 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLE-Smith: Scaling MLE Tasks with Automated Multi-Agent Pipeline
Oct 08, 2025While Language Models (LMs) have made significant progress in automating machine learning engineering (MLE), the acquisition of high-quality MLE training data is significantly constrained. Current MLE benchmarks suffer from low scalability and limited applicability because they rely on static, manually curated tasks, demanding extensive time and manual effort to produce. We introduce MLE-Smith, a fully automated multi-agent pipeline, to transform raw datasets into competition-style MLE challenges through an efficient generate-verify-execute paradigm for scaling MLE tasks with verifiable quality, real-world usability, and rich diversity. The proposed multi-agent pipeline in MLE-Smith drives structured task design and standardized refactoring, coupled with a hybrid verification mechanism that enforces strict structural rules and high-level semantic soundness. It further validates empirical solvability and real-world fidelity through interactive execution. We apply MLE-Smith to 224 of real-world datasets and generate 606 tasks spanning multiple categories, objectives, and modalities, demonstrating that MLE-Smith can work effectively across a wide range of real-world datasets. Evaluation on the generated tasks shows that the performance of eight mainstream and cutting-edge LLMs on MLE-Smith tasks is strongly correlated with their performance on carefully human-designed tasks, highlighting the effectiveness of the MLE-Smith to scaling up MLE tasks, while maintaining task quality.
Towards Better Instruction Following Retrieval Models
May 27, 2025



Modern information retrieval (IR) models, trained exclusively on standard <query, passage> pairs, struggle to effectively interpret and follow explicit user instructions. We introduce InF-IR, a large-scale, high-quality training corpus tailored for enhancing retrieval models in Instruction-Following IR. InF-IR expands traditional training pairs into over 38,000 expressive <instruction, query, passage> triplets as positive samples. In particular, for each positive triplet, we generate two additional hard negative examples by poisoning both instructions and queries, then rigorously validated by an advanced reasoning model (o3-mini) to ensure semantic plausibility while maintaining instructional incorrectness. Unlike existing corpora that primarily support computationally intensive reranking tasks for decoder-only language models, the highly contrastive positive-negative triplets in InF-IR further enable efficient representation learning for smaller encoder-only models, facilitating direct embedding-based retrieval. Using this corpus, we train InF-Embed, an instruction-aware Embedding model optimized through contrastive learning and instruction-query attention mechanisms to align retrieval outcomes precisely with user intents. Extensive experiments across five instruction-based retrieval benchmarks demonstrate that InF-Embed significantly surpasses competitive baselines by 8.1% in p-MRR, measuring the instruction-following capabilities.
MLE-Dojo: Interactive Environments for Empowering LLM Agents in Machine Learning Engineering
May 12, 2025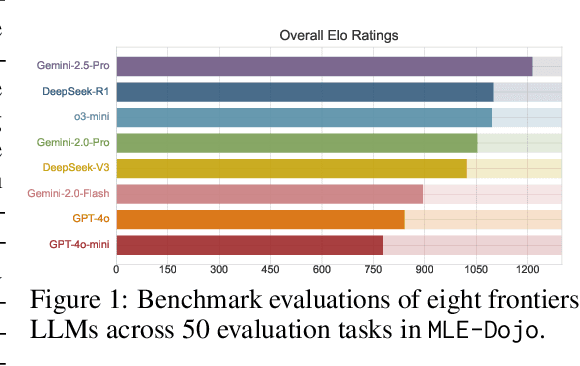



We introduce MLE-Dojo, a Gym-style framework for systematically reinforcement learning, evaluating, and improving autonomous large language model (LLM) agents in iterative machine learning engineering (MLE) workflows. Unlike existing benchmarks that primarily rely on static datasets or single-attempt evaluations, MLE-Dojo provides an interactive environment enabling agents to iteratively experiment, debug, and refine solutions through structured feedback loops. Built upon 200+ real-world Kaggle challenges, MLE-Dojo covers diverse, open-ended MLE tasks carefully curated to reflect realistic engineering scenarios such as data processing, architecture search, hyperparameter tuning, and code debugging. Its fully executable environment supports comprehensive agent training via both supervised fine-tuning and reinforcement learning, facilitating iterative experimentation, realistic data sampling, and real-time outcome verification. Extensive evaluations of eight frontier LLMs reveal that while current models achieve meaningful iterative improvements, they still exhibit significant limitations in autonomously generating long-horizon solutions and efficiently resolving complex errors. Furthermore, MLE-Dojo's flexible and extensible architecture seamlessly integrates diverse data sources, tools, and evaluation protocols, uniquely enabling model-based agent tuning and promoting interoperability, scalability, and reproducibility. We open-source our framework and benchmarks to foster community-driven innovation towards next-generation MLE agents.
Language Model Uncertainty Quantification with Attention Chain
Mar 24, 2025Accurately quantifying a large language model's (LLM) predictive uncertainty is crucial for judging the reliability of its answers. While most existing research focuses on short, directly answerable questions with closed-form outputs (e.g., multiple-choice), involving intermediate reasoning steps in LLM responses is increasingly important. This added complexity complicates uncertainty quantification (UQ) because the probabilities assigned to answer tokens are conditioned on a vast space of preceding reasoning tokens. Direct marginalization is infeasible, and the dependency inflates probability estimates, causing overconfidence in UQ. To address this, we propose UQAC, an efficient method that narrows the reasoning space to a tractable size for marginalization. UQAC iteratively constructs an "attention chain" of tokens deemed "semantically crucial" to the final answer via a backtracking procedure. Starting from the answer tokens, it uses attention weights to identify the most influential predecessors, then iterates this process until reaching the input tokens. Similarity filtering and probability thresholding further refine the resulting chain, allowing us to approximate the marginal probabilities of the answer tokens, which serve as the LLM's confidence. We validate UQAC on multiple reasoning benchmarks with advanced open-source LLMs, demonstrating that it consistently delivers reliable UQ estimates with high computational efficiency.
Matryoshka: Learning to Drive Black-Box LLMs with LLMs
Oct 28, 2024Despite the impressive generative abilities of black-box large language models (LLMs), their inherent opacity hinders further advancements in capabilities such as reasoning, planning, and personalization. Existing works aim to enhance LLM capabilities via domain-specific adaptation or in-context learning, which require additional training on accessible model parameters, an infeasible option for black-box LLMs. To address this challenge, we introduce Matryoshika, a lightweight white-box LLM controller that guides a large-scale black-box LLM generator by decomposing complex tasks into a series of intermediate outputs. Specifically, we consider the black-box LLM as an environment, with Matryoshika serving as a policy to provide intermediate guidance through prompts for driving the black-box LLM. Matryoshika is trained to pivot the outputs of the black-box LLM aligning with preferences during iterative interaction, which enables controllable multi-turn generation and self-improvement in optimizing intermediate guidance. Empirical evaluations on three diverse tasks demonstrate that Matryoshika effectively enhances the capabilities of black-box LLMs in complex, long-horizon tasks, including reasoning, planning, and personalization. By leveraging this pioneering controller-generator framework to mitigate dependence on model parameters, Matryoshika provides a transparent and practical solution for improving black-box LLMs through controllable multi-turn generation using white-box LLMs.
BiLoRA: A Bi-level Optimization Framework for Overfitting-Resilient Low-Rank Adaptation of Large Pre-trained Models
Mar 19, 2024Low-rank adaptation (LoRA) is a popular method for fine-tuning large-scale pre-trained models in downstream tasks by learning low-rank incremental matrices. Though LoRA and its variants effectively reduce the number of trainable parameters compared to full fine-tuning methods, they often overfit training data, resulting in sub-optimal generalization on test data. To address this problem, we introduce BiLoRA, an overfitting-alleviating fine-tuning approach based on bi-level optimization (BLO). BiLoRA employs pseudo singular value decomposition to parameterize low-rank incremental matrices and splits the training of pseudo singular vectors and values across two different subsets of training data. This division, embedded within separate levels of the BLO framework, mitigates the risk of overfitting to a single dataset. Tested on ten datasets covering natural language understanding and generation tasks and applied to various well-known large pre-trained models, BiLoRA significantly outperforms LoRA methods and other fine-tuning approaches, with similar amounts of trainable parameters.
AutoLoRA: Automatically Tuning Matrix Ranks in Low-Rank Adaptation Based on Meta Learning
Mar 17, 2024



Large-scale pretraining followed by task-specific finetuning has achieved great success in various NLP tasks. Since finetuning all parameters of large pretrained models poses substantial computational and memory challenges, several efficient finetuning methods have been developed. Among them, low-rank adaptation (LoRA), which finetunes low-rank incremental update matrices on top of frozen pretrained weights, has proven particularly effective. Nonetheless, LoRA's uniform rank assignment across all layers, along with its reliance on an exhaustive search to find the best rank, leads to high computation costs and suboptimal finetuning performance. To address these limitations, we introduce AutoLoRA, a meta learning based framework for automatically identifying the optimal rank of each LoRA layer. AutoLoRA associates each rank-1 matrix in a low-rank update matrix with a selection variable, which determines whether the rank-1 matrix should be discarded. A meta learning based method is developed to learn these selection variables. The optimal rank is determined by thresholding the values of these variables. Our comprehensive experiments on natural language understanding, generation, and sequence labeling demonstrate the effectiveness of AutoLoRA.