 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Clinically Validated Foundation Model for Comprehensive Lung Pathology Interpretation
May 25, 2026Pathological assessment guides lung cancer diagnosis, treatment selection, and prognostic evaluation, yet current CPath approaches rely on task-specific models for isolated objectives. Although pan-cancer foundation models offer versatility, they lack subspecialty-level depth and have not been evaluated across clinical workflows or prospectively validated in real-world settings. We introduce PulmoFoundation, a multi-center, prospectively validated, randomized controlled trial (RCT)-evaluated foundation model for comprehensive lung pathology assessment across pre-operative, intra-operative, and post-operative care. Built upon Virchow2 via subspecialty-specific pretraining using ~40,000 diagnostic H&E-stained whole-slide images (WSIs), PulmoFoundation was systematically evaluated on ~26,000 WSIs across 32 clinically relevant tasks. In addition to accurately predicting molecular markers and patient survival, our model achieves clinical-grade performance in core diagnostic tasks across biopsy, frozen section, and surgical resection slides. In a registered prospective study of 1,357 patients across 11 diagnostic tasks, our model achieved an average AUC of 92.3%. Using pre-specified triage thresholds, PulmoFoundation could reduce additional second-review burden for 68.8% of biopsies and 83.0% of frozen sections, and defer 44.5% of IHC stain orders, with PPVs of 1.0, 0.991, and 0.966. Beyond prospective validation, we conducted a crossover RCT with eight pathologists, in which AI assistance improved diagnostic accuracy across 4,928 case-reader pairs (91.7% w/ AI vs. 83.8% w/o AI). AI assistance also reduced median diagnostic time by 19.6%, increased diagnostic confidence by 8.7%, and improved inter-rater agreement from moderate (kappa = 0.56) to substantial (kappa = 0.76). Together, these evaluations support PulmoFoundation as a clinically validated decision-support system for lung pathology.
Clinical Priors Guided Lung Disease Detection in 3D CT Scans
Mar 17, 2026Accurate classification of lung diseases from chest CT scans plays an important role in computer-aided diagnosis systems. However, medical imaging datasets often suffer from severe class imbalance, which may significantly degrade the performance of deep learning models, especially for minority disease categories. To address this issue, we propose a gender-aware two-stage lung disease classification framework. The proposed approach explicitly incorporates gender information into the disease recognition pipeline. In the first stage, a gender classifier is trained to predict the patient's gender from CT scans. In the second stage, the input CT image is routed to a corresponding gender-specific disease classifier to perform final disease prediction. This design enables the model to better capture gender-related imaging characteristics and alleviate the influence of imbalanced data distribution. Experimental results demonstrate that the proposed method improves the recognition performance for minority disease categories, particularly squamous cell carcinoma, while maintaining competitive performance on other classes.
Vision-Language Model Based Multi-Expert Fusion for CT Image Classification
Mar 16, 2026Robust detection of COVID-19 from chest CT remains challenging in multi-institutional settings due to substantial source shift, source imbalance, and hidden test-source identities. In this work, we propose a three-stage source-aware multi-expert framework for multi-source COVID-19 CT classification. First, we build a lung-aware 3D expert by combining original CT volumes and lung-extracted CT volumes for volumetric classification. Second, we develop two MedSigLIP-based experts: a slice-wise representation and probability learning module, and a Transformer-based inter-slice context modeling module for capturing cross-slice dependency. Third, we train a source classifier to predict the latent source identity of each test scan. By leveraging the predicted source information, we perform model fusion and voting based on different experts. On the validation set covering all four sources, the Stage 1 model achieves the best macro-F1 of 0.9711, ACC of 0.9712, and AUC of 0.9791. Stage~2a and Stage~2b achieve the best AUC scores of 0.9864 and 0.9854, respectively. Stage~3 source classifier reaches 0.9107 ACC and 0.9114 F1. These results demonstrate that source-aware expert modeling and hierarchical voting provide an effective solution for robust COVID-19 CT classification under heterogeneous multi-source conditions.
Free Lunch in Medical Image Foundation Model Pre-training via Randomized Synthesis and Disentanglement
Feb 12, 2026Medical image foundation models (MIFMs) have demonstrated remarkable potential for a wide range of clinical tasks, yet their development is constrained by the scarcity, heterogeneity, and high cost of large-scale annotated datasets. Here, we propose RaSD (Randomized Synthesis and Disentanglement), a scalable framework for pre-training MIFMs entirely on synthetic data. By modeling anatomical structures and appearance variations with randomized Gaussian distributions, RaSD exposes models to sufficient multi-scale structural and appearance perturbations, forcing them to rely on invariant and task-relevant anatomical cues rather than dataset-specific textures, thereby enabling robust and transferable representation learning. We pre-trained RaSD on 1.2 million 3D volumes and 9.6 million 2D images, and extensively evaluated the resulting models across 6 imaging modalities, 48 datasets, and 56 downstream tasks. Across all evaluated downstream tasks, RaSD consistently outperforms training-from-scratch models, achieves the best performance on 17 tasks, and remains comparable to models pre-trained on large real datasets in most others. These results demonstrate that the capacity of synthetic data alone to drive robust representation learning. Our findings establish a paradigm shift in medical AI, demonstrating that synthetic data can serve as a "free lunch" for scalable, privacy-preserving, and clinically generalizable foundation models.
Benchmarking Real-World Medical Image Classification with Noisy Labels: Challenges, Practice, and Outlook
Dec 10, 2025Learning from noisy labels remains a major challenge in medical image analysis, where annotation demands expert knowledge and substantial inter-observer variability often leads to inconsistent or erroneous labels. Despite extensive research on learning with noisy labels (LNL), the robustness of existing methods in medical imaging has not been systematically assessed. To address this gap, we introduce LNMBench, a comprehensive benchmark for Label Noise in Medical imaging. LNMBench encompasses \textbf{10} representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns, establishing a unified and reproducible framework for robustness evaluation under realistic conditions. Comprehensive experiments reveal that the performance of existing LNL methods degrades substantially under high and real-world noise, highlighting the persistent challenges of class imbalance and domain variability in medical data. Motivated by these findings, we further propose a simple yet effective improvement to enhance model robustness under such conditions. The LNMBench codebase is publicly released to facilitate standardized evaluation, promote reproducible research, and provide practical insights for developing noise-resilient algorithms in both research and real-world medical applications.The codebase is publicly available on https://github.com/myyy777/LNMBench.
A Versatile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model
Jul 23, 2025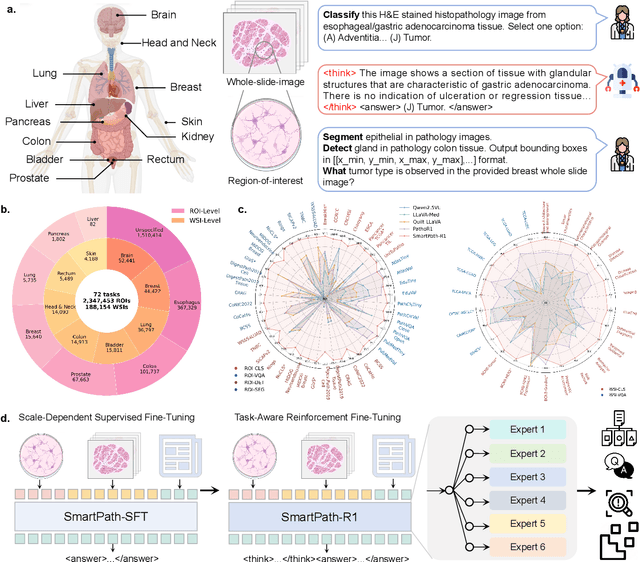
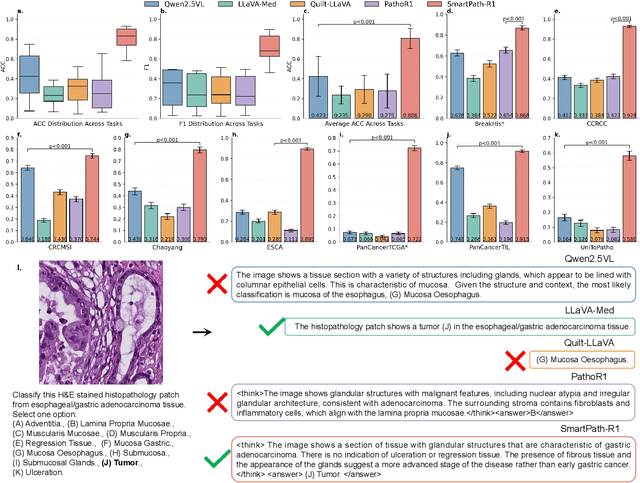
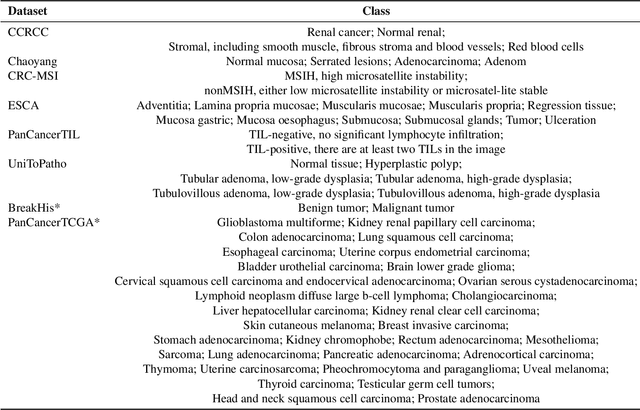
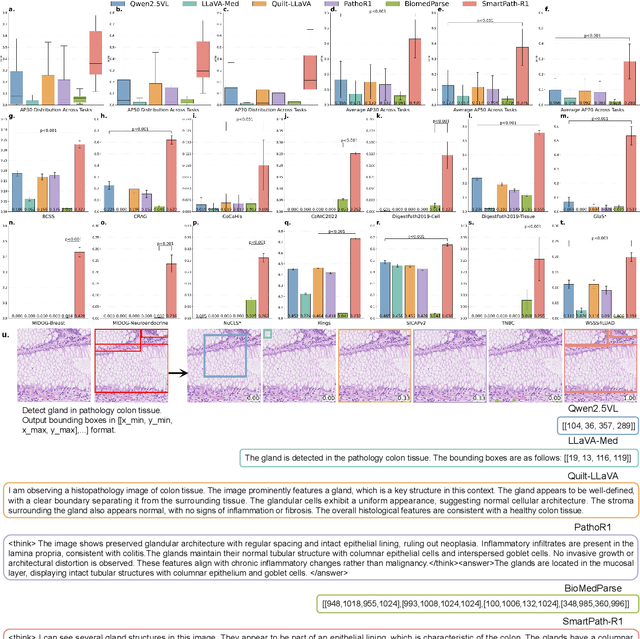
Multimodal large language models (MLLMs) have emerged as powerful tools for computational pathology, offering unprecedented opportunities to integrate pathological images with language context for comprehensive diagnostic analysis. These models hold particular promise for automating complex tasks that traditionally require expert interpretation of pathologists. However, current MLLM approaches in pathology demonstrate significantly constrained reasoning capabilities, primarily due to their reliance on expensive chain-of-thought annotations. Additionally, existing methods remain limited to simplex application of visual question answering (VQA) at region-of-interest (ROI) level, failing to address the full spectrum of diagnostic needs such as ROI classification, detection, segmentation, whole-slide-image (WSI) classification and VQA in clinical practice. In this study, we present SmartPath-R1, a versatile MLLM capable of simultaneously addressing both ROI-level and WSI-level tasks while demonstrating robust pathological reasoning capability. Our framework combines scale-dependent supervised fine-tuning and task-aware reinforcement fine-tuning, which circumvents the requirement for chain-of-thought supervision by leveraging the intrinsic knowledge within MLLM. Furthermore, SmartPath-R1 integrates multiscale and multitask analysis through a mixture-of-experts mechanism, enabling dynamic processing for diverse tasks. We curate a large-scale dataset comprising 2.3M ROI samples and 188K WSI samples for training and evaluation. Extensive experiments across 72 tasks validate the effectiveness and superiority of the proposed approach. This work represents a significant step toward developing versatile, reasoning-enhanced AI systems for precision pathology.
Advancing Lung Disease Diagnosis in 3D CT Scans
Jul 01, 2025To enable more accurate diagnosis of lung disease in chest CT scans, we propose a straightforward yet effective model. Firstly, we analyze the characteristics of 3D CT scans and remove non-lung regions, which helps the model focus on lesion-related areas and reduces computational cost. We adopt ResNeSt50 as a strong feature extractor, and use a weighted cross-entropy loss to mitigate class imbalance, especially for the underrepresented squamous cell carcinoma category. Our model achieves a Macro F1 Score of 0.80 on the validation set of the Fair Disease Diagnosis Challenge, demonstrating its strong performance in distinguishing between different lung conditions.
Segment Anything in Pathology Images with Natural Language
Jun 26, 2025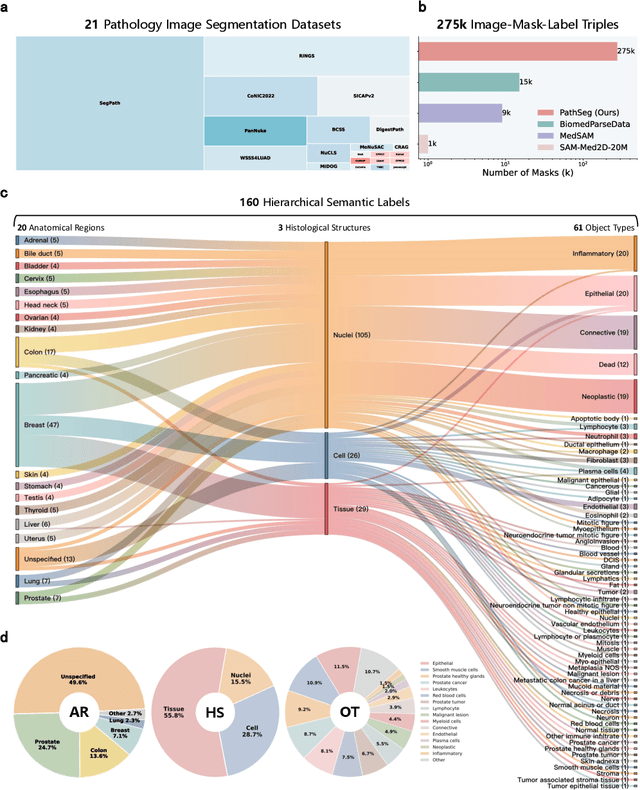
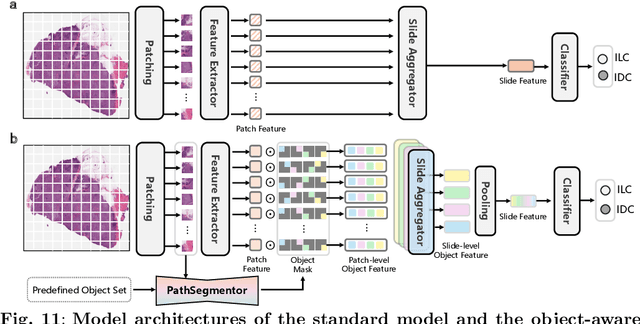
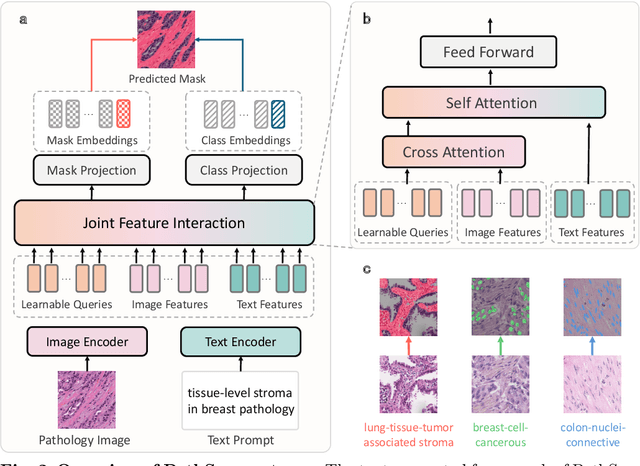
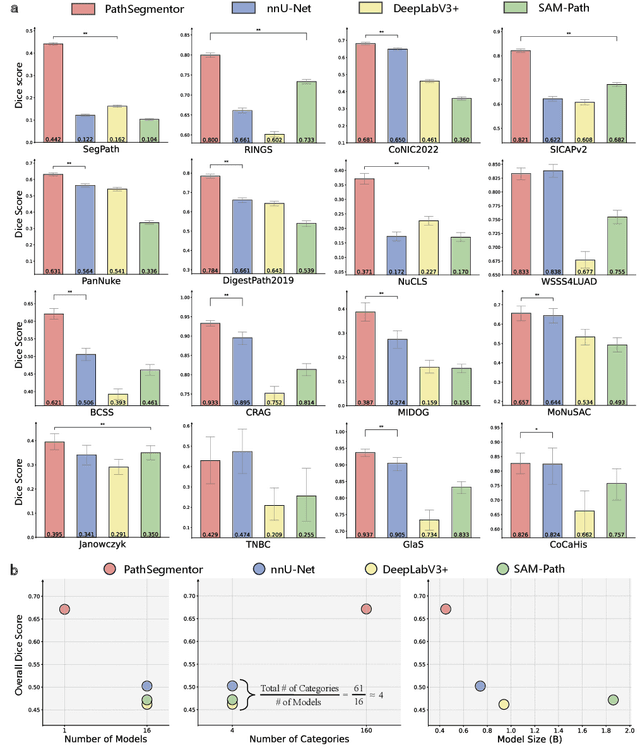
Pathology image segmentation is crucial in computational pathology for analyzing histological features relevant to cancer diagnosis and prognosis. However, current methods face major challenges in clinical applications due to limited annotated data and restricted category definitions. To address these limitations, we propose PathSegmentor, the first text-prompted segmentation foundation model designed specifically for pathology images. We also introduce PathSeg , the largest and most comprehensive dataset for pathology segmentation, built from 17 public sources and containing 275k image-mask-label triples across 160 diverse categories. With PathSegmentor, users can perform semantic segmentation using natural language prompts, eliminating the need for laborious spatial inputs such as points or boxes. Extensive experiments demonstrate that PathSegmentor outperforms specialized models with higher accuracy and broader applicability, while maintaining a compact architecture. It significantly surpasses existing spatial- and text-prompted models by 0.145 and 0.429 in overall Dice scores, respectively, showing strong robustness in segmenting complex structures and generalizing to external datasets. Moreover, PathSegmentor's outputs enhance the interpretability of diagnostic models through feature importance estimation and imaging biomarker discovery, offering pathologists evidence-based support for clinical decision-making. This work advances the development of explainable AI in precision oncology.
EgoExo-Gen: Ego-centric Video Prediction by Watching Exo-centric Videos
Apr 16, 2025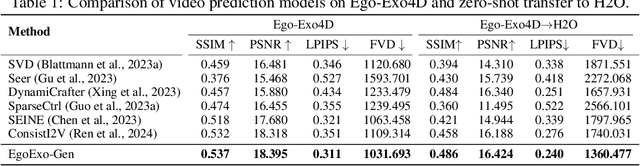
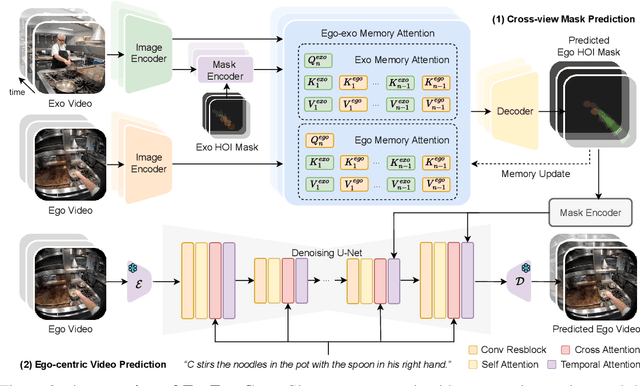

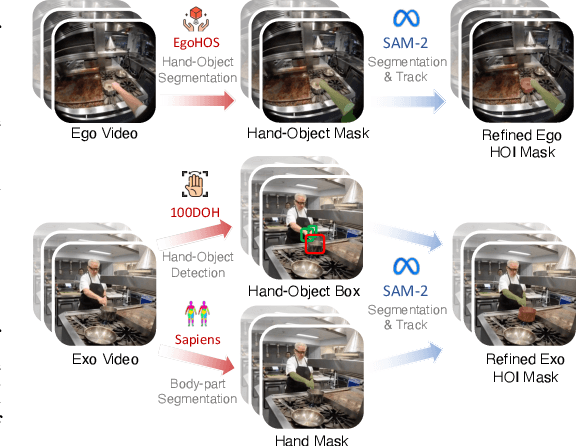
Generating videos in the first-person perspective has broad application prospects in the field of augmented reality and embodied intelligence. In this work, we explore the cross-view video prediction task, where given an exo-centric video, the first frame of the corresponding ego-centric video, and textual instructions, the goal is to generate futur frames of the ego-centric video. Inspired by the notion that hand-object interactions (HOI) in ego-centric videos represent the primary intentions and actions of the current actor, we present EgoExo-Gen that explicitly models the hand-object dynamics for cross-view video prediction. EgoExo-Gen consists of two stages. First, we design a cross-view HOI mask prediction model that anticipates the HOI masks in future ego-frames by modeling the spatio-temporal ego-exo correspondence. Next, we employ a video diffusion model to predict future ego-frames using the first ego-frame and textual instructions, while incorporating the HOI masks as structural guidance to enhance prediction quality. To facilitate training, we develop an automated pipeline to generate pseudo HOI masks for both ego- and exo-videos by exploiting vision foundation models. Extensive experiments demonstrate that our proposed EgoExo-Gen achieves better prediction performance compared to previous video prediction models on the Ego-Exo4D and H2O benchmark datasets, with the HOI masks significantly improving the generation of hands and interactive objects in the ego-centric videos.
Cross-Fundus Transformer for Multi-modal Diabetic Retinopathy Grading with Cataract
Nov 01, 2024



Diabetic retinopathy (DR) is a leading cause of blindness worldwide and a common complication of diabetes. As two different imaging tools for DR grading, color fundus photography (CFP) and infrared fundus photography (IFP) are highly-correlated and complementary in clinical applications. To the best of our knowledge, this is the first study that explores a novel multi-modal deep learning framework to fuse the information from CFP and IFP towards more accurate DR grading. Specifically, we construct a dual-stream architecture Cross-Fundus Transformer (CFT) to fuse the ViT-based features of two fundus image modalities. In particular, a meticulously engineered Cross-Fundus Attention (CFA) module is introduced to capture the correspondence between CFP and IFP images. Moreover, we adopt both the single-modality and multi-modality supervisions to maximize the overall performance for DR grading. Extensive experiments on a clinical dataset consisting of 1,713 pairs of multi-modal fundus images demonstrate the superiority of our proposed method. Our code will be released for public access.