 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Planning Capabilities through Intrinsic Self-Critique
Dec 30, 2025We demonstrate an approach for LLMs to critique their \emph{own} answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
To Mask or to Mirror: Human-AI Alignment in Collective Reasoning
Oct 02, 2025As large language models (LLMs) are increasingly used to model and augment collective decision-making, it is critical to examine their alignment with human social reasoning. We present an empirical framework for assessing collective alignment, in contrast to prior work on the individual level. Using the Lost at Sea social psychology task, we conduct a large-scale online experiment (N=748), randomly assigning groups to leader elections with either visible demographic attributes (e.g. name, gender) or pseudonymous aliases. We then simulate matched LLM groups conditioned on the human data, benchmarking Gemini 2.5, GPT 4.1, Claude Haiku 3.5, and Gemma 3. LLM behaviors diverge: some mirror human biases; others mask these biases and attempt to compensate for them. We empirically demonstrate that human-AI alignment in collective reasoning depends on context, cues, and model-specific inductive biases. Understanding how LLMs align with collective human behavior is critical to advancing socially-aligned AI, and demands dynamic benchmarks that capture the complexities of collective reasoning.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Dec 22, 2023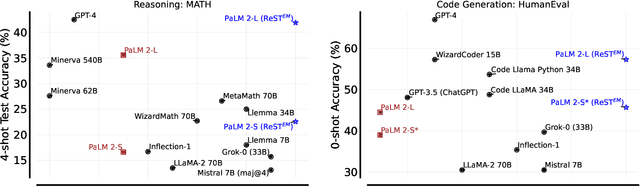
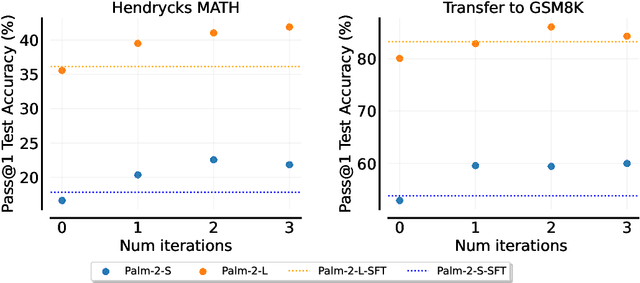
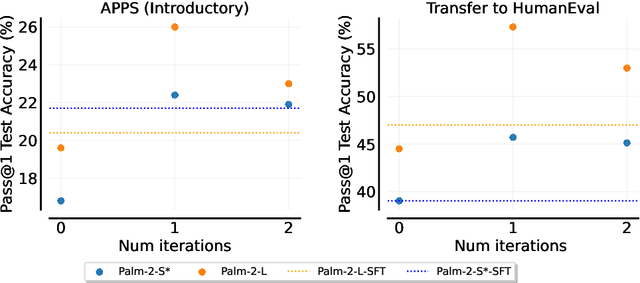
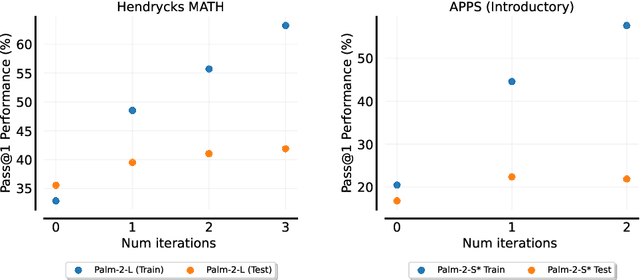
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Training Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023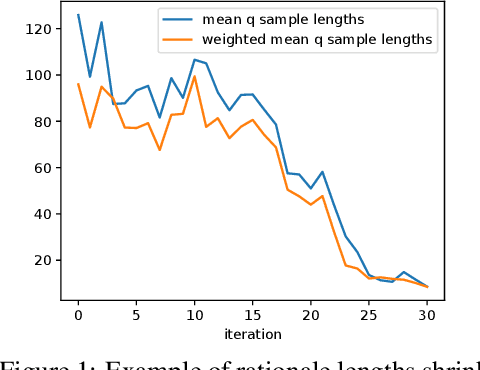
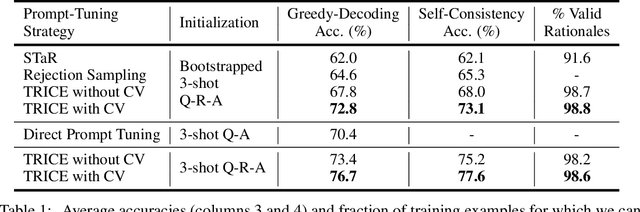
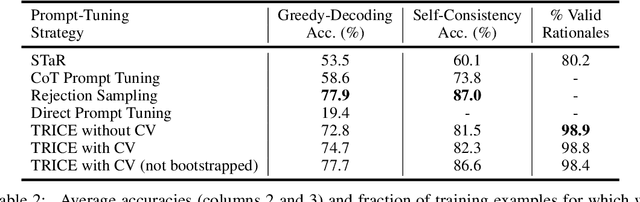
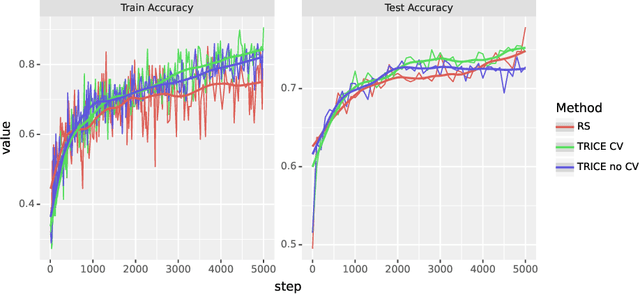
Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
TALM: Tool Augmented Language Models
May 24, 2022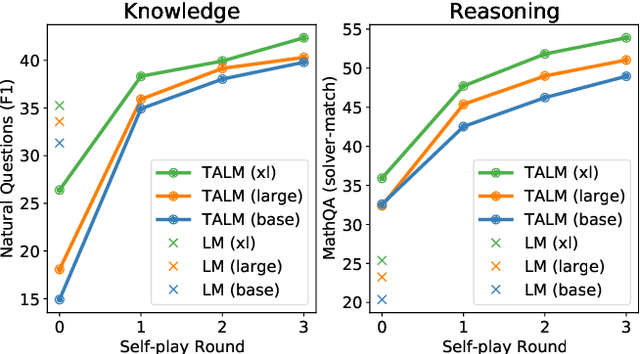
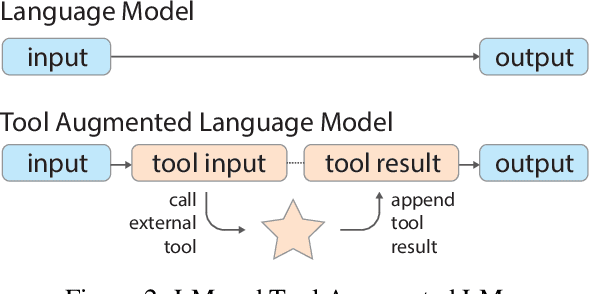


Transformer based language models (LMs) demonstrate increasing performance with scale across a wide variety of tasks. Scale alone however cannot enable models to solve tasks that require access to ephemeral, changing, or private data that was unavailable at training time. Many useful tasks may also benefit from LMs being able to access APIs that read or modify state. In this work, we present Tool Augmented Language Models (TALM), combining a text-only approach to augment language models with non-differentiable tools, and an iterative "self-play" technique to bootstrap performance starting from few tool demonstrations. TALM exhibits strong performance on both a knowledge-heavy QA task and a reasoning oriented math task with simple tools. At a given model scale, TALM significantly outperforms non-augmented LMs. We further demonstrate that TALM successfully performs out-of-distribution inferences on both QA and math tasks, where non-augmented LMs fail. Our results suggest that Tool Augmented Language Models are a promising direction to enrich LMs' capabilities, with less dependence on scale.
Multi-objective evolution for Generalizable Policy Gradient Algorithms
Apr 08, 2022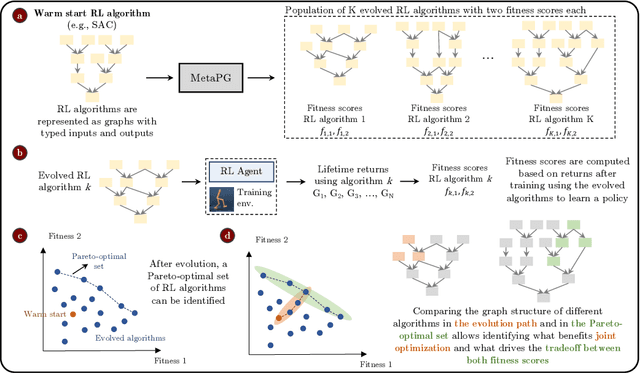
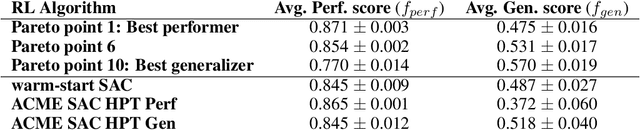
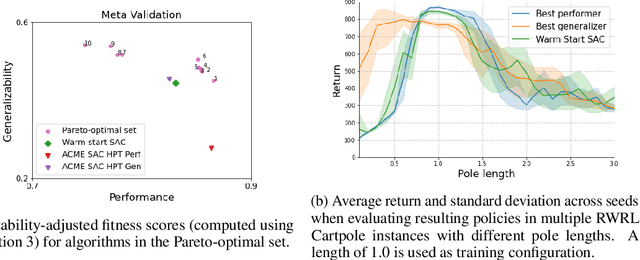
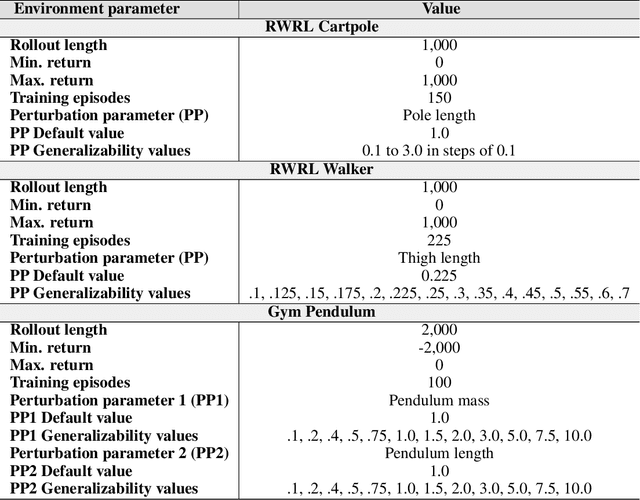
Performance, generalizability, and stability are three Reinforcement Learning (RL) challenges relevant to many practical applications in which they present themselves in combination. Still, state-of-the-art RL algorithms fall short when addressing multiple RL objectives simultaneously and current human-driven design practices might not be well-suited for multi-objective RL. In this paper we present MetaPG, an evolutionary method that discovers new RL algorithms represented as graphs, following a multi-objective search criteria in which different RL objectives are encoded in separate fitness scores. Our findings show that, when using a graph-based implementation of Soft Actor-Critic (SAC) to initialize the population, our method is able to find new algorithms that improve upon SAC's performance and generalizability by 3% and 17%, respectively, and reduce instability up to 65%. In addition, we analyze the graph structure of the best algorithms in the population and offer an interpretation of specific elements that help trading performance for generalizability and vice versa. We validate our findings in three different continuous control tasks: RWRL Cartpole, RWRL Walker, and Gym Pendulum.