 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Deep Reinforcement Learning via Isotropic Gaussian Representations
Feb 22, 2026Deep reinforcement learning systems often suffer from unstable training dynamics due to non-stationarity, where learning objectives and data distributions evolve over time. We show that under non-stationary targets, isotropic Gaussian embeddings are provably advantageous. In particular, they induce stable tracking of time-varying targets for linear readouts, achieve maximal entropy under a fixed variance budget, and encourage a balanced use of all representational dimensions--all of which enable agents to be more adaptive and stable. Building on this insight, we propose the use of Sketched Isotropic Gaussian Regularization for shaping representations toward an isotropic Gaussian distribution during training. We demonstrate empirically, over a variety of domains, that this simple and computationally inexpensive method improves performance under non-stationarity while reducing representation collapse, neuron dormancy, and training instability.
A Comedy of Estimators: On KL Regularization in RL Training of LLMs
Dec 26, 2025The reasoning performance of large language models (LLMs) can be substantially improved by training them with reinforcement learning (RL). The RL objective for LLM training involves a regularization term, which is the reverse Kullback-Leibler (KL) divergence between the trained policy and the reference policy. Since computing the KL divergence exactly is intractable, various estimators are used in practice to estimate it from on-policy samples. Despite its wide adoption, including in several open-source libraries, there is no systematic study analyzing the numerous ways of incorporating KL estimators in the objective and their effect on the downstream performance of RL-trained models. Recent works show that prevailing practices for incorporating KL regularization do not provide correct gradients for stated objectives, creating a discrepancy between the objective and its implementation. In this paper, we further analyze these practices and study the gradients of several estimators configurations, revealing how design choices shape gradient bias. We substantiate these findings with empirical observations by RL fine-tuning \texttt{Qwen2.5-7B}, \texttt{Llama-3.1-8B-Instruct} and \texttt{Qwen3-4B-Instruct-2507} with different configurations and evaluating their performance on both in- and out-of-distribution tasks. Through our analysis, we observe that, in on-policy settings: (1) estimator configurations with biased gradients can result in training instabilities; and (2) using estimator configurations resulting in unbiased gradients leads to better performance on in-domain as well as out-of-domain tasks. We also investigate the performance resulting from different KL configurations in off-policy settings and observe that KL regularization can help stabilize off-policy RL training resulting from asynchronous setups.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
Oct 02, 2025Most recent RL for LLMs (RL4LLM) methods avoid explicit critics, replacing them with average advantage baselines. This shift is largely pragmatic: conventional value functions are computationally expensive to train at LLM scale and often fail under sparse rewards and long reasoning horizons. We revisit this bottleneck from an architectural perspective and introduce Asymmetric Proximal Policy Optimization (AsyPPO), a simple and scalable framework that restores the critics role while remaining efficient in large-model settings. AsyPPO employs a set of lightweight mini-critics, each trained on disjoint prompt shards. This design encourages diversity while preserving calibration, reducing value-estimation bias. Beyond robust estimation, AsyPPO leverages inter-critic uncertainty to refine the policy update: (i) masking advantages in states where critics agree and gradients add little learning signal, and (ii) filtering high-divergence states from entropy regularization, suppressing spurious exploration. After training on open-source data with only 5,000 samples, AsyPPO consistently improves learning stability and performance across multiple benchmarks over strong baselines, such as GRPO, achieving performance gains of more than six percent on Qwen3-4b-Base and about three percent on Qwen3-8b-Base and Qwen3-14b-Base over classic PPO, without additional tricks. These results highlight the importance of architectural innovations for scalable, efficient algorithms.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning
Jun 18, 2025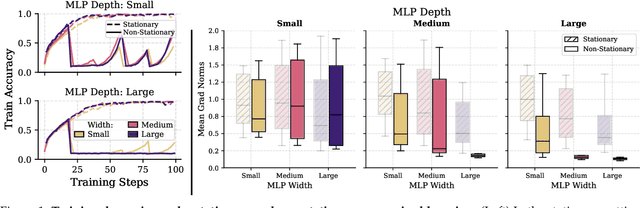
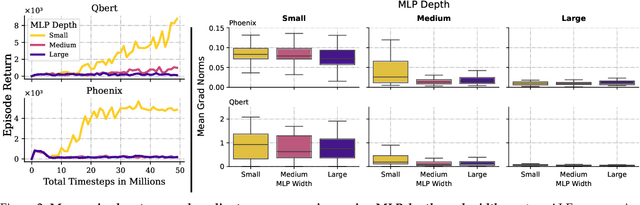
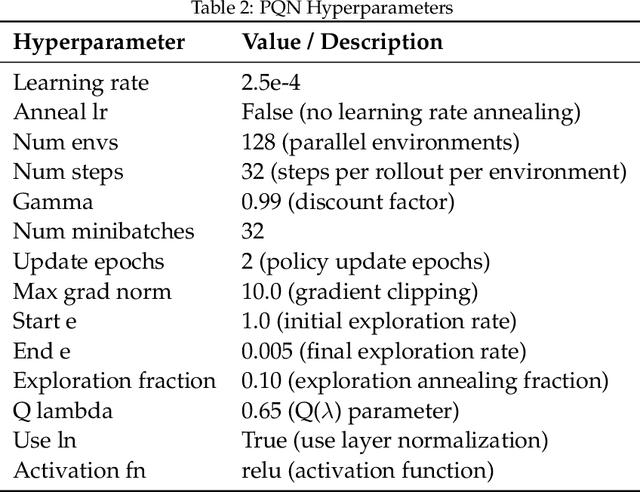
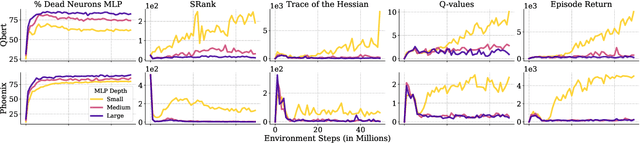
Scaling deep reinforcement learning networks is challenging and often results in degraded performance, yet the root causes of this failure mode remain poorly understood. Several recent works have proposed mechanisms to address this, but they are often complex and fail to highlight the causes underlying this difficulty. In this work, we conduct a series of empirical analyses which suggest that the combination of non-stationarity with gradient pathologies, due to suboptimal architectural choices, underlie the challenges of scale. We propose a series of direct interventions that stabilize gradient flow, enabling robust performance across a range of network depths and widths. Our interventions are simple to implement and compatible with well-established algorithms, and result in an effective mechanism that enables strong performance even at large scales. We validate our findings on a variety of agents and suites of environments.
The Courage to Stop: Overcoming Sunk Cost Fallacy in Deep Reinforcement Learning
Jun 16, 2025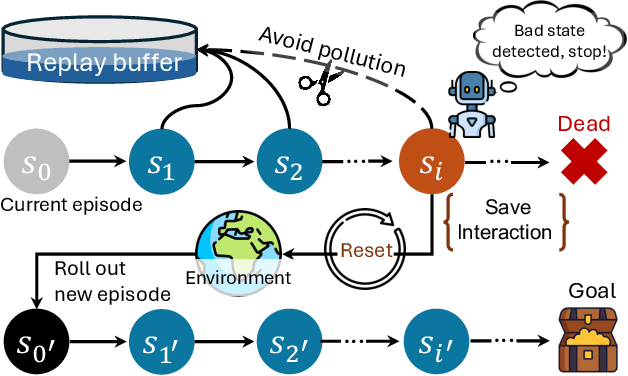
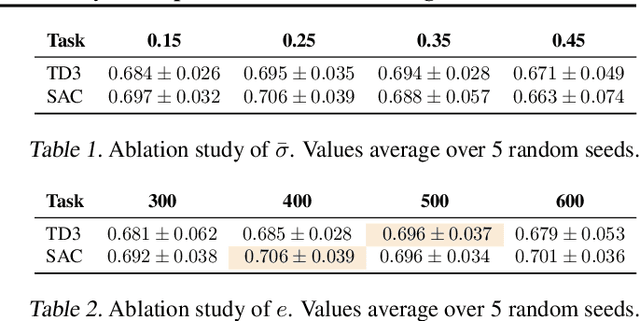
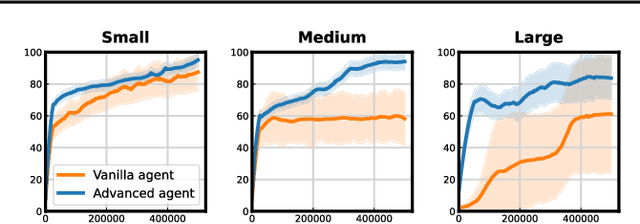
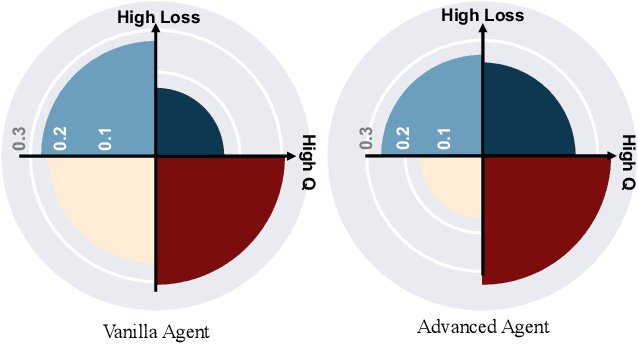
Off-policy deep reinforcement learning (RL) typically leverages replay buffers for reusing past experiences during learning. This can help improve sample efficiency when the collected data is informative and aligned with the learning objectives; when that is not the case, it can have the effect of "polluting" the replay buffer with data which can exacerbate optimization challenges in addition to wasting environment interactions due to wasteful sampling. We argue that sampling these uninformative and wasteful transitions can be avoided by addressing the sunk cost fallacy, which, in the context of deep RL, is the tendency towards continuing an episode until termination. To address this, we propose learn to stop (LEAST), a lightweight mechanism that enables strategic early episode termination based on Q-value and gradient statistics, which helps agents recognize when to terminate unproductive episodes early. We demonstrate that our method improves learning efficiency on a variety of RL algorithms, evaluated on both the MuJoCo and DeepMind Control Suite benchmarks.
Measure gradients, not activations! Enhancing neuronal activity in deep reinforcement learning
May 29, 2025Deep reinforcement learning (RL) agents frequently suffer from neuronal activity loss, which impairs their ability to adapt to new data and learn continually. A common method to quantify and address this issue is the tau-dormant neuron ratio, which uses activation statistics to measure the expressive ability of neurons. While effective for simple MLP-based agents, this approach loses statistical power in more complex architectures. To address this, we argue that in advanced RL agents, maintaining a neuron's learning capacity, its ability to adapt via gradient updates, is more critical than preserving its expressive ability. Based on this insight, we shift the statistical objective from activations to gradients, and introduce GraMa (Gradient Magnitude Neural Activity Metric), a lightweight, architecture-agnostic metric for quantifying neuron-level learning capacity. We show that GraMa effectively reveals persistent neuron inactivity across diverse architectures, including residual networks, diffusion models, and agents with varied activation functions. Moreover, resetting neurons guided by GraMa (ReGraMa) consistently improves learning performance across multiple deep RL algorithms and benchmarks, such as MuJoCo and the DeepMind Control Suite.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
Adaptive Computation Pruning for the Forgetting Transformer
Apr 09, 2025The recently proposed Forgetting Transformer (FoX) incorporates a forget gate into softmax attention and has shown consistently better or on-par performance compared to the standard RoPE-based Transformer. Notably, many attention heads in FoX tend to forget quickly, causing their output at each timestep to rely primarily on the local context. Based on this observation, we propose Adaptive Computation Pruning (ACP) for FoX, a method that dynamically prunes computations involving input-output dependencies that are strongly decayed by the forget gate. This is achieved using a dynamically set pruning threshold that ensures that the pruned attention weights remain negligible. We apply ACP to language model pretraining with FoX and show it consistently reduces the number of FLOPs in softmax attention by around 70% across different model sizes and context lengths, resulting in a roughly 10% to 35% improvement in training throughput. Furthermore, longer context lengths yield greater computational savings. All these speed improvements are achieved without any performance degradation. We also perform several analyses to provide deeper insights into our method, such as examining the pruning patterns and analyzing the distribution of FLOP savings across different attention heads. Our code is available at https://github.com/zhixuan-lin/arctic-fox.