 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Gender Bias in Alzheimer's Disease Detection: Insights from Mandarin and Greek Speech Perception
Jul 16, 2025
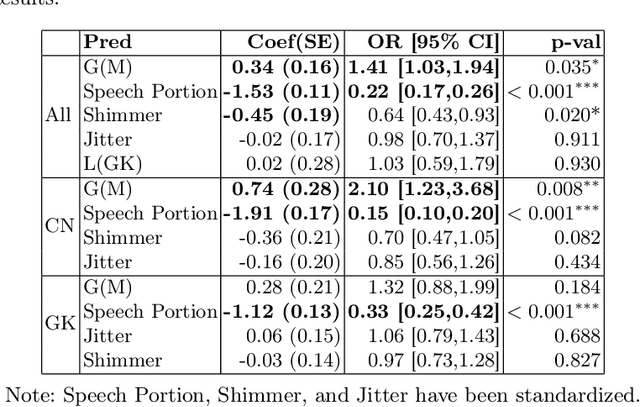
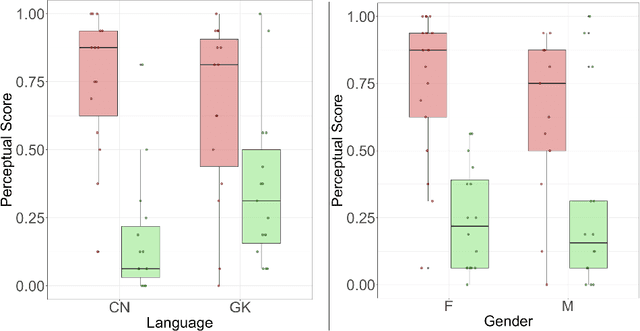
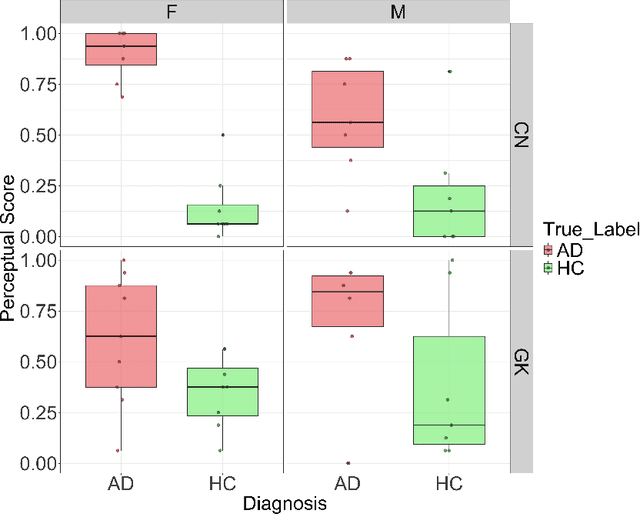
Gender bias has been widely observed in speech perception tasks, influenced by the fundamental voicing differences between genders. This study reveals a gender bias in the perception of Alzheimer's Disease (AD) speech. In a perception experiment involving 16 Chinese listeners evaluating both Chinese and Greek speech, we identified that male speech was more frequently identified as AD, with this bias being particularly pronounced in Chinese speech. Acoustic analysis showed that shimmer values in male speech were significantly associated with AD perception, while speech portion exhibited a significant negative correlation with AD identification. Although language did not have a significant impact on AD perception, our findings underscore the critical role of gender bias in AD speech perception. This work highlights the necessity of addressing gender bias when developing AD detection models and calls for further research to validate model performance across different linguistic contexts.
Beyond Manual Transcripts: The Potential of Automated Speech Recognition Errors in Improving Alzheimer's Disease Detection
May 26, 2025Recent breakthroughs in Automatic Speech Recognition (ASR) have enabled fully automated Alzheimer's Disease (AD) detection using ASR transcripts. Nonetheless, the impact of ASR errors on AD detection remains poorly understood. This paper fills the gap. We conduct a comprehensive study on AD detection using transcripts from various ASR models and their synthesized speech on the ADReSS dataset. Experimental results reveal that certain ASR transcripts (ASR-synthesized speech) outperform manual transcripts (manual-synthesized speech) in detection accuracy, suggesting that ASR errors may provide valuable cues for improving AD detection. Additionally, we propose a cross-attention-based interpretability model that not only identifies these cues but also achieves superior or comparable performance to the baseline. Furthermore, we utilize this model to unveil AD-related patterns within pre-trained embeddings. Our study offers novel insights into the potential of ASR models for AD detection.
Leveraging Cascaded Binary Classification and Multimodal Fusion for Dementia Detection through Spontaneous Speech
May 26, 2025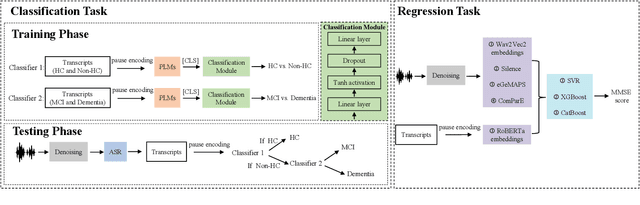
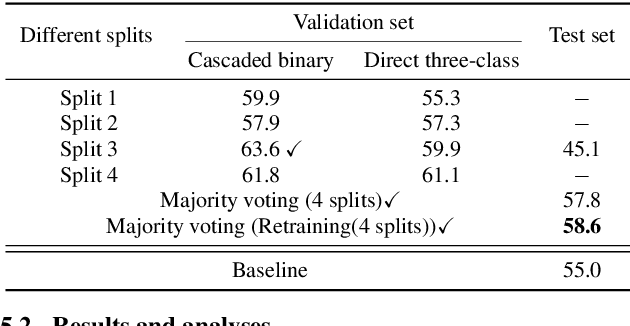
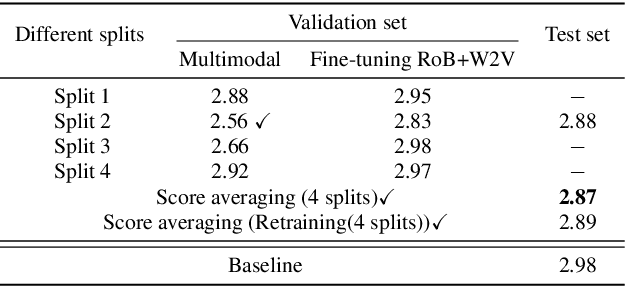
This paper presents our submission to the PROCESS Challenge 2025, focusing on spontaneous speech analysis for early dementia detection. For the three-class classification task (Healthy Control, Mild Cognitive Impairment, and Dementia), we propose a cascaded binary classification framework that fine-tunes pre-trained language models and incorporates pause encoding to better capture disfluencies. This design streamlines multi-class classification and addresses class imbalance by restructuring the decision process. For the Mini-Mental State Examination score regression task, we develop an enhanced multimodal fusion system that combines diverse acoustic and linguistic features. Separate regression models are trained on individual feature sets, with ensemble learning applied through score averaging. Experimental results on the test set outperform the baselines provided by the organizers in both tasks, demonstrating the robustness and effectiveness of our approach.
Decoding Speaker-Normalized Pitch from EEG for Mandarin Perception
May 26, 2025The same speech content produced by different speakers exhibits significant differences in pitch contour, yet listeners' semantic perception remains unaffected. This phenomenon may stem from the brain's perception of pitch contours being independent of individual speakers' pitch ranges. In this work, we recorded electroencephalogram (EEG) while participants listened to Mandarin monosyllables with varying tones, phonemes, and speakers. The CE-ViViT model is proposed to decode raw or speaker-normalized pitch contours directly from EEG. Experimental results demonstrate that the proposed model can decode pitch contours with modest errors, achieving performance comparable to state-of-the-art EEG regression methods. Moreover, speaker-normalized pitch contours were decoded more accurately, supporting the neural encoding of relative pitch.
Leveraging Prompt Learning and Pause Encoding for Alzheimer's Disease Detection
Dec 09, 2024Compared to other clinical screening techniques, speech-and-language-based automated Alzheimer's disease (AD) detection methods are characterized by their non-invasiveness, cost-effectiveness, and convenience. Previous studies have demonstrated the efficacy of fine-tuning pre-trained language models (PLMs) for AD detection. However, the objective of this traditional fine-tuning method, which involves inputting only transcripts, is inconsistent with the masked language modeling (MLM) task used during the pre-training phase of PLMs. In this paper, we investigate prompt-based fine-tuning of PLMs, converting the classification task into a MLM task by inserting prompt templates into the transcript inputs. We also explore the impact of incorporating pause information from forced alignment into manual transcripts. Additionally, we compare the performance of various automatic speech recognition (ASR) models and select the Whisper model to generate ASR-based transcripts for comparison with manual transcripts. Furthermore, majority voting and ensemble techniques are applied across different PLMs (BERT and RoBERTa) using different random seeds. Ultimately, we obtain maximum detection accuracy of 95.8% (with mean 87.9%, std 3.3%) using manual transcripts, achieving state-of-the-art performance for AD detection using only transcripts on the ADReSS test set.
Clever Hans Effect Found in Automatic Detection of Alzheimer's Disease through Speech
Jun 11, 2024

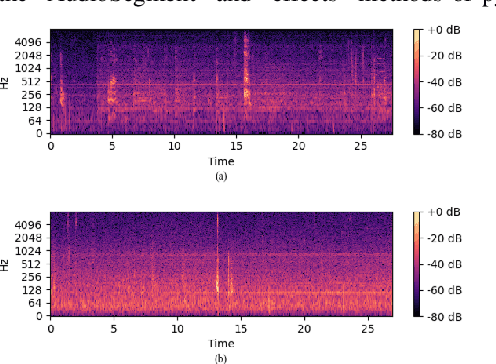
We uncover an underlying bias present in the audio recordings produced from the picture description task of the Pitt corpus, the largest publicly accessible database for Alzheimer's Disease (AD) detection research. Even by solely utilizing the silent segments of these audio recordings, we achieve nearly 100% accuracy in AD detection. However, employing the same methods to other datasets and preprocessed Pitt recordings results in typical levels (approximately 80%) of AD detection accuracy. These results demonstrate a Clever Hans effect in AD detection on the Pitt corpus. Our findings emphasize the crucial importance of maintaining vigilance regarding inherent biases in datasets utilized for training deep learning models, and highlight the necessity for a better understanding of the models' performance.