 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Large Language Model Agents with Entropic Activation Steering
Jun 01, 2024The generality of pretrained large language models (LLMs) has prompted increasing interest in their use as in-context learning agents. To be successful, such agents must form beliefs about how to achieve their goals based on limited interaction with their environment, resulting in uncertainty about the best action to take at each step. In this paper, we study how LLM agents form and act on these beliefs by conducting experiments in controlled sequential decision-making tasks. To begin, we find that LLM agents are overconfident: They draw strong conclusions about what to do based on insufficient evidence, resulting in inadequately explorative behavior. We dig deeper into this phenomenon and show how it emerges from a collapse in the entropy of the action distribution implied by sampling from the LLM. We then demonstrate that existing token-level sampling techniques are by themselves insufficient to make the agent explore more. Motivated by this fact, we introduce Entropic Activation Steering (EAST), an activation steering method for in-context LLM agents. EAST computes a steering vector as an entropy-weighted combination of representations, and uses it to manipulate an LLM agent's uncertainty over actions by intervening on its activations during the forward pass. We show that EAST can reliably increase the entropy in an LLM agent's actions, causing more explorative behavior to emerge. Finally, EAST modifies the subjective uncertainty an LLM agent expresses, paving the way to interpreting and controlling how LLM agents represent uncertainty about their decisions.
Policy Optimization in a Noisy Neighborhood: On Return Landscapes in Continuous Control
Sep 26, 2023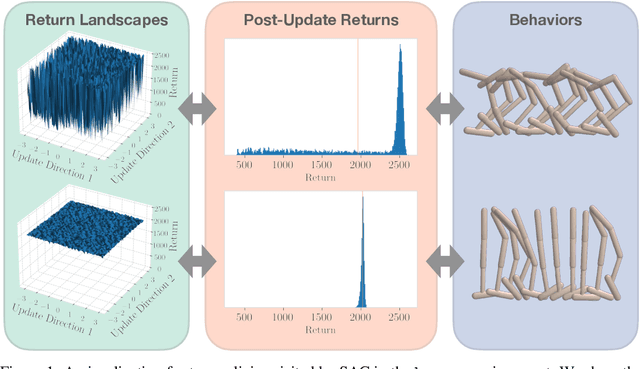
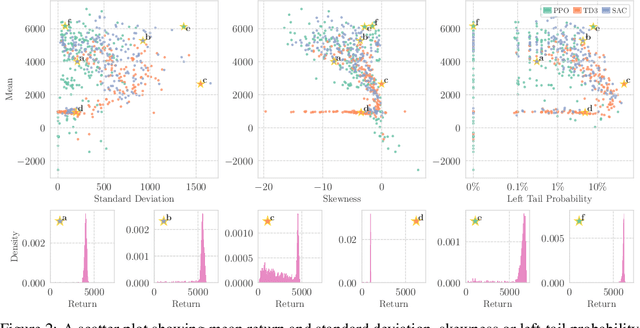
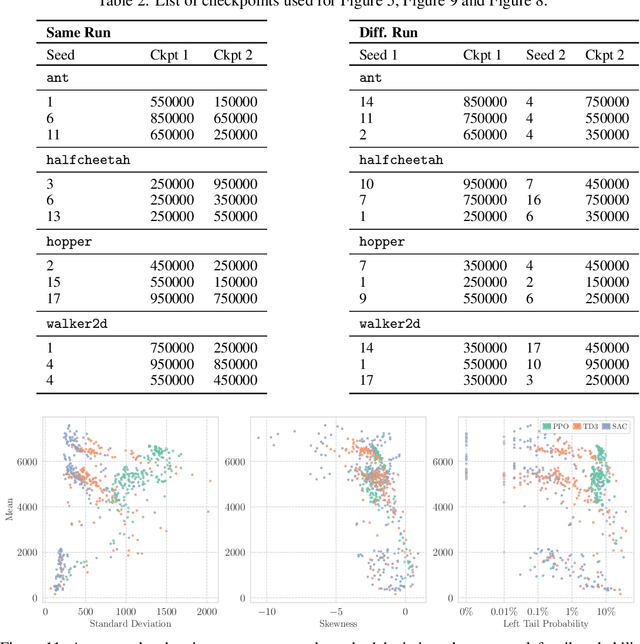
Deep reinforcement learning agents for continuous control are known to exhibit significant instability in their performance over time. In this work, we provide a fresh perspective on these behaviors by studying the return landscape: the mapping between a policy and a return. We find that popular algorithms traverse noisy neighborhoods of this landscape, in which a single update to the policy parameters leads to a wide range of returns. By taking a distributional view of these returns, we map the landscape, characterizing failure-prone regions of policy space and revealing a hidden dimension of policy quality. We show that the landscape exhibits surprising structure by finding simple paths in parameter space which improve the stability of a policy. To conclude, we develop a distribution-aware procedure which finds such paths, navigating away from noisy neighborhoods in order to improve the robustness of a policy. Taken together, our results provide new insight into the optimization, evaluation, and design of agents.