 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Agent Societies Develop Intellectual Elites? The Hidden Power Laws of Collective Cognition in LLM Multi-Agent Systems
Apr 03, 2026Large Language Model (LLM) multi-agent systems are increasingly deployed as interacting agent societies, yet scaling these systems often yields diminishing or unstable returns, the causes of which remain poorly understood. We present the first large-scale empirical study of coordination dynamics in LLM-based multi-agent systems, introducing an atomic event-level formulation that reconstructs reasoning as cascades of coordination. Analyzing over 1.5 Million interactions across tasks, topologies, and scales, we uncover three coupled laws: coordination follows heavy-tailed cascades, concentrates via preferential attachment into intellectual elites, and produces increasingly frequent extreme events as system size grows. We show that these effects are coupled through a single structural mechanism: an integration bottleneck, in which coordination expansion scales with system size while consolidation does not, producing large but weakly integrated reasoning processes. To test this mechanism, we introduce Deficit-Triggered Integration (DTI), which selectively increases integration under imbalance. DTI improves performance precisely where coordination fails, without suppressing large-scale reasoning. Together, our results establish quantitative laws of collective cognition and identify coordination structure as a fundamental, previously unmeasured axis for understanding and improving scalable multi-agent intelligence.
How (Not) to Hybridize Neural and Mechanistic Models for Epidemiological Forecasting
Feb 06, 2026Epidemiological forecasting from surveillance data is a hard problem and hybridizing mechanistic compartmental models with neural models is a natural direction. The mechanistic structure helps keep trajectories epidemiologically plausible, while neural components can capture non-stationary, data-adaptive effects. In practice, however, many seemingly straightforward couplings fail under partial observability and continually shifting transmission dynamics driven by behavior, waning immunity, seasonality, and interventions. We catalog these failure modes and show that robust performance requires making non-stationarity explicit: we extract multi-scale structure from the observed infection series and use it as an interpretable control signal for a controlled neural ODE coupled to an epidemiological model. Concretely, we decompose infections into trend, seasonal, and residual components and use these signals to drive continuous-time latent dynamics while jointly forecasting and inferring time-varying transmission, recovery, and immunity-loss rates. Across seasonal and non-seasonal settings, including early outbreaks and multi-wave regimes, our approach reduces long-horizon RMSE by 15-35%, improves peak timing error by 1-3 weeks, and lowers peak magnitude bias by up to 30% relative to strong time-series, neural ODE, and hybrid baselines, without relying on auxiliary covariates.
PhysicsAgentABM: Physics-Guided Generative Agent-Based Modeling
Feb 05, 2026Large language model (LLM)-based multi-agent systems enable expressive agent reasoning but are expensive to scale and poorly calibrated for timestep-aligned state-transition simulation, while classical agent-based models (ABMs) offer interpretability but struggle to integrate rich individual-level signals and non-stationary behaviors. We propose PhysicsAgentABM, which shifts inference to behaviorally coherent agent clusters: state-specialized symbolic agents encode mechanistic transition priors, a multimodal neural transition model captures temporal and interaction dynamics, and uncertainty-aware epistemic fusion yields calibrated cluster-level transition distributions. Individual agents then stochastically realize transitions under local constraints, decoupling population inference from entity-level variability. We further introduce ANCHOR, an LLM agent-driven clustering strategy based on cross-contextual behavioral responses and a novel contrastive loss, reducing LLM calls by up to 6-8 times. Experiments across public health, finance, and social sciences show consistent gains in event-time accuracy and calibration over mechanistic, neural, and LLM baselines. By re-architecting generative ABM around population-level inference with uncertainty-aware neuro-symbolic fusion, PhysicsAgentABM establishes a new paradigm for scalable and calibrated simulation with LLMs.
Cross-Modal Alignment and Fusion for RGB-D Transmission-Line Defect Detection
Feb 03, 2026Transmission line defect detection remains challenging for automated UAV inspection due to the dominance of small-scale defects, complex backgrounds, and illumination variations. Existing RGB-based detectors, despite recent progress, struggle to distinguish geometrically subtle defects from visually similar background structures under limited chromatic contrast. This paper proposes CMAFNet, a Cross-Modal Alignment and Fusion Network that integrates RGB appearance and depth geometry through a principled purify-then-fuse paradigm. CMAFNet consists of a Semantic Recomposition Module that performs dictionary-based feature purification via a learned codebook to suppress modality-specific noise while preserving defect-discriminative information, and a Contextual Semantic Integration Framework that captures global spatial dependencies using partial-channel attention to enhance structural semantic reasoning. Position-wise normalization within the purification stage enforces explicit reconstruction-driven cross-modal alignment, ensuring statistical compatibility between heterogeneous features prior to fusion. Extensive experiments on the TLRGBD benchmark, where 94.5% of instances are small objects, demonstrate that CMAFNet achieves 32.2% mAP@50 and 12.5% APs, outperforming the strongest baseline by 9.8 and 4.0 percentage points, respectively. A lightweight variant reaches 24.8% mAP50 at 228 FPS with only 4.9M parameters, surpassing all YOLO-based detectors while matching transformer-based methods at substantially lower computational cost.
Time-MMD: A New Multi-Domain Multimodal Dataset for Time Series Analysis
Jun 12, 2024



Time series data are ubiquitous across a wide range of real-world domains. While real-world time series analysis (TSA) requires human experts to integrate numerical series data with multimodal domain-specific knowledge, most existing TSA models rely solely on numerical data, overlooking the significance of information beyond numerical series. This oversight is due to the untapped potential of textual series data and the absence of a comprehensive, high-quality multimodal dataset. To overcome this obstacle, we introduce Time-MMD, the first multi-domain, multimodal time series dataset covering 9 primary data domains. Time-MMD ensures fine-grained modality alignment, eliminates data contamination, and provides high usability. Additionally, we develop MM-TSFlib, the first multimodal time-series forecasting (TSF) library, seamlessly pipelining multimodal TSF evaluations based on Time-MMD for in-depth analyses. Extensive experiments conducted on Time-MMD through MM-TSFlib demonstrate significant performance enhancements by extending unimodal TSF to multimodality, evidenced by over 15% mean squared error reduction in general, and up to 40% in domains with rich textual data. More importantly, our datasets and library revolutionize broader applications, impacts, research topics to advance TSA. The dataset and library are available at https://github.com/AdityaLab/Time-MMD and https://github.com/AdityaLab/MM-TSFlib.
SAGE-ICP: Semantic Information-Assisted ICP
Oct 11, 2023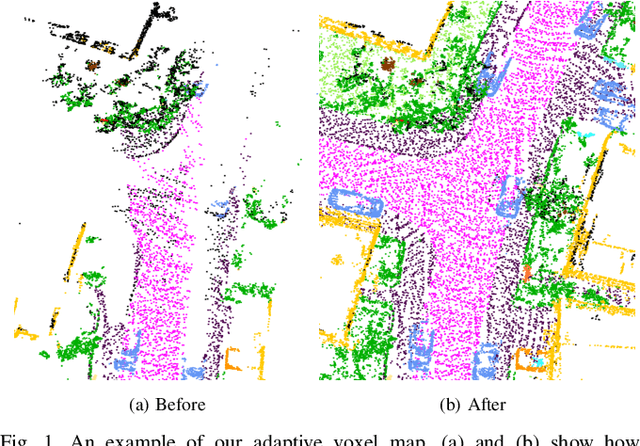
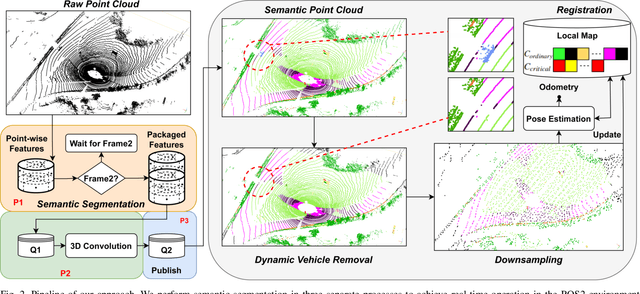
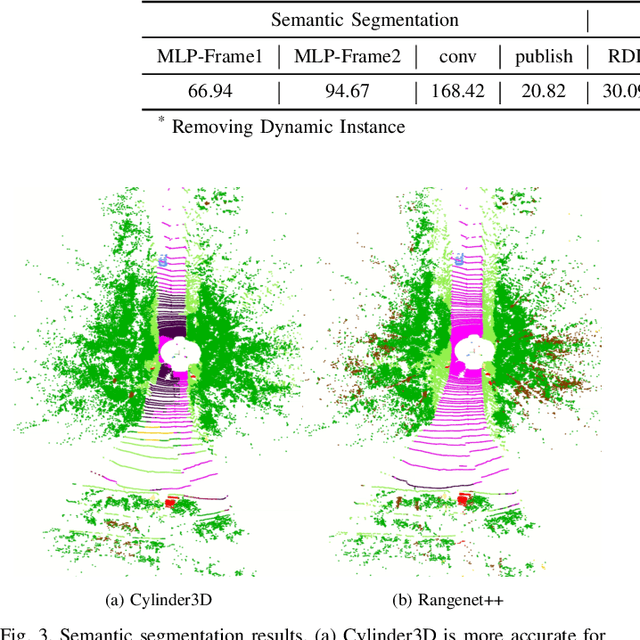
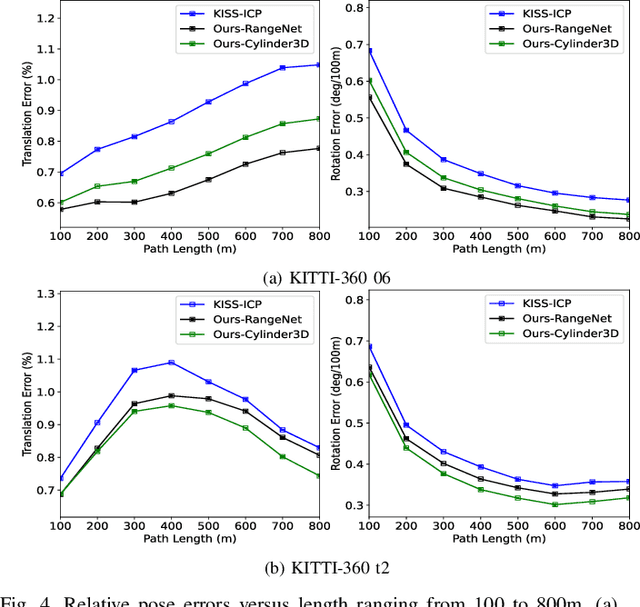
Robust and accurate pose estimation in unknown environments is an essential part of robotic applications. We focus on LiDAR-based point-to-point ICP combined with effective semantic information. This paper proposes a novel semantic information-assisted ICP method named SAGE-ICP, which leverages semantics in odometry. The semantic information for the whole scan is timely and efficiently extracted by a 3D convolution network, and these point-wise labels are deeply involved in every part of the registration, including semantic voxel downsampling, data association, adaptive local map, and dynamic vehicle removal. Unlike previous semantic-aided approaches, the proposed method can improve localization accuracy in large-scale scenes even if the semantic information has certain errors. Experimental evaluations on KITTI and KITTI-360 show that our method outperforms the baseline methods, and improves accuracy while maintaining real-time performance, i.e., runs faster than the sensor frame rate.
DF2: Distribution-Free Decision-Focused Learning
Aug 11, 2023Decision-focused learning (DFL) has recently emerged as a powerful approach for predict-then-optimize problems by customizing a predictive model to a downstream optimization task. However, existing end-to-end DFL methods are hindered by three significant bottlenecks: model mismatch error, sample average approximation error, and gradient approximation error. Model mismatch error stems from the misalignment between the model's parameterized predictive distribution and the true probability distribution. Sample average approximation error arises when using finite samples to approximate the expected optimization objective. Gradient approximation error occurs as DFL relies on the KKT condition for exact gradient computation, while most methods approximate the gradient for backpropagation in non-convex objectives. In this paper, we present DF2 -- the first \textit{distribution-free} decision-focused learning method explicitly designed to address these three bottlenecks. Rather than depending on a task-specific forecaster that requires precise model assumptions, our method directly learns the expected optimization function during training. To efficiently learn the function in a data-driven manner, we devise an attention-based model architecture inspired by the distribution-based parameterization of the expected objective. Our method is, to the best of our knowledge, the first to address all three bottlenecks within a single model. We evaluate DF2 on a synthetic problem, a wind power bidding problem, and a non-convex vaccine distribution problem, demonstrating the effectiveness of DF2.
Autoregressive Diffusion Model for Graph Generation
Jul 17, 2023Diffusion-based graph generative models have recently obtained promising results for graph generation. However, existing diffusion-based graph generative models are mostly one-shot generative models that apply Gaussian diffusion in the dequantized adjacency matrix space. Such a strategy can suffer from difficulty in model training, slow sampling speed, and incapability of incorporating constraints. We propose an \emph{autoregressive diffusion} model for graph generation. Unlike existing methods, we define a node-absorbing diffusion process that operates directly in the discrete graph space. For forward diffusion, we design a \emph{diffusion ordering network}, which learns a data-dependent node absorbing ordering from graph topology. For reverse generation, we design a \emph{denoising network} that uses the reverse node ordering to efficiently reconstruct the graph by predicting the node type of the new node and its edges with previously denoised nodes at a time. Based on the permutation invariance of graph, we show that the two networks can be jointly trained by optimizing a simple lower bound of data likelihood. Our experiments on six diverse generic graph datasets and two molecule datasets show that our model achieves better or comparable generation performance with previous state-of-the-art, and meanwhile enjoys fast generation speed.
End-to-End Stochastic Optimization with Energy-Based Model
Nov 25, 2022Decision-focused learning (DFL) was recently proposed for stochastic optimization problems that involve unknown parameters. By integrating predictive modeling with an implicitly differentiable optimization layer, DFL has shown superior performance to the standard two-stage predict-then-optimize pipeline. However, most existing DFL methods are only applicable to convex problems or a subset of nonconvex problems that can be easily relaxed to convex ones. Further, they can be inefficient in training due to the requirement of solving and differentiating through the optimization problem in every training iteration. We propose SO-EBM, a general and efficient DFL method for stochastic optimization using energy-based models. Instead of relying on KKT conditions to induce an implicit optimization layer, SO-EBM explicitly parameterizes the original optimization problem using a differentiable optimization layer based on energy functions. To better approximate the optimization landscape, we propose a coupled training objective that uses a maximum likelihood loss to capture the optimum location and a distribution-based regularizer to capture the overall energy landscape. Finally, we propose an efficient training procedure for SO-EBM with a self-normalized importance sampler based on a Gaussian mixture proposal. We evaluate SO-EBM in three applications: power scheduling, COVID-19 resource allocation, and non-convex adversarial security game, demonstrating the effectiveness and efficiency of SO-EBM.
EINNs: Epidemiologically-Informed Neural Networks
Feb 21, 2022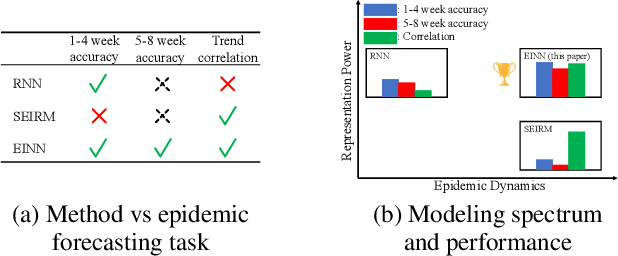
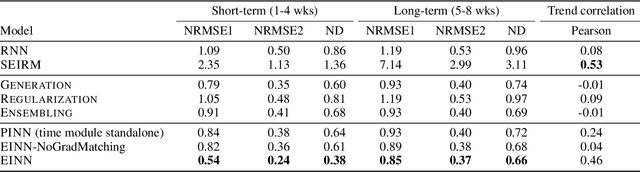
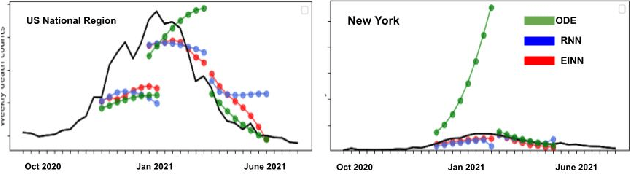
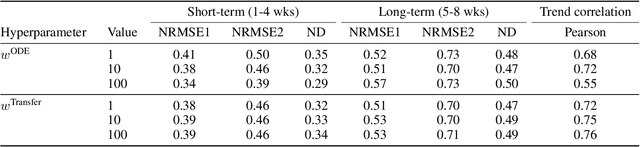
We introduce a new class of physics-informed neural networks-EINN-crafted for epidemic forecasting. We investigate how to leverage both the theoretical flexibility provided by mechanistic models as well as the data-driven expressability afforded by AI models, to ingest heterogeneous information. Although neural forecasting models has been successful in multiple tasks, long-term predictions and anticipating trend changes remain open challenges. Epidemiological ODE models contain mechanisms that can guide us in these two tasks; however, they have limited capability of ingesting data sources and modeling composite signals. Thus we propose to supervise neural networks with epidemic mechanistic models while simultaneously learning their hidden dynamics. Our method EINN allows neural models have the flexibility to learn the disease spread dynamics and use auxiliary features in a general framework. In contrast with previous work, we not assume the observability of complete dynamics and do not need to numerically solve the ODE equations during training. Our thorough experiments showcase the clear benefits of our approach with other non-trivial alternatives.