 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Representation-based Reinforcement Learning
Dec 17, 2025In real-world applications with large state and action spaces, reinforcement learning (RL) typically employs function approximations to represent core components like the policies, value functions, and dynamics models. Although powerful approximations such as neural networks offer great expressiveness, they often present theoretical ambiguities, suffer from optimization instability and exploration difficulty, and incur substantial computational costs in practice. In this paper, we introduce the perspective of spectral representations as a solution to address these difficulties in RL. Stemming from the spectral decomposition of the transition operator, this framework yields an effective abstraction of the system dynamics for subsequent policy optimization while also providing a clear theoretical characterization. We reveal how to construct spectral representations for transition operators that possess latent variable structures or energy-based structures, which implies different learning methods to extract spectral representations from data. Notably, each of these learning methods realizes an effective RL algorithm under this framework. We also provably extend this spectral view to partially observable MDPs. Finally, we validate these algorithms on over 20 challenging tasks from the DeepMind Control Suite, where they achieve performances comparable or superior to current state-of-the-art model-free and model-based baselines.
Towards Better Instruction Following Retrieval Models
May 27, 2025Modern information retrieval (IR) models, trained exclusively on standard <query, passage> pairs, struggle to effectively interpret and follow explicit user instructions. We introduce InF-IR, a large-scale, high-quality training corpus tailored for enhancing retrieval models in Instruction-Following IR. InF-IR expands traditional training pairs into over 38,000 expressive <instruction, query, passage> triplets as positive samples. In particular, for each positive triplet, we generate two additional hard negative examples by poisoning both instructions and queries, then rigorously validated by an advanced reasoning model (o3-mini) to ensure semantic plausibility while maintaining instructional incorrectness. Unlike existing corpora that primarily support computationally intensive reranking tasks for decoder-only language models, the highly contrastive positive-negative triplets in InF-IR further enable efficient representation learning for smaller encoder-only models, facilitating direct embedding-based retrieval. Using this corpus, we train InF-Embed, an instruction-aware Embedding model optimized through contrastive learning and instruction-query attention mechanisms to align retrieval outcomes precisely with user intents. Extensive experiments across five instruction-based retrieval benchmarks demonstrate that InF-Embed significantly surpasses competitive baselines by 8.1% in p-MRR, measuring the instruction-following capabilities.
AmorLIP: Efficient Language-Image Pretraining via Amortization
May 25, 2025



Contrastive Language-Image Pretraining (CLIP) has demonstrated strong zero-shot performance across diverse downstream text-image tasks. Existing CLIP methods typically optimize a contrastive objective using negative samples drawn from each minibatch. To achieve robust representation learning, these methods require extremely large batch sizes and escalate computational demands to hundreds or even thousands of GPUs. Prior approaches to mitigate this issue often compromise downstream performance, prolong training duration, or face scalability challenges with very large datasets. To overcome these limitations, we propose AmorLIP, an efficient CLIP pretraining framework that amortizes expensive computations involved in contrastive learning through lightweight neural networks, which substantially improves training efficiency and performance. Leveraging insights from a spectral factorization of energy-based models, we introduce novel amortization objectives along with practical techniques to improve training stability. Extensive experiments across 38 downstream tasks demonstrate the superior zero-shot classification and retrieval capabilities of AmorLIP, consistently outperforming standard CLIP baselines with substantial relative improvements of up to 12.24%.
Matryoshka: Learning to Drive Black-Box LLMs with LLMs
Oct 28, 2024Despite the impressive generative abilities of black-box large language models (LLMs), their inherent opacity hinders further advancements in capabilities such as reasoning, planning, and personalization. Existing works aim to enhance LLM capabilities via domain-specific adaptation or in-context learning, which require additional training on accessible model parameters, an infeasible option for black-box LLMs. To address this challenge, we introduce Matryoshika, a lightweight white-box LLM controller that guides a large-scale black-box LLM generator by decomposing complex tasks into a series of intermediate outputs. Specifically, we consider the black-box LLM as an environment, with Matryoshika serving as a policy to provide intermediate guidance through prompts for driving the black-box LLM. Matryoshika is trained to pivot the outputs of the black-box LLM aligning with preferences during iterative interaction, which enables controllable multi-turn generation and self-improvement in optimizing intermediate guidance. Empirical evaluations on three diverse tasks demonstrate that Matryoshika effectively enhances the capabilities of black-box LLMs in complex, long-horizon tasks, including reasoning, planning, and personalization. By leveraging this pioneering controller-generator framework to mitigate dependence on model parameters, Matryoshika provides a transparent and practical solution for improving black-box LLMs through controllable multi-turn generation using white-box LLMs.
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.
Spectral Representation for Causal Estimation with Hidden Confounders
Jul 15, 2024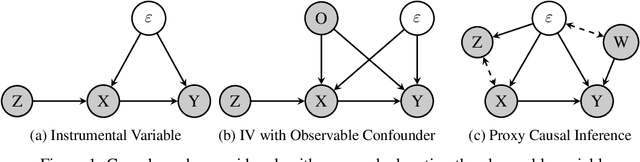


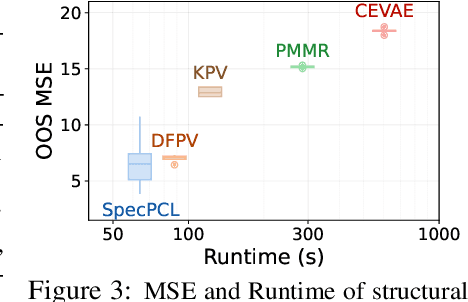
We address the problem of causal effect estimation where hidden confounders are present, with a focus on two settings: instrumental variable regression with additional observed confounders, and proxy causal learning. Our approach uses a singular value decomposition of a conditional expectation operator, followed by a saddle-point optimization problem, which, in the context of IV regression, can be thought of as a neural net generalization of the seminal approach due to Darolles et al. [2011]. Saddle-point formulations have gathered considerable attention recently, as they can avoid double sampling bias and are amenable to modern function approximation methods. We provide experimental validation in various settings, and show that our approach outperforms existing methods on common benchmarks.
HYDRA: Model Factorization Framework for Black-Box LLM Personalization
Jun 05, 2024

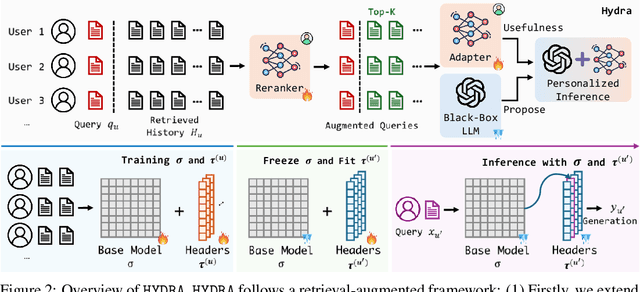

Personalization has emerged as a critical research area in modern intelligent systems, focusing on mining users' behavioral history and adapting to their preferences for delivering tailored experiences. Despite the remarkable few-shot capabilities exhibited by black-box large language models (LLMs), the inherent opacity of their model parameters presents significant challenges in aligning the generated output with individual expectations. Existing solutions have primarily focused on prompt design to incorporate user-specific profiles and behaviors; however, such approaches often struggle to generalize effectively due to their inability to capture shared knowledge among all users. To address these challenges, we propose HYDRA, a model factorization framework that captures both user-specific behavior patterns from historical data and shared general knowledge among all users to deliver personalized generation. In order to capture user-specific behavior patterns, we first train a reranker to prioritize the most useful information from top-retrieved relevant historical records. By combining the prioritized history with the corresponding query, we train an adapter to align the output with individual user-specific preferences, eliminating the reliance on access to inherent model parameters of black-box LLMs. Both the reranker and the adapter can be decomposed into a base model with multiple user-specific heads, resembling a hydra. The base model maintains shared knowledge across users, while the multiple personal heads capture user-specific preferences. Experimental results demonstrate that HYDRA outperforms existing state-of-the-art prompt-based methods by an average relative improvement of 9.01% across five diverse personalization tasks in the LaMP benchmark. Our implementation is available at https://github.com/night-chen/HYDRA.
BBox-Adapter: Lightweight Adapting for Black-Box Large Language Models
Feb 13, 2024Adapting state-of-the-art Large Language Models (LLMs) like GPT-4 and Gemini for specific tasks is challenging. Due to the opacity in their parameters, embeddings, and even output probabilities, existing fine-tuning adaptation methods are inapplicable. Consequently, adapting these black-box LLMs is only possible through their API services, raising concerns about transparency, privacy, and cost. To address these challenges, we introduce BBox-Adapter, a novel lightweight adapter for black-box LLMs. BBox-Adapter distinguishes target and source domain data by treating target data as positive and source data as negative. It employs a ranking-based Noise Contrastive Estimation (NCE) loss to promote the likelihood of target domain data while penalizing that of the source domain. Furthermore, it features an online adaptation mechanism, which incorporates real-time positive data sampling from ground-truth, human, or AI feedback, coupled with negative data from previous adaptations. Extensive experiments demonstrate BBox-Adapter's effectiveness and cost efficiency. It improves model performance by up to 6.77% across diverse tasks and domains, while reducing training and inference costs by 31.30x and 1.84x, respectively.
Autoregressive Diffusion Model for Graph Generation
Jul 17, 2023Diffusion-based graph generative models have recently obtained promising results for graph generation. However, existing diffusion-based graph generative models are mostly one-shot generative models that apply Gaussian diffusion in the dequantized adjacency matrix space. Such a strategy can suffer from difficulty in model training, slow sampling speed, and incapability of incorporating constraints. We propose an \emph{autoregressive diffusion} model for graph generation. Unlike existing methods, we define a node-absorbing diffusion process that operates directly in the discrete graph space. For forward diffusion, we design a \emph{diffusion ordering network}, which learns a data-dependent node absorbing ordering from graph topology. For reverse generation, we design a \emph{denoising network} that uses the reverse node ordering to efficiently reconstruct the graph by predicting the node type of the new node and its edges with previously denoised nodes at a time. Based on the permutation invariance of graph, we show that the two networks can be jointly trained by optimizing a simple lower bound of data likelihood. Our experiments on six diverse generic graph datasets and two molecule datasets show that our model achieves better or comparable generation performance with previous state-of-the-art, and meanwhile enjoys fast generation speed.
ToolQA: A Dataset for LLM Question Answering with External Tools
Jun 23, 2023Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks, but they still suffer from challenges such as hallucination and weak numerical reasoning. To overcome these challenges, external tools can be used to enhance LLMs' question-answering abilities. However, current evaluation methods do not distinguish between questions that can be answered using LLMs' internal knowledge and those that require external information through tool use. To address this issue, we introduce a new dataset called ToolQA, which is designed to faithfully evaluate LLMs' ability to use external tools for question answering. Our development of ToolQA involved a scalable, automated process for dataset curation, along with 13 specialized tools designed for interaction with external knowledge in order to answer questions. Importantly, we strive to minimize the overlap between our benchmark data and LLMs' pre-training data, enabling a more precise evaluation of LLMs' tool-use reasoning abilities. We conducted an in-depth diagnosis of existing tool-use LLMs to highlight their strengths, weaknesses, and potential improvements. Our findings set a new benchmark for evaluating LLMs and suggest new directions for future advancements. Our data and code are freely available to the broader scientific community on GitHub.