 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Gymnast: Training Robots with Reinforcement Learning in a World Model
Feb 02, 2026Robot learning from interacting with the physical world is fundamentally bottlenecked by the cost of physical interaction. The two alternatives, supervised finetuning (SFT) from expert demonstrations and reinforcement learning (RL) in a software-based simulator, are limited by the amount of expert data available and the sim-to-real gap for manipulation. With the recent emergence of world models learned from real-world video-action data, we ask the question of whether training a policy in a world model can be more effective than supervised learning or software simulation in achieving better real-robot performance. We propose World-Gymnast, which performs RL finetuning of a vision-language-action (VLA) policy by rolling out the policy in an action-conditioned video world model and rewarding the rollouts with a vision-language model (VLM). On the Bridge robot setup, World-Gymnast outperforms SFT by as much as 18x and outperforms software simulator by as much as 2x. More importantly, World-Gymnast demonstrates intriguing capabilities of RL with a world model, including training on diverse language instructions and novel scenes from the world model, test-time training in a novel scene, and online iterative world model and policy improvement. Our results suggest learning a world model and training robot policies in the cloud could be the key to bridging the gap between robots that work in demonstrations and robots that can work in anyone's household.
World Models as an Intermediary between Agents and the Real World
Jan 31, 2026Large language model (LLM) agents trained using reinforcement learning has achieved superhuman performance in low-cost environments like games, mathematics, and coding. However, these successes have not translated to complex domains where the cost of interaction is high, such as the physical cost of running robots, the time cost of ML engineering, and the resource cost of scientific experiments. The true bottleneck for achieving the next level of agent performance for these complex and high-cost domains lies in the expense of executing actions to acquire reward signals. To address this gap, this paper argues that we should use world models as an intermediary between agents and the real world. We discuss how world models, viewed as models of dynamics, rewards, and task distributions, can overcome fundamental barriers of high-cost actions such as extreme off-policy learning and sample inefficiency in long-horizon tasks. Moreover, we demonstrate how world models can provide critical and rich learning signals to agents across a broad set of domains, including machine learning engineering, computer use, robotics, and AI for science. Lastly, we identify the challenges of building these world models and propose actionable items along dataset curation, architecture design, scaling, and evaluation of world models.
Evaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
MLE-Smith: Scaling MLE Tasks with Automated Multi-Agent Pipeline
Oct 08, 2025While Language Models (LMs) have made significant progress in automating machine learning engineering (MLE), the acquisition of high-quality MLE training data is significantly constrained. Current MLE benchmarks suffer from low scalability and limited applicability because they rely on static, manually curated tasks, demanding extensive time and manual effort to produce. We introduce MLE-Smith, a fully automated multi-agent pipeline, to transform raw datasets into competition-style MLE challenges through an efficient generate-verify-execute paradigm for scaling MLE tasks with verifiable quality, real-world usability, and rich diversity. The proposed multi-agent pipeline in MLE-Smith drives structured task design and standardized refactoring, coupled with a hybrid verification mechanism that enforces strict structural rules and high-level semantic soundness. It further validates empirical solvability and real-world fidelity through interactive execution. We apply MLE-Smith to 224 of real-world datasets and generate 606 tasks spanning multiple categories, objectives, and modalities, demonstrating that MLE-Smith can work effectively across a wide range of real-world datasets. Evaluation on the generated tasks shows that the performance of eight mainstream and cutting-edge LLMs on MLE-Smith tasks is strongly correlated with their performance on carefully human-designed tasks, highlighting the effectiveness of the MLE-Smith to scaling up MLE tasks, while maintaining task quality.
Object-centric 3D Motion Field for Robot Learning from Human Videos
Jun 04, 2025Learning robot control policies from human videos is a promising direction for scaling up robot learning. However, how to extract action knowledge (or action representations) from videos for policy learning remains a key challenge. Existing action representations such as video frames, pixelflow, and pointcloud flow have inherent limitations such as modeling complexity or loss of information. In this paper, we propose to use object-centric 3D motion field to represent actions for robot learning from human videos, and present a novel framework for extracting this representation from videos for zero-shot control. We introduce two novel components in its implementation. First, a novel training pipeline for training a ''denoising'' 3D motion field estimator to extract fine object 3D motions from human videos with noisy depth robustly. Second, a dense object-centric 3D motion field prediction architecture that favors both cross-embodiment transfer and policy generalization to background. We evaluate the system in real world setups. Experiments show that our method reduces 3D motion estimation error by over 50% compared to the latest method, achieve 55% average success rate in diverse tasks where prior approaches fail~($\lesssim 10$\%), and can even acquire fine-grained manipulation skills like insertion.
MLE-Dojo: Interactive Environments for Empowering LLM Agents in Machine Learning Engineering
May 12, 2025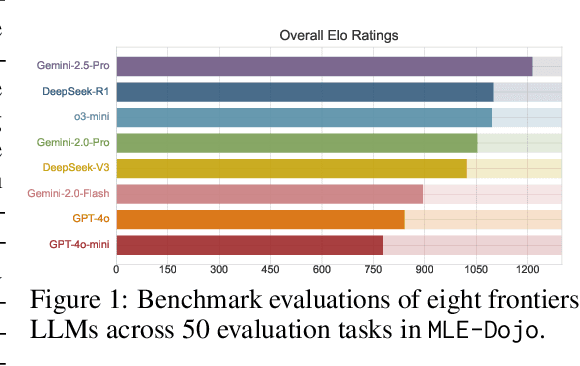



We introduce MLE-Dojo, a Gym-style framework for systematically reinforcement learning, evaluating, and improving autonomous large language model (LLM) agents in iterative machine learning engineering (MLE) workflows. Unlike existing benchmarks that primarily rely on static datasets or single-attempt evaluations, MLE-Dojo provides an interactive environment enabling agents to iteratively experiment, debug, and refine solutions through structured feedback loops. Built upon 200+ real-world Kaggle challenges, MLE-Dojo covers diverse, open-ended MLE tasks carefully curated to reflect realistic engineering scenarios such as data processing, architecture search, hyperparameter tuning, and code debugging. Its fully executable environment supports comprehensive agent training via both supervised fine-tuning and reinforcement learning, facilitating iterative experimentation, realistic data sampling, and real-time outcome verification. Extensive evaluations of eight frontier LLMs reveal that while current models achieve meaningful iterative improvements, they still exhibit significant limitations in autonomously generating long-horizon solutions and efficiently resolving complex errors. Furthermore, MLE-Dojo's flexible and extensible architecture seamlessly integrates diverse data sources, tools, and evaluation protocols, uniquely enabling model-based agent tuning and promoting interoperability, scalability, and reproducibility. We open-source our framework and benchmarks to foster community-driven innovation towards next-generation MLE agents.
System of Agentic AI for the Discovery of Metal-Organic Frameworks
Apr 18, 2025Generative models and machine learning promise accelerated material discovery in MOFs for CO2 capture and water harvesting but face significant challenges navigating vast chemical spaces while ensuring synthetizability. Here, we present MOFGen, a system of Agentic AI comprising interconnected agents: a large language model that proposes novel MOF compositions, a diffusion model that generates crystal structures, quantum mechanical agents that optimize and filter candidates, and synthetic-feasibility agents guided by expert rules and machine learning. Trained on all experimentally reported MOFs and computational databases, MOFGen generated hundreds of thousands of novel MOF structures and synthesizable organic linkers. Our methodology was validated through high-throughput experiments and the successful synthesis of five "AI-dreamt" MOFs, representing a major step toward automated synthesizable material discovery.
Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback
Dec 03, 2024

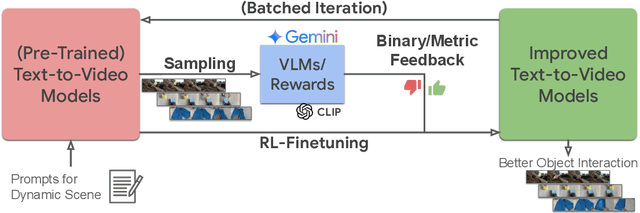

Large text-to-video models hold immense potential for a wide range of downstream applications. However, these models struggle to accurately depict dynamic object interactions, often resulting in unrealistic movements and frequent violations of real-world physics. One solution inspired by large language models is to align generated outputs with desired outcomes using external feedback. This enables the model to refine its responses autonomously, eliminating extensive manual data collection. In this work, we investigate the use of feedback to enhance the object dynamics in text-to-video models. We aim to answer a critical question: what types of feedback, paired with which specific self-improvement algorithms, can most effectively improve text-video alignment and realistic object interactions? We begin by deriving a unified probabilistic objective for offline RL finetuning of text-to-video models. This perspective highlights how design elements in existing algorithms like KL regularization and policy projection emerge as specific choices within a unified framework. We then use derived methods to optimize a set of text-video alignment metrics (e.g., CLIP scores, optical flow), but notice that they often fail to align with human perceptions of generation quality. To address this limitation, we propose leveraging vision-language models to provide more nuanced feedback specifically tailored to object dynamics in videos. Our experiments demonstrate that our method can effectively optimize a wide variety of rewards, with binary AI feedback driving the most significant improvements in video quality for dynamic interactions, as confirmed by both AI and human evaluations. Notably, we observe substantial gains when using reward signals derived from AI feedback, particularly in scenarios involving complex interactions between multiple objects and realistic depictions of objects falling.
VideoAgent: Self-Improving Video Generation
Oct 15, 2024



Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
Generative Hierarchical Materials Search
Sep 10, 2024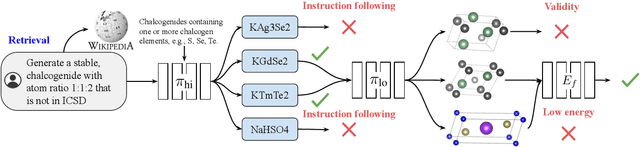



Generative models trained at scale can now produce text, video, and more recently, scientific data such as crystal structures. In applications of generative approaches to materials science, and in particular to crystal structures, the guidance from the domain expert in the form of high-level instructions can be essential for an automated system to output candidate crystals that are viable for downstream research. In this work, we formulate end-to-end language-to-structure generation as a multi-objective optimization problem, and propose Generative Hierarchical Materials Search (GenMS) for controllable generation of crystal structures. GenMS consists of (1) a language model that takes high-level natural language as input and generates intermediate textual information about a crystal (e.g., chemical formulae), and (2) a diffusion model that takes intermediate information as input and generates low-level continuous value crystal structures. GenMS additionally uses a graph neural network to predict properties (e.g., formation energy) from the generated crystal structures. During inference, GenMS leverages all three components to conduct a forward tree search over the space of possible structures. Experiments show that GenMS outperforms other alternatives of directly using language models to generate structures both in satisfying user request and in generating low-energy structures. We confirm that GenMS is able to generate common crystal structures such as double perovskites, or spinels, solely from natural language input, and hence can form the foundation for more complex structure generation in near future.