmission electron microscope (STEM). Our method is data-centric, leveraging data collected on a STEM. The data samples are processed and filtered to produce symbolic representations, which we use to train a neural network to predict transition probabilities. These learned transition dynamics are then leveraged to guide a single silicon atom throughout the lattice to pre-determined target destinations. We present empirical analyses that demonstrate the efficacy and generality of our approach.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).