 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClever Hans Effect Found in Automatic Detection of Alzheimer's Disease through Speech
Paper and Code


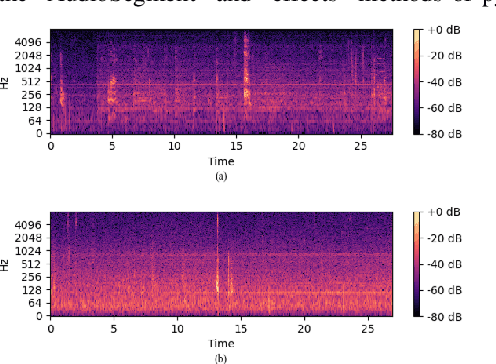
We uncover an underlying bias present in the audio recordings produced from the picture description task of the Pitt corpus, the largest publicly accessible database for Alzheimer's Disease (AD) detection research. Even by solely utilizing the silent segments of these audio recordings, we achieve nearly 100% accuracy in AD detection. However, employing the same methods to other datasets and preprocessed Pitt recordings results in typical levels (approximately 80%) of AD detection accuracy. These results demonstrate a Clever Hans effect in AD detection on the Pitt corpus. Our findings emphasize the crucial importance of maintaining vigilance regarding inherent biases in datasets utilized for training deep learning models, and highlight the necessity for a better understanding of the models' performance.