 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLA: Achieving Ternary Weights and Low-Bit Activations for LLMs via Post-Training Quantization
Jun 11, 2026Large language models (LLMs) exhibit exceptional general language processing capabilities, but their memory and compute costs hinder deployment. Ternarization has emerged as a promising compression technique, offering significant reductions in model size and inference complexity. However, existing methods struggle with heavy-tailed activation distributions and therefore keep activations in high precision, fundamentally limiting end-to-end inference acceleration. To overcome this limitation, we propose TWLA, a post-training quantization (PTQ) framework that achieves 1.58-bit weight compression and 4-bit activation quantization while maintaining high accuracy. TWLA comprises three components: (1) Euclidean-to-Manifold Asymmetric Ternary Quantizer (E2M-ATQ) minimizes layer-output error under weight ternarization via a two-stage optimization from Euclidean initialization to manifold relocation; (2) Kronecker Orthogonal Tri-Modal Shaping (KOTMS) applies a Kronecker-structured orthogonal rotation to reshape weights into ternary-friendly tri-modal distributions, while the shared rotation statistically suppresses activation outliers; and (3) Inter-Layer Aware Activation Mixed Precision (ILA-AMP) explicitly introduces adjacent-layer second-order interaction costs in bit allocation and jointly optimizes for the layer-wise disparity of activation quantization gains induced by the shared orthogonal transform, preventing cascades triggered by a few weak layers. Extensive experiments demonstrate that TWLA maintains high accuracy under W1.58A4, while delivering significant inference acceleration. The code is available at <https://github.com/Kishon-zzx/TWLA>.
Cross-Modal Clinical Knowledge Integration for Mammography Report Generation
May 29, 2026Breast cancer is a major global health concern, and mammography screening plays a central role in early detection. The large volume of screening examinations creates a substantial workload for radiologists, making accurate and consistent report generation a critical clinical challenge. Existing automated mammography report generation methods primarily focus on direct visual-to-text mapping, while overlooking the structured clinical reasoning process followed by radiologists in real-world practice. To address this limitation, we propose MammoRG, a mammography report generation framework that explicitly simulates the clinical reporting workflow by following the BI-RADS guideline and incorporating prior clinical knowledge to produce diagnostic reports. Specifically, MammoRG adopts a two-stage training framework. In the first stage, the model learns to integrate clinically relevant prior knowledge from a patient's four-view mammograms through classification-based supervision. In the second stage, a terminology-aware supervised fine-tuning strategy is introduced to model mammography-specific clinical terms as atomic semantic units, enabling the generation of high-quality reports with improved clinical consistency. To facilitate clinical efficacy evaluation of generated reports, we further develop MammoRGTool, a dedicated mammography report parsing tool that extracts structured clinical information from free-text reports. Extensive experiments demonstrate that MammoRG consistently outperforms existing methods across multiple clinical efficacy metrics, particularly in diagnosis-related BI-RADS F1, where it surpasses the second-best model by 2.73%, 2.04%, 1.90%, and 3.27% on the internal, external 1, external 2, and VinDr-Mammo datasets, respectively.
A Clinically Validated Foundation Model for Comprehensive Lung Pathology Interpretation
May 25, 2026Pathological assessment guides lung cancer diagnosis, treatment selection, and prognostic evaluation, yet current CPath approaches rely on task-specific models for isolated objectives. Although pan-cancer foundation models offer versatility, they lack subspecialty-level depth and have not been evaluated across clinical workflows or prospectively validated in real-world settings. We introduce PulmoFoundation, a multi-center, prospectively validated, randomized controlled trial (RCT)-evaluated foundation model for comprehensive lung pathology assessment across pre-operative, intra-operative, and post-operative care. Built upon Virchow2 via subspecialty-specific pretraining using ~40,000 diagnostic H&E-stained whole-slide images (WSIs), PulmoFoundation was systematically evaluated on ~26,000 WSIs across 32 clinically relevant tasks. In addition to accurately predicting molecular markers and patient survival, our model achieves clinical-grade performance in core diagnostic tasks across biopsy, frozen section, and surgical resection slides. In a registered prospective study of 1,357 patients across 11 diagnostic tasks, our model achieved an average AUC of 92.3%. Using pre-specified triage thresholds, PulmoFoundation could reduce additional second-review burden for 68.8% of biopsies and 83.0% of frozen sections, and defer 44.5% of IHC stain orders, with PPVs of 1.0, 0.991, and 0.966. Beyond prospective validation, we conducted a crossover RCT with eight pathologists, in which AI assistance improved diagnostic accuracy across 4,928 case-reader pairs (91.7% w/ AI vs. 83.8% w/o AI). AI assistance also reduced median diagnostic time by 19.6%, increased diagnostic confidence by 8.7%, and improved inter-rater agreement from moderate (kappa = 0.56) to substantial (kappa = 0.76). Together, these evaluations support PulmoFoundation as a clinically validated decision-support system for lung pathology.
MoBiE: Efficient Inference of Mixture of Binary Experts under Post-Training Quantization
Apr 08, 2026Mixture-of-Experts (MoE) based large language models (LLMs) offer strong performance but suffer from high memory and computation costs. Weight binarization provides extreme efficiency, yet existing binary methods designed for dense LLMs struggle with MoE-specific issues, including cross-expert redundancy, task-agnostic importance estimation, and quantization-induced routing shifts. To this end, we propose MoBiE, the first binarization framework tailored for MoE-based LLMs. MoBiE is built on three core innovations: 1. using joint SVD decomposition to reduce cross-expert redundancy; 2. integrating global loss gradients into local Hessian metrics to enhance weight importance estimation; 3. introducing an error constraint guided by the input null space to mitigate routing distortion. Notably, MoBiE achieves these optimizations while incurring no additional storage overhead, striking a balance between efficiency and model performance. Extensive experiments demonstrate that MoBiE consistently outperforms state-of-the-art binary methods across multiple MoE-based LLMs and benchmarks. For example, on Qwen3-30B-A3B, MoBiE reduces perplexity by 52.2$\%$, improves average zero-shot performance by 43.4$\%$, achieves over 2 $\times$ inference speedup, and further shortens quantization time. The code is available at https://github.com/Kishon-zzx/MoBiE.
SAES-SVD: Self-Adaptive Suppression of Accumulated and Local Errors for SVD-based LLM Compression
Feb 03, 2026The rapid growth in the parameter scale of large language models (LLMs) has created a high demand for efficient compression techniques. As a hardware-agnostic and highly compatible technique, low-rank compression has been widely adopted. However, existing methods typically compress each layer independently by minimizing per-layer reconstruction error, overlooking a critical limitation: the reconstruction error propagates and accumulates through the network, which leads to amplified global deviations from the full-precision baseline. To address this, we propose Self-Adaptive Error Suppression SVD (SAES-SVD), a LLMs compression framework that jointly optimizes intra-layer reconstruction and inter-layer error compensation. SAES-SVD is composed of two novel components: (1) Cumulative Error-Aware Layer Compression (CEALC), which formulates the compression objective as a combination of local reconstruction and weighted cumulative error compensation. Based on it, we derive a closed-form low-rank solution relied on second-order activation statistics, which explicitly aligns each layer's output with its full-precision counterpart to compensate for accumulated errors. (2) Adaptive Collaborative Error Suppression (ACES), which automatically adjusts the weighting coefficient to enhance the low-rank structure of the compression objective in CEALC. Specifically, the coefficient is optimized to maximize the ratio between the Frobenius norm of the compressed layer's output and that of the compression objective under a fixed rank, thus ensuring that the rank budget is utilized effectively. Extensive experiments across multiple LLM architectures and tasks show that, without fine-tuning or mixed-rank strategies, SAES-SVD consistently improves post-compression performance.
OTARo: Once Tuning for All Precisions toward Robust On-Device LLMs
Nov 17, 2025Large Language Models (LLMs) fine-tuning techniques not only improve the adaptability to diverse downstream tasks, but also mitigate adverse effects of model quantization. Despite this, conventional quantization suffers from its structural limitation that hinders flexibility during the fine-tuning and deployment stages. Practical on-device tasks demand different quantization precisions (i.e. different bit-widths), e.g., understanding tasks tend to exhibit higher tolerance to reduced precision compared to generation tasks. Conventional quantization, typically relying on scaling factors that are incompatible across bit-widths, fails to support the on-device switching of precisions when confronted with complex real-world scenarios. To overcome the dilemma, we propose OTARo, a novel method that enables on-device LLMs to flexibly switch quantization precisions while maintaining performance robustness through once fine-tuning. OTARo introduces Shared Exponent Floating Point (SEFP), a distinct quantization mechanism, to produce different bit-widths through simple mantissa truncations of a single model. Moreover, to achieve bit-width robustness in downstream applications, OTARo performs a learning process toward losses induced by different bit-widths. The method involves two critical strategies: (1) Exploitation-Exploration Bit-Width Path Search (BPS), which iteratively updates the search path via a designed scoring mechanism; (2) Low-Precision Asynchronous Accumulation (LAA), which performs asynchronous gradient accumulations and delayed updates under low bit-widths. Experiments on popular LLMs, e.g., LLaMA3.2-1B, LLaMA3-8B, demonstrate that OTARo achieves consistently strong and robust performance for all precisions.
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domains
Nov 14, 2025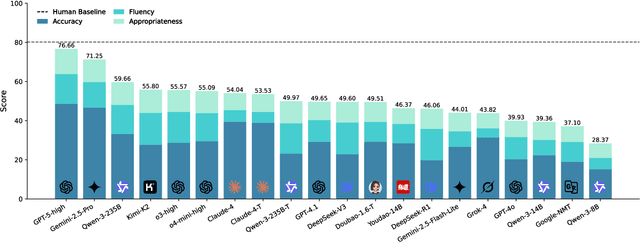

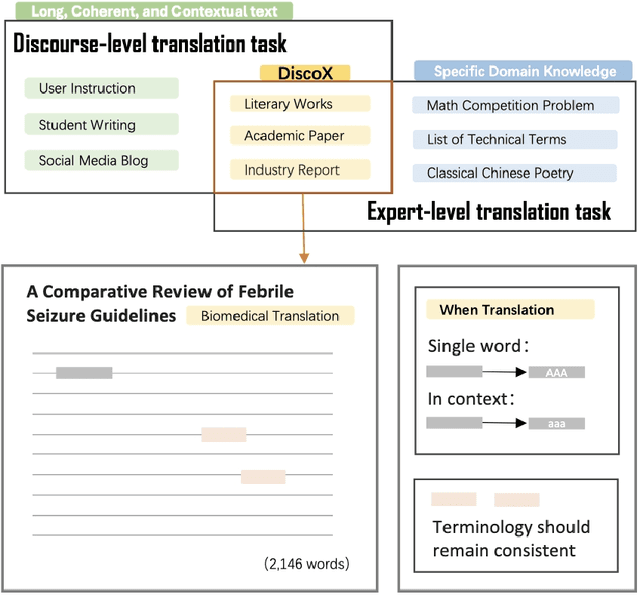

The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
A Versatile Pathology Co-pilot via Reasoning Enhanced Multimodal Large Language Model
Jul 23, 2025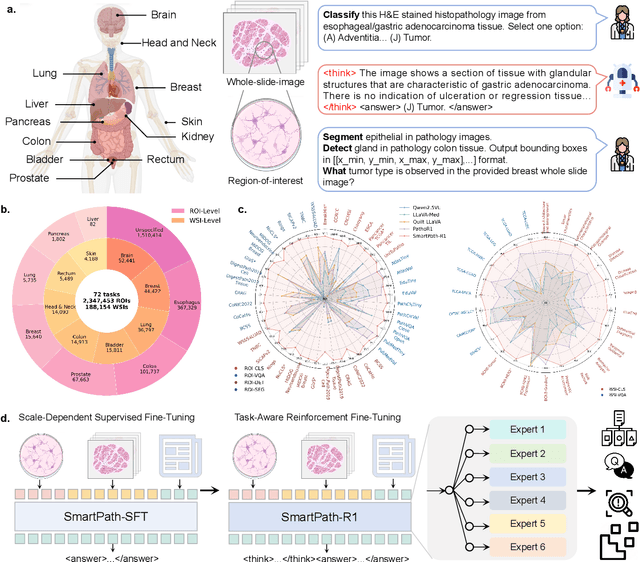
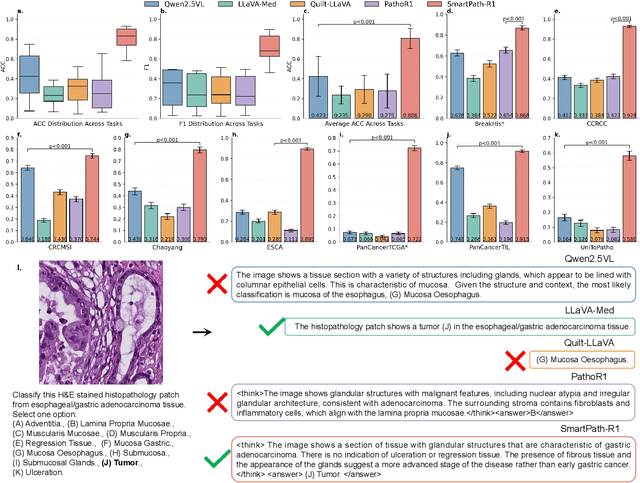
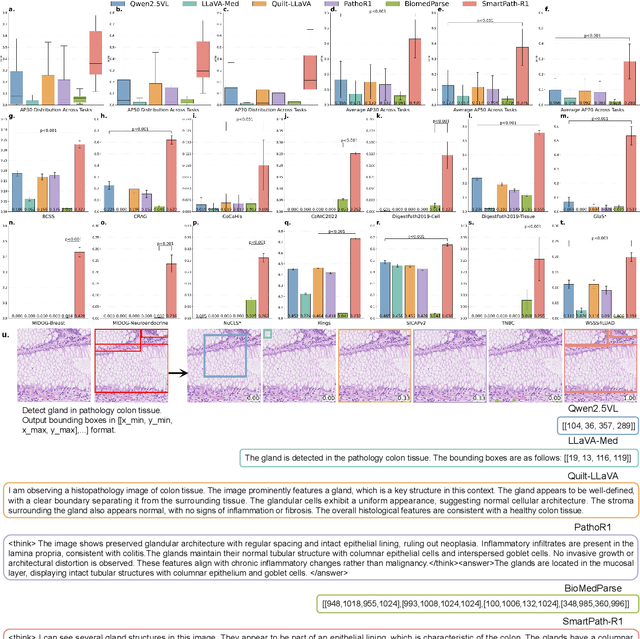
Multimodal large language models (MLLMs) have emerged as powerful tools for computational pathology, offering unprecedented opportunities to integrate pathological images with language context for comprehensive diagnostic analysis. These models hold particular promise for automating complex tasks that traditionally require expert interpretation of pathologists. However, current MLLM approaches in pathology demonstrate significantly constrained reasoning capabilities, primarily due to their reliance on expensive chain-of-thought annotations. Additionally, existing methods remain limited to simplex application of visual question answering (VQA) at region-of-interest (ROI) level, failing to address the full spectrum of diagnostic needs such as ROI classification, detection, segmentation, whole-slide-image (WSI) classification and VQA in clinical practice. In this study, we present SmartPath-R1, a versatile MLLM capable of simultaneously addressing both ROI-level and WSI-level tasks while demonstrating robust pathological reasoning capability. Our framework combines scale-dependent supervised fine-tuning and task-aware reinforcement fine-tuning, which circumvents the requirement for chain-of-thought supervision by leveraging the intrinsic knowledge within MLLM. Furthermore, SmartPath-R1 integrates multiscale and multitask analysis through a mixture-of-experts mechanism, enabling dynamic processing for diverse tasks. We curate a large-scale dataset comprising 2.3M ROI samples and 188K WSI samples for training and evaluation. Extensive experiments across 72 tasks validate the effectiveness and superiority of the proposed approach. This work represents a significant step toward developing versatile, reasoning-enhanced AI systems for precision pathology.
Segment Anything in Pathology Images with Natural Language
Jun 26, 2025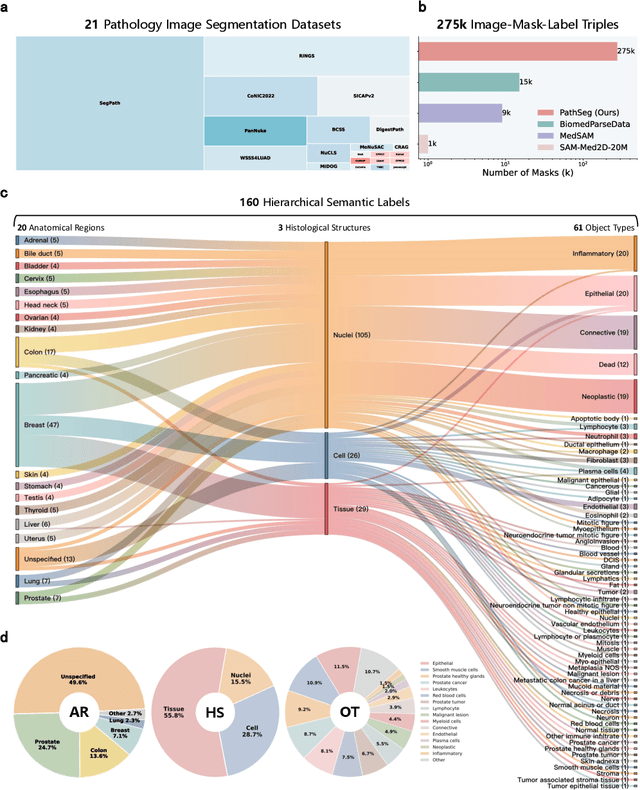
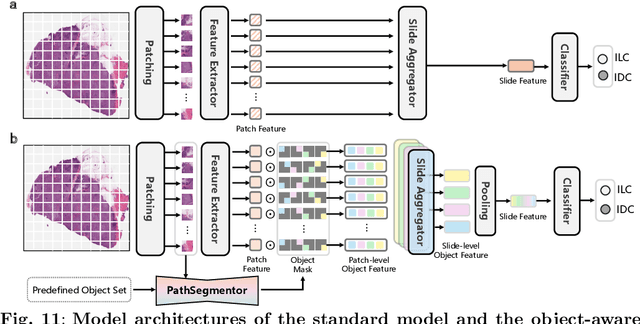
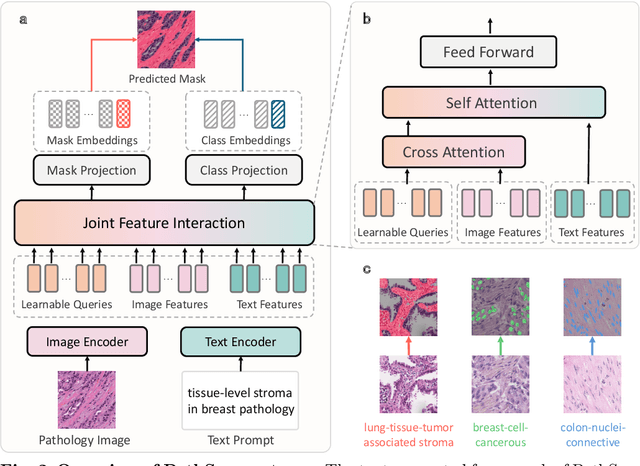
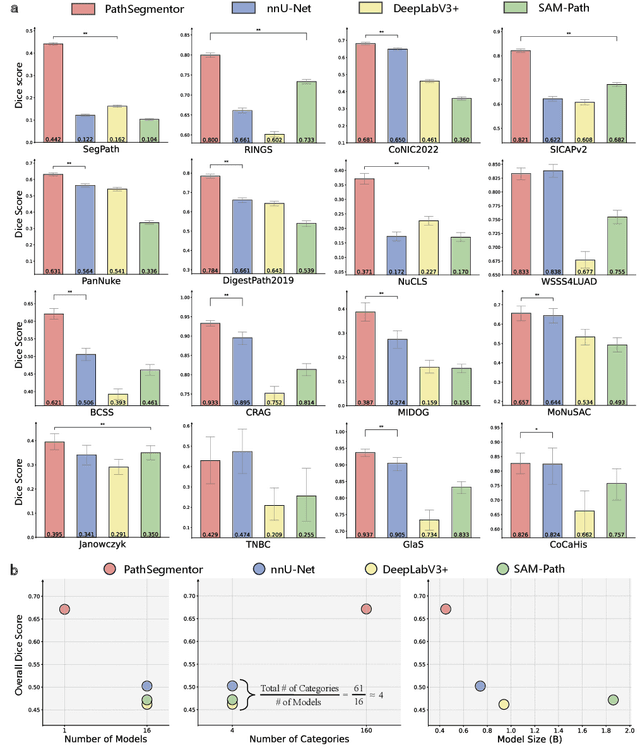
Pathology image segmentation is crucial in computational pathology for analyzing histological features relevant to cancer diagnosis and prognosis. However, current methods face major challenges in clinical applications due to limited annotated data and restricted category definitions. To address these limitations, we propose PathSegmentor, the first text-prompted segmentation foundation model designed specifically for pathology images. We also introduce PathSeg , the largest and most comprehensive dataset for pathology segmentation, built from 17 public sources and containing 275k image-mask-label triples across 160 diverse categories. With PathSegmentor, users can perform semantic segmentation using natural language prompts, eliminating the need for laborious spatial inputs such as points or boxes. Extensive experiments demonstrate that PathSegmentor outperforms specialized models with higher accuracy and broader applicability, while maintaining a compact architecture. It significantly surpasses existing spatial- and text-prompted models by 0.145 and 0.429 in overall Dice scores, respectively, showing strong robustness in segmenting complex structures and generalizing to external datasets. Moreover, PathSegmentor's outputs enhance the interpretability of diagnostic models through feature importance estimation and imaging biomarker discovery, offering pathologists evidence-based support for clinical decision-making. This work advances the development of explainable AI in precision oncology.
RWKVQuant: Quantizing the RWKV Family with Proxy Guided Hybrid of Scalar and Vector Quantization
May 02, 2025



RWKV is a modern RNN architecture with comparable performance to Transformer, but still faces challenges when deployed to resource-constrained devices. Post Training Quantization (PTQ), which is a an essential technique to reduce model size and inference latency, has been widely used in Transformer models. However, it suffers significant degradation of performance when applied to RWKV. This paper investigates and identifies two key constraints inherent in the properties of RWKV: (1) Non-linear operators hinder the parameter-fusion of both smooth- and rotation-based quantization, introducing extra computation overhead. (2) The larger amount of uniformly distributed weights poses challenges for cluster-based quantization, leading to reduced accuracy. To this end, we propose RWKVQuant, a PTQ framework tailored for RWKV models, consisting of two novel techniques: (1) a coarse-to-fine proxy capable of adaptively selecting different quantization approaches by assessing the uniformity and identifying outliers in the weights, and (2) a codebook optimization algorithm that enhances the performance of cluster-based quantization methods for element-wise multiplication in RWKV. Experiments show that RWKVQuant can quantize RWKV-6-14B into about 3-bit with less than 1% accuracy loss and 2.14x speed up.