 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Foundation Models Are Not Clinical Enough for Hospital Operations
Nov 17, 2025Hospitals and healthcare systems rely on operational decisions that determine patient flow, cost, and quality of care. Despite strong performance on medical knowledge and conversational benchmarks, foundation models trained on general text may lack the specialized knowledge required for these operational decisions. We introduce Lang1, a family of models (100M-7B parameters) pretrained on a specialized corpus blending 80B clinical tokens from NYU Langone Health's EHRs and 627B tokens from the internet. To rigorously evaluate Lang1 in real-world settings, we developed the REalistic Medical Evaluation (ReMedE), a benchmark derived from 668,331 EHR notes that evaluates five critical tasks: 30-day readmission prediction, 30-day mortality prediction, length of stay, comorbidity coding, and predicting insurance claims denial. In zero-shot settings, both general-purpose and specialized models underperform on four of five tasks (36.6%-71.7% AUROC), with mortality prediction being an exception. After finetuning, Lang1-1B outperforms finetuned generalist models up to 70x larger and zero-shot models up to 671x larger, improving AUROC by 3.64%-6.75% and 1.66%-23.66% respectively. We also observed cross-task scaling with joint finetuning on multiple tasks leading to improvement on other tasks. Lang1-1B effectively transfers to out-of-distribution settings, including other clinical tasks and an external health system. Our findings suggest that predictive capabilities for hospital operations require explicit supervised finetuning, and that this finetuning process is made more efficient by in-domain pretraining on EHR. Our findings support the emerging view that specialized LLMs can compete with generalist models in specialized tasks, and show that effective healthcare systems AI requires the combination of in-domain pretraining, supervised finetuning, and real-world evaluation beyond proxy benchmarks.
Evaluating the performance and fragility of large language models on the self-assessment for neurological surgeons
May 29, 2025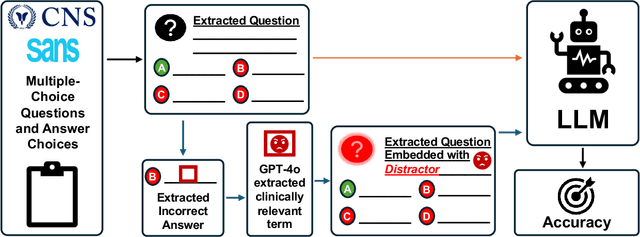
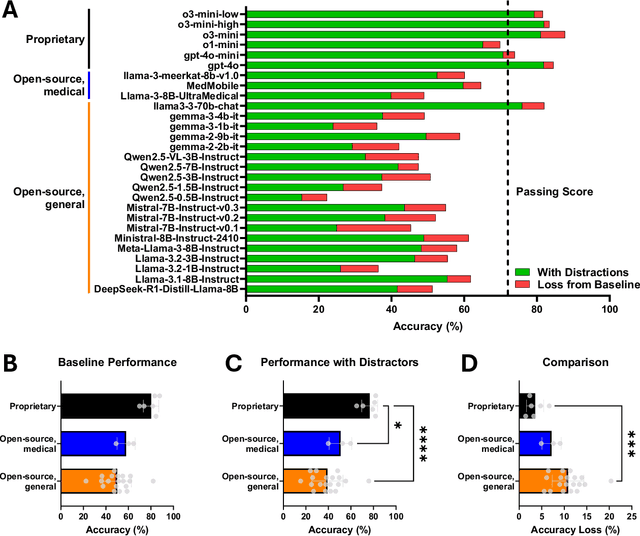
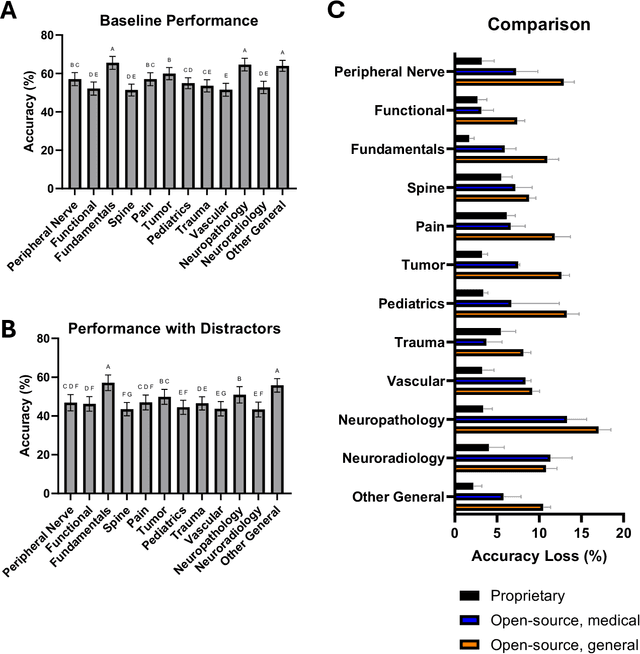
The Congress of Neurological Surgeons Self-Assessment for Neurological Surgeons (CNS-SANS) questions are widely used by neurosurgical residents to prepare for written board examinations. Recently, these questions have also served as benchmarks for evaluating large language models' (LLMs) neurosurgical knowledge. This study aims to assess the performance of state-of-the-art LLMs on neurosurgery board-like questions and to evaluate their robustness to the inclusion of distractor statements. A comprehensive evaluation was conducted using 28 large language models. These models were tested on 2,904 neurosurgery board examination questions derived from the CNS-SANS. Additionally, the study introduced a distraction framework to assess the fragility of these models. The framework incorporated simple, irrelevant distractor statements containing polysemous words with clinical meanings used in non-clinical contexts to determine the extent to which such distractions degrade model performance on standard medical benchmarks. 6 of the 28 tested LLMs achieved board-passing outcomes, with the top-performing models scoring over 15.7% above the passing threshold. When exposed to distractions, accuracy across various model architectures was significantly reduced-by as much as 20.4%-with one model failing that had previously passed. Both general-purpose and medical open-source models experienced greater performance declines compared to proprietary variants when subjected to the added distractors. While current LLMs demonstrate an impressive ability to answer neurosurgery board-like exam questions, their performance is markedly vulnerable to extraneous, distracting information. These findings underscore the critical need for developing novel mitigation strategies aimed at bolstering LLM resilience against in-text distractions, particularly for safe and effective clinical deployment.
Repurposing the scientific literature with vision-language models
Feb 26, 2025Research in AI for Science often focuses on using AI technologies to augment components of the scientific process, or in some cases, the entire scientific method; how about AI for scientific publications? Peer-reviewed journals are foundational repositories of specialized knowledge, written in discipline-specific language that differs from general Internet content used to train most large language models (LLMs) and vision-language models (VLMs). We hypothesized that by combining a family of scientific journals with generative AI models, we could invent novel tools for scientific communication, education, and clinical care. We converted 23,000 articles from Neurosurgery Publications into a multimodal database - NeuroPubs - of 134 million words and 78,000 image-caption pairs to develop six datasets for building AI models. We showed that the content of NeuroPubs uniquely represents neurosurgery-specific clinical contexts compared with broader datasets and PubMed. For publishing, we employed generalist VLMs to automatically generate graphical abstracts from articles. Editorial board members rated 70% of these as ready for publication without further edits. For education, we generated 89,587 test questions in the style of the ABNS written board exam, which trainee and faculty neurosurgeons found indistinguishable from genuine examples 54% of the time. We used these questions alongside a curriculum learning process to track knowledge acquisition while training our 34 billion-parameter VLM (CNS-Obsidian). In a blinded, randomized controlled trial, we demonstrated the non-inferiority of CNS-Obsidian to GPT-4o (p = 0.1154) as a diagnostic copilot for a neurosurgical service. Our findings lay a novel foundation for AI with Science and establish a framework to elevate scientific communication using state-of-the-art generative artificial intelligence while maintaining rigorous quality standards.
MedG-KRP: Medical Graph Knowledge Representation Probing
Dec 17, 2024Large language models (LLMs) have recently emerged as powerful tools, finding many medical applications. LLMs' ability to coalesce vast amounts of information from many sources to generate a response-a process similar to that of a human expert-has led many to see potential in deploying LLMs for clinical use. However, medicine is a setting where accurate reasoning is paramount. Many researchers are questioning the effectiveness of multiple choice question answering (MCQA) benchmarks, frequently used to test LLMs. Researchers and clinicians alike must have complete confidence in LLMs' abilities for them to be deployed in a medical setting. To address this need for understanding, we introduce a knowledge graph (KG)-based method to evaluate the biomedical reasoning abilities of LLMs. Essentially, we map how LLMs link medical concepts in order to better understand how they reason. We test GPT-4, Llama3-70b, and PalmyraMed-70b, a specialized medical model. We enlist a panel of medical students to review a total of 60 LLM-generated graphs and compare these graphs to BIOS, a large biomedical KG. We observe GPT-4 to perform best in our human review but worst in our ground truth comparison; vice-versa with PalmyraMed, the medical model. Our work provides a means of visualizing the medical reasoning pathways of LLMs so they can be implemented in clinical settings safely and effectively.