 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSTA: Cognitive-State-Conditioned TTS Data Augmentation Using ASR Transcripts for Alzheimer's Disease Detection
Jun 04, 2026Speech-based Alzheimer's Disease (AD) detection is constrained by scarce pathological speech data. To address this, we propose CoSTA, a Text-to-Speech (TTS)-based data augmentation framework. Specifically, we first develop two Cognitive-State-Conditioned (CS-Cond) TTS models by adapting CosyVoice2 and F5-TTS to synthesize speech with distinct AD and Healthy Control characteristics. Furthermore, by constructing a transcript pool comprising Manual Transcripts (MT) and 36 Automatic Speech Recognition (ASR) transcripts, we investigate the impact of text sources on TTS-based augmentation. We also perform augmentation-factor analysis and test-time augmentation. Experiments on the ADReSS dataset show that CS-Cond TTS significantly improves synthetic speech utility, and ASR-driven augmentation frequently outperforms MT-driven augmentation. Finally, CoSTA yields a 4.16% gain over the baseline, achieving an audio-only accuracy of 85.83% on the ADReSS test set and outperforming prior methods.
QUBRIC: Co-Designing Queries and Rubrics for RL Beyond Verifiable Rewards
Jun 02, 2026Rubric-based RL is a promising route for extending reinforcement learning beyond verifiable rewards, yet existing methods optimize rubrics while treating the query distribution as fixed. We identify a structural bottleneck: rubric quality is constrained by query structure. Open-ended queries yield vague rubrics; naively narrowing them introduces fabricated references that no model can verify, so all responses fail and training receives no reward signal. We present QUBRIC, a framework that co-designs queries and rubrics. Teacher-derived key points ground the rewriting of open-ended queries into scenario-based, evaluable questions. Contrastive rubric generation then turns teacher-policy gaps into query-level criteria, and learnability filtering retains only informative query-rubric pairs for GRPO training. QUBRIC achieves a +5.5 point gain on ArenaHard over the SFT baseline. Trained only on instruction-following data, it further transfers to three held-out benchmarks spanning legal, moral, and narrative reasoning (+6.3 points on average), with improvements concentrated in reasoning-related dimensions. These results provide evidence that co-designing queries and rubrics can make rubric-based RL a practical complement to RLVR beyond strictly verifiable tasks.
Clinical Priors Guided Lung Disease Detection in 3D CT Scans
Mar 17, 2026Accurate classification of lung diseases from chest CT scans plays an important role in computer-aided diagnosis systems. However, medical imaging datasets often suffer from severe class imbalance, which may significantly degrade the performance of deep learning models, especially for minority disease categories. To address this issue, we propose a gender-aware two-stage lung disease classification framework. The proposed approach explicitly incorporates gender information into the disease recognition pipeline. In the first stage, a gender classifier is trained to predict the patient's gender from CT scans. In the second stage, the input CT image is routed to a corresponding gender-specific disease classifier to perform final disease prediction. This design enables the model to better capture gender-related imaging characteristics and alleviate the influence of imbalanced data distribution. Experimental results demonstrate that the proposed method improves the recognition performance for minority disease categories, particularly squamous cell carcinoma, while maintaining competitive performance on other classes.
Vision-Language Model Based Multi-Expert Fusion for CT Image Classification
Mar 16, 2026Robust detection of COVID-19 from chest CT remains challenging in multi-institutional settings due to substantial source shift, source imbalance, and hidden test-source identities. In this work, we propose a three-stage source-aware multi-expert framework for multi-source COVID-19 CT classification. First, we build a lung-aware 3D expert by combining original CT volumes and lung-extracted CT volumes for volumetric classification. Second, we develop two MedSigLIP-based experts: a slice-wise representation and probability learning module, and a Transformer-based inter-slice context modeling module for capturing cross-slice dependency. Third, we train a source classifier to predict the latent source identity of each test scan. By leveraging the predicted source information, we perform model fusion and voting based on different experts. On the validation set covering all four sources, the Stage 1 model achieves the best macro-F1 of 0.9711, ACC of 0.9712, and AUC of 0.9791. Stage~2a and Stage~2b achieve the best AUC scores of 0.9864 and 0.9854, respectively. Stage~3 source classifier reaches 0.9107 ACC and 0.9114 F1. These results demonstrate that source-aware expert modeling and hierarchical voting provide an effective solution for robust COVID-19 CT classification under heterogeneous multi-source conditions.
Cross-Linguistic Persona-Driven Data Synthesis for Robust Multimodal Cognitive Decline Detection
Feb 08, 2026Speech-based digital biomarkers represent a scalable, non-invasive frontier for the early identification of Mild Cognitive Impairment (MCI). However, the development of robust diagnostic models remains impeded by acute clinical data scarcity and a lack of interpretable reasoning. Current solutions frequently struggle with cross-lingual generalization and fail to provide the transparent rationales essential for clinical trust. To address these barriers, we introduce SynCog, a novel framework integrating controllable zero-shot multimodal data synthesis with Chain-of-Thought (CoT) deduction fine-tuning. Specifically, SynCog simulates diverse virtual subjects with varying cognitive profiles to effectively alleviate clinical data scarcity. This generative paradigm enables the rapid, zero-shot expansion of clinical corpora across diverse languages, effectively bypassing data bottlenecks in low-resource settings and bolstering the diagnostic performance of Multimodal Large Language Models (MLLMs). Leveraging this synthesized dataset, we fine-tune a foundational multimodal backbone using a CoT deduction strategy, empowering the model to explicitly articulate diagnostic thought processes rather than relying on black-box predictions. Extensive experiments on the ADReSS and ADReSSo benchmarks demonstrate that augmenting limited clinical data with synthetic phenotypes yields competitive diagnostic performance, achieving Macro-F1 scores of 80.67% and 78.46%, respectively, outperforming current baseline models. Furthermore, evaluation on an independent real-world Mandarin cohort (CIR-E) demonstrates robust cross-linguistic generalization, attaining a Macro-F1 of 48.71%. These findings constitute a critical step toward providing clinically trustworthy and linguistically inclusive cognitive assessment tools for global healthcare.
MAGA-Bench: Machine-Augment-Generated Text via Alignment Detection Benchmark
Jan 08, 2026Large Language Models (LLMs) alignment is constantly evolving. Machine-Generated Text (MGT) is becoming increasingly difficult to distinguish from Human-Written Text (HWT). This has exacerbated abuse issues such as fake news and online fraud. Fine-tuned detectors' generalization ability is highly dependent on dataset quality, and simply expanding the sources of MGT is insufficient. Further augment of generation process is required. According to HC-Var's theory, enhancing the alignment of generated text can not only facilitate attacks on existing detectors to test their robustness, but also help improve the generalization ability of detectors fine-tuned on it. Therefore, we propose \textbf{M}achine-\textbf{A}ugment-\textbf{G}enerated Text via \textbf{A}lignment (MAGA). MAGA's pipeline achieves comprehensive alignment from prompt construction to reasoning process, among which \textbf{R}einforced \textbf{L}earning from \textbf{D}etectors \textbf{F}eedback (RLDF), systematically proposed by us, serves as a key component. In our experiments, the RoBERTa detector fine-tuned on MAGA training set achieved an average improvement of 4.60\% in generalization detection AUC. MAGA Dataset caused an average decrease of 8.13\% in the AUC of the selected detectors, expecting to provide indicative significance for future research on the generalization detection ability of detectors.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
EGGCodec: A Robust Neural Encodec Framework for EGG Reconstruction and F0 Extraction
Aug 12, 2025This letter introduces EGGCodec, a robust neural Encodec framework engineered for electroglottography (EGG) signal reconstruction and F0 extraction. We propose a multi-scale frequency-domain loss function to capture the nuanced relationship between original and reconstructed EGG signals, complemented by a time-domain correlation loss to improve generalization and accuracy. Unlike conventional Encodec models that extract F0 directly from features, EGGCodec leverages reconstructed EGG signals, which more closely correspond to F0. By removing the conventional GAN discriminator, we streamline EGGCodec's training process without compromising efficiency, incurring only negligible performance degradation. Trained on a widely used EGG-inclusive dataset, extensive evaluations demonstrate that EGGCodec outperforms state-of-the-art F0 extraction schemes, reducing mean absolute error (MAE) from 14.14 Hz to 13.69 Hz, and improving voicing decision error (VDE) by 38.2\%. Moreover, extensive ablation experiments validate the contribution of each component of EGGCodec.
Exploring Gender Bias in Alzheimer's Disease Detection: Insights from Mandarin and Greek Speech Perception
Jul 16, 2025
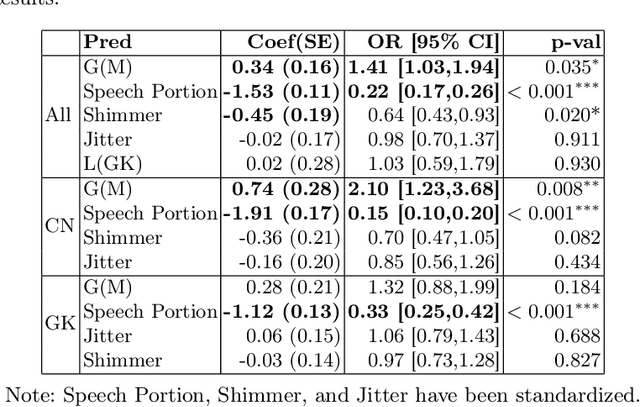
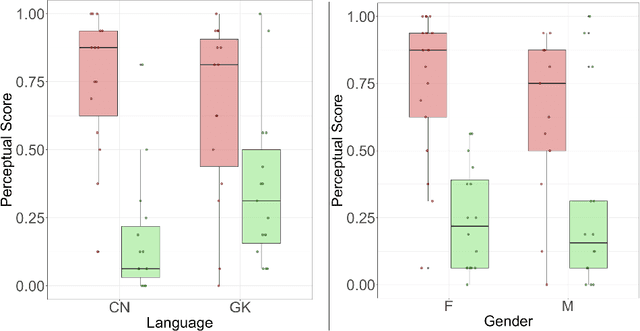
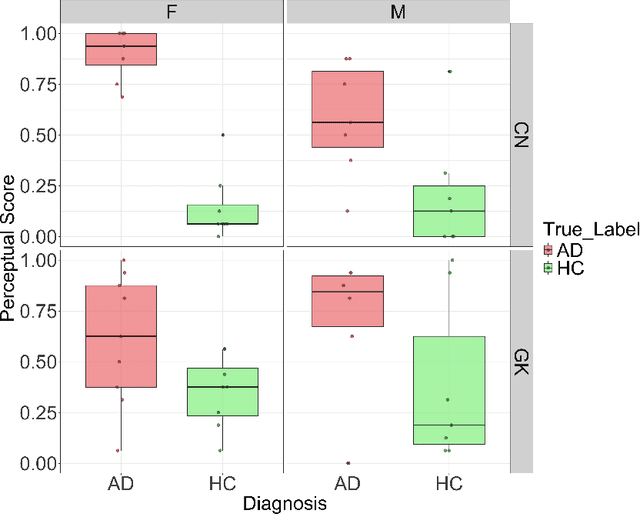
Gender bias has been widely observed in speech perception tasks, influenced by the fundamental voicing differences between genders. This study reveals a gender bias in the perception of Alzheimer's Disease (AD) speech. In a perception experiment involving 16 Chinese listeners evaluating both Chinese and Greek speech, we identified that male speech was more frequently identified as AD, with this bias being particularly pronounced in Chinese speech. Acoustic analysis showed that shimmer values in male speech were significantly associated with AD perception, while speech portion exhibited a significant negative correlation with AD identification. Although language did not have a significant impact on AD perception, our findings underscore the critical role of gender bias in AD speech perception. This work highlights the necessity of addressing gender bias when developing AD detection models and calls for further research to validate model performance across different linguistic contexts.
Dual Semantic-Aware Network for Noise Suppressed Ultrasound Video Segmentation
Jul 10, 2025Ultrasound imaging is a prevalent diagnostic tool known for its simplicity and non-invasiveness. However, its inherent characteristics often introduce substantial noise, posing considerable challenges for automated lesion or organ segmentation in ultrasound video sequences. To address these limitations, we propose the Dual Semantic-Aware Network (DSANet), a novel framework designed to enhance noise robustness in ultrasound video segmentation by fostering mutual semantic awareness between local and global features. Specifically, we introduce an Adjacent-Frame Semantic-Aware (AFSA) module, which constructs a channel-wise similarity matrix to guide feature fusion across adjacent frames, effectively mitigating the impact of random noise without relying on pixel-level relationships. Additionally, we propose a Local-and-Global Semantic-Aware (LGSA) module that reorganizes and fuses temporal unconditional local features, which capture spatial details independently at each frame, with conditional global features that incorporate temporal context from adjacent frames. This integration facilitates multi-level semantic representation, significantly improving the model's resilience to noise interference. Extensive evaluations on four benchmark datasets demonstrate that DSANet substantially outperforms state-of-the-art methods in segmentation accuracy. Moreover, since our model avoids pixel-level feature dependencies, it achieves significantly higher inference FPS than video-based methods, and even surpasses some image-based models. Code can be found in \href{https://github.com/ZhouL2001/DSANet}{DSANet}