 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Planning with Jumpy World Models
Feb 23, 2026The ability to plan with temporal abstractions is central to intelligent decision-making. Rather than reasoning over primitive actions, we study agents that compose pre-trained policies as temporally extended actions, enabling solutions to complex tasks that no constituent alone can solve. Such compositional planning remains elusive as compounding errors in long-horizon predictions make it challenging to estimate the visitation distribution induced by sequencing policies. Motivated by the geometric policy composition framework introduced in arXiv:2206.08736, we address these challenges by learning predictive models of multi-step dynamics -- so-called jumpy world models -- that capture state occupancies induced by pre-trained policies across multiple timescales in an off-policy manner. Building on Temporal Difference Flows (arXiv:2503.09817), we enhance these models with a novel consistency objective that aligns predictions across timescales, improving long-horizon predictive accuracy. We further demonstrate how to combine these generative predictions to estimate the value of executing arbitrary sequences of policies over varying timescales. Empirically, we find that compositional planning with jumpy world models significantly improves zero-shot performance across a wide range of base policies on challenging manipulation and navigation tasks, yielding, on average, a 200% relative improvement over planning with primitive actions on long-horizon tasks.
Tapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
Mar 19, 2025We propose a new algorithm for fine-tuning large language models using reinforcement learning. Tapered Off-Policy REINFORCE (TOPR) uses an asymmetric, tapered variant of importance sampling to speed up learning while maintaining stable learning dynamics, even without the use of KL regularization. TOPR can be applied in a fully offline fashion, allows the handling of positive and negative examples in a unified framework, and benefits from the implementational simplicity that is typical of Monte Carlo algorithms. We demonstrate the effectiveness of our approach with a series of experiments on the GSM8K and MATH reasoning benchmarks, finding performance gains for training both a model for solution generation and as a generative verifier. We show that properly leveraging positive and negative examples alike in the off-policy regime simultaneously increases test-time accuracy and training data efficiency, all the while avoiding the ``wasted inference'' that comes with discarding negative examples. We find that this advantage persists over multiple iterations of training and can be amplified by dataset curation techniques, enabling us to match 70B-parameter model performance with 8B language models. As a corollary to this work, we find that REINFORCE's baseline parameter plays an important and unexpected role in defining dataset composition in the presence of negative examples, and is consequently critical in driving off-policy performance.
Action Gaps and Advantages in Continuous-Time Distributional Reinforcement Learning
Oct 14, 2024When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents are sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the superiority as a probabilistic generalization of the advantage -- the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.
Controlling Large Language Model Agents with Entropic Activation Steering
Jun 01, 2024The generality of pretrained large language models (LLMs) has prompted increasing interest in their use as in-context learning agents. To be successful, such agents must form beliefs about how to achieve their goals based on limited interaction with their environment, resulting in uncertainty about the best action to take at each step. In this paper, we study how LLM agents form and act on these beliefs by conducting experiments in controlled sequential decision-making tasks. To begin, we find that LLM agents are overconfident: They draw strong conclusions about what to do based on insufficient evidence, resulting in inadequately explorative behavior. We dig deeper into this phenomenon and show how it emerges from a collapse in the entropy of the action distribution implied by sampling from the LLM. We then demonstrate that existing token-level sampling techniques are by themselves insufficient to make the agent explore more. Motivated by this fact, we introduce Entropic Activation Steering (EAST), an activation steering method for in-context LLM agents. EAST computes a steering vector as an entropy-weighted combination of representations, and uses it to manipulate an LLM agent's uncertainty over actions by intervening on its activations during the forward pass. We show that EAST can reliably increase the entropy in an LLM agent's actions, causing more explorative behavior to emerge. Finally, EAST modifies the subjective uncertainty an LLM agent expresses, paving the way to interpreting and controlling how LLM agents represent uncertainty about their decisions.
A Distributional Analogue to the Successor Representation
Feb 13, 2024



This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
Learning and Controlling Silicon Dopant Transitions in Graphene using Scanning Transmission Electron Microscopy
Nov 21, 2023We introduce a machine learning approach to determine the transition dynamics of silicon atoms on a single layer of carbon atoms, when stimulated by the electron beam of a scanning transmission electron microscope (STEM). Our method is data-centric, leveraging data collected on a STEM. The data samples are processed and filtered to produce symbolic representations, which we use to train a neural network to predict transition probabilities. These learned transition dynamics are then leveraged to guide a single silicon atom throughout the lattice to pre-determined target destinations. We present empirical analyses that demonstrate the efficacy and generality of our approach.
Small batch deep reinforcement learning
Oct 05, 2023In value-based deep reinforcement learning with replay memories, the batch size parameter specifies how many transitions to sample for each gradient update. Although critical to the learning process, this value is typically not adjusted when proposing new algorithms. In this work we present a broad empirical study that suggests {\em reducing} the batch size can result in a number of significant performance gains; this is surprising, as the general tendency when training neural networks is towards larger batch sizes for improved performance. We complement our experimental findings with a set of empirical analyses towards better understanding this phenomenon.
Policy Optimization in a Noisy Neighborhood: On Return Landscapes in Continuous Control
Sep 26, 2023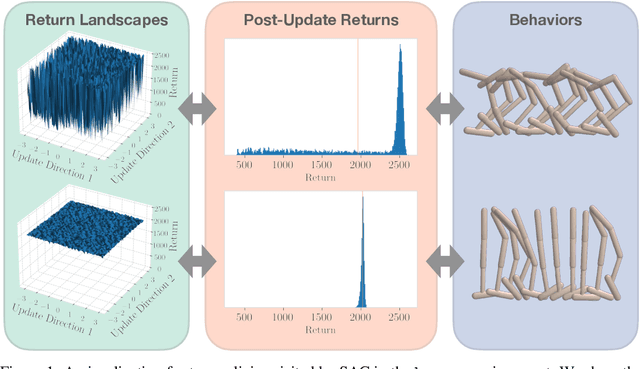
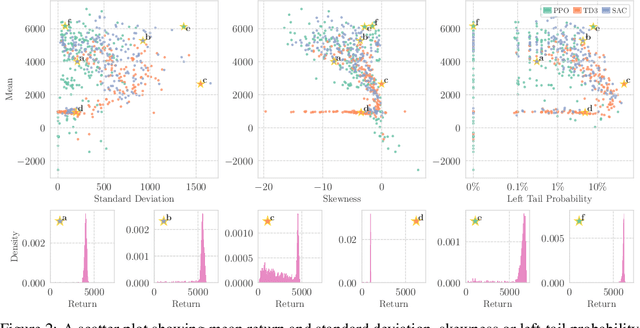
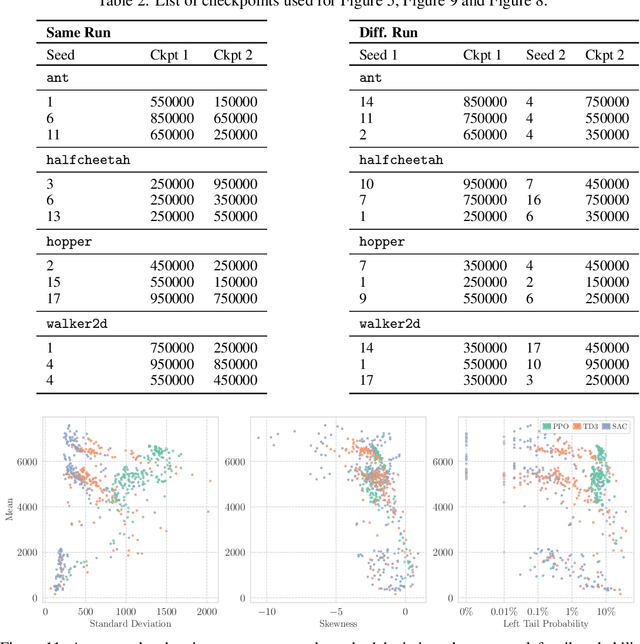
Deep reinforcement learning agents for continuous control are known to exhibit significant instability in their performance over time. In this work, we provide a fresh perspective on these behaviors by studying the return landscape: the mapping between a policy and a return. We find that popular algorithms traverse noisy neighborhoods of this landscape, in which a single update to the policy parameters leads to a wide range of returns. By taking a distributional view of these returns, we map the landscape, characterizing failure-prone regions of policy space and revealing a hidden dimension of policy quality. We show that the landscape exhibits surprising structure by finding simple paths in parameter space which improve the stability of a policy. To conclude, we develop a distribution-aware procedure which finds such paths, navigating away from noisy neighborhoods in order to improve the robustness of a policy. Taken together, our results provide new insight into the optimization, evaluation, and design of agents.
Bootstrapped Representations in Reinforcement Learning
Jun 16, 2023In reinforcement learning (RL), state representations are key to dealing with large or continuous state spaces. While one of the promises of deep learning algorithms is to automatically construct features well-tuned for the task they try to solve, such a representation might not emerge from end-to-end training of deep RL agents. To mitigate this issue, auxiliary objectives are often incorporated into the learning process and help shape the learnt state representation. Bootstrapping methods are today's method of choice to make these additional predictions. Yet, it is unclear which features these algorithms capture and how they relate to those from other auxiliary-task-based approaches. In this paper, we address this gap and provide a theoretical characterization of the state representation learnt by temporal difference learning (Sutton, 1988). Surprisingly, we find that this representation differs from the features learned by Monte Carlo and residual gradient algorithms for most transition structures of the environment in the policy evaluation setting. We describe the efficacy of these representations for policy evaluation, and use our theoretical analysis to design new auxiliary learning rules. We complement our theoretical results with an empirical comparison of these learning rules for different cumulant functions on classic domains such as the four-room domain (Sutton et al, 1999) and Mountain Car (Moore, 1990).
The Statistical Benefits of Quantile Temporal-Difference Learning for Value Estimation
May 28, 2023



We study the problem of temporal-difference-based policy evaluation in reinforcement learning. In particular, we analyse the use of a distributional reinforcement learning algorithm, quantile temporal-difference learning (QTD), for this task. We reach the surprising conclusion that even if a practitioner has no interest in the return distribution beyond the mean, QTD (which learns predictions about the full distribution of returns) may offer performance superior to approaches such as classical TD learning, which predict only the mean return, even in the tabular setting.