 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything in Pathology Images with Natural Language
Jun 26, 2025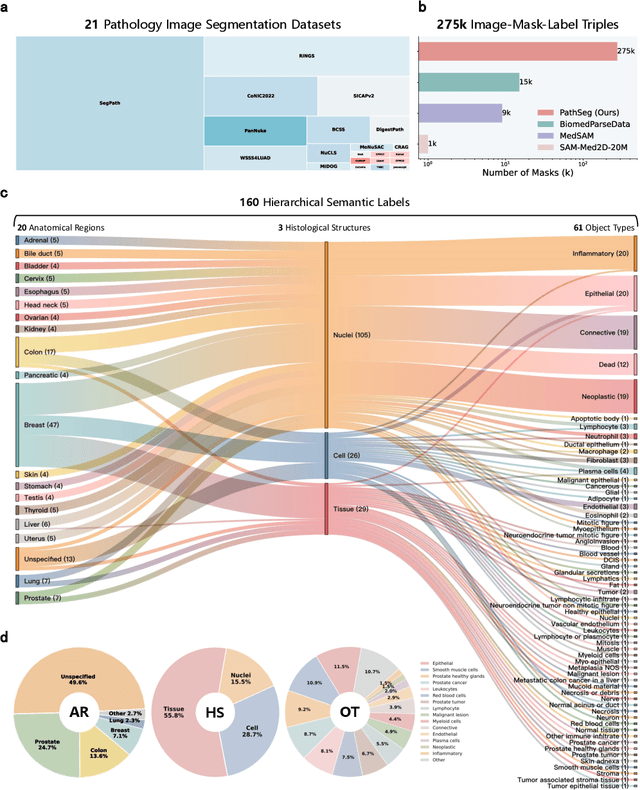
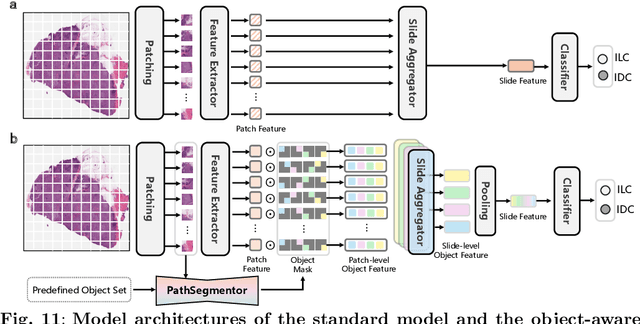
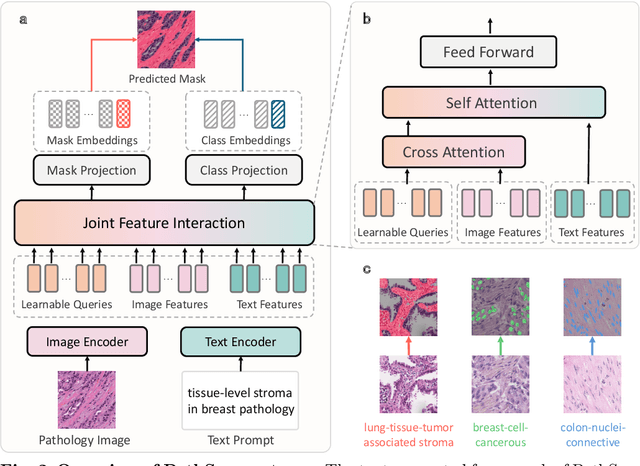
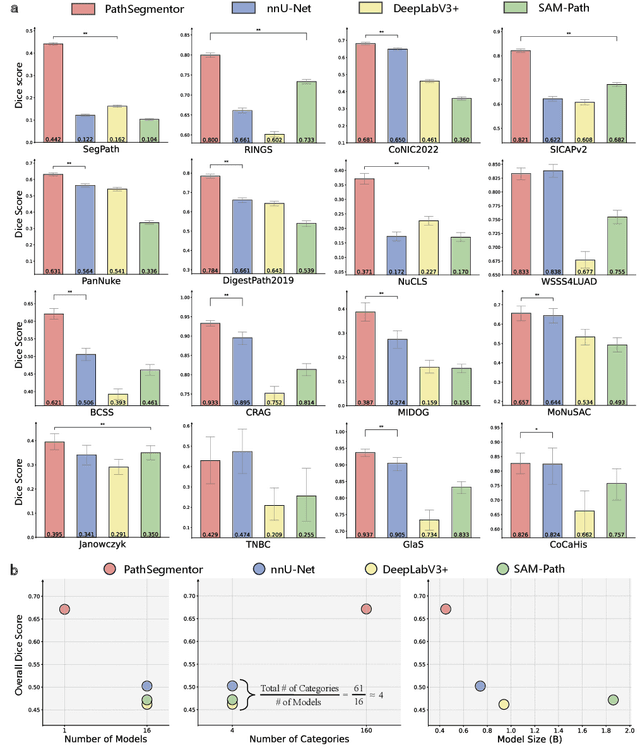
Pathology image segmentation is crucial in computational pathology for analyzing histological features relevant to cancer diagnosis and prognosis. However, current methods face major challenges in clinical applications due to limited annotated data and restricted category definitions. To address these limitations, we propose PathSegmentor, the first text-prompted segmentation foundation model designed specifically for pathology images. We also introduce PathSeg , the largest and most comprehensive dataset for pathology segmentation, built from 17 public sources and containing 275k image-mask-label triples across 160 diverse categories. With PathSegmentor, users can perform semantic segmentation using natural language prompts, eliminating the need for laborious spatial inputs such as points or boxes. Extensive experiments demonstrate that PathSegmentor outperforms specialized models with higher accuracy and broader applicability, while maintaining a compact architecture. It significantly surpasses existing spatial- and text-prompted models by 0.145 and 0.429 in overall Dice scores, respectively, showing strong robustness in segmenting complex structures and generalizing to external datasets. Moreover, PathSegmentor's outputs enhance the interpretability of diagnostic models through feature importance estimation and imaging biomarker discovery, offering pathologists evidence-based support for clinical decision-making. This work advances the development of explainable AI in precision oncology.
ConceptCLIP: Towards Trustworthy Medical AI via Concept-Enhanced Contrastive Langauge-Image Pre-training
Jan 26, 2025Trustworthiness is essential for the precise and interpretable application of artificial intelligence (AI) in medical imaging. Traditionally, precision and interpretability have been addressed as separate tasks, namely medical image analysis and explainable AI, each developing its own models independently. In this study, for the first time, we investigate the development of a unified medical vision-language pre-training model that can achieve both accurate analysis and interpretable understanding of medical images across various modalities. To build the model, we construct MedConcept-23M, a large-scale dataset comprising 23 million medical image-text pairs extracted from 6.2 million scientific articles, enriched with concepts from the Unified Medical Language System (UMLS). Based on MedConcept-23M, we introduce ConceptCLIP, a medical AI model utilizing concept-enhanced contrastive language-image pre-training. The pre-training of ConceptCLIP involves two primary components: image-text alignment learning (IT-Align) and patch-concept alignment learning (PC-Align). This dual alignment strategy enhances the model's capability to associate specific image regions with relevant concepts, thereby improving both the precision of analysis and the interpretability of the AI system. We conducted extensive experiments on 5 diverse types of medical image analysis tasks, spanning 51 subtasks across 10 image modalities, with the broadest range of downstream tasks. The results demonstrate the effectiveness of the proposed vision-language pre-training model. Further explainability analysis across 6 modalities reveals that ConceptCLIP achieves superior performance, underscoring its robust ability to advance explainable AI in medical imaging. These findings highlight ConceptCLIP's capability in promoting trustworthy AI in the field of medicine.
Chain of Attack: On the Robustness of Vision-Language Models Against Transfer-Based Adversarial Attacks
Nov 24, 2024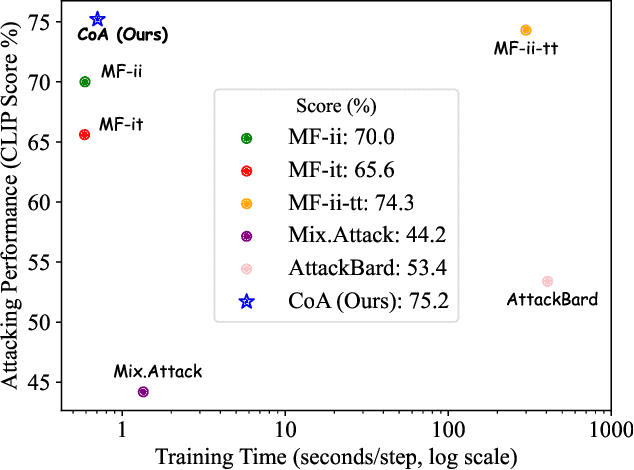
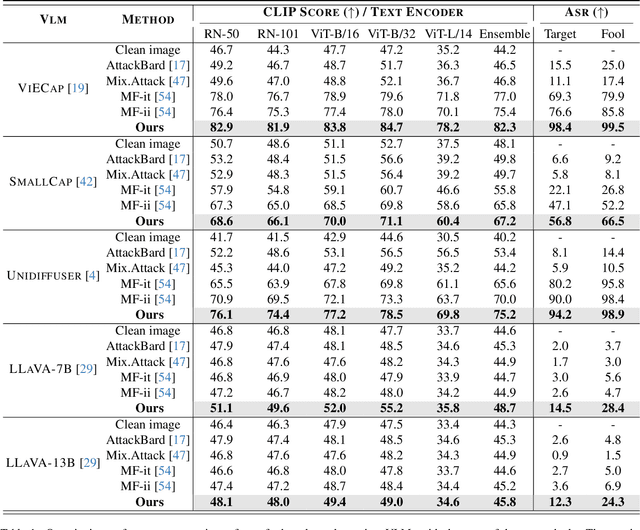
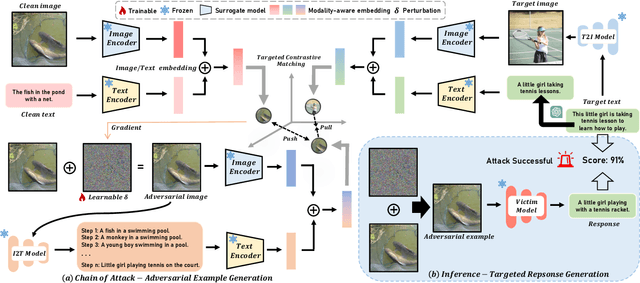
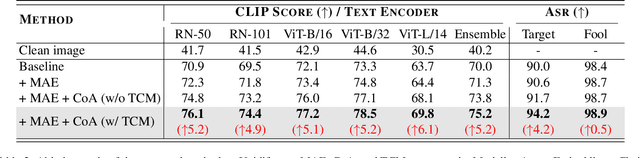
Pre-trained vision-language models (VLMs) have showcased remarkable performance in image and natural language understanding, such as image captioning and response generation. As the practical applications of vision-language models become increasingly widespread, their potential safety and robustness issues raise concerns that adversaries may evade the system and cause these models to generate toxic content through malicious attacks. Therefore, evaluating the robustness of open-source VLMs against adversarial attacks has garnered growing attention, with transfer-based attacks as a representative black-box attacking strategy. However, most existing transfer-based attacks neglect the importance of the semantic correlations between vision and text modalities, leading to sub-optimal adversarial example generation and attack performance. To address this issue, we present Chain of Attack (CoA), which iteratively enhances the generation of adversarial examples based on the multi-modal semantic update using a series of intermediate attacking steps, achieving superior adversarial transferability and efficiency. A unified attack success rate computing method is further proposed for automatic evasion evaluation. Extensive experiments conducted under the most realistic and high-stakes scenario, demonstrate that our attacking strategy can effectively mislead models to generate targeted responses using only black-box attacks without any knowledge of the victim models. The comprehensive robustness evaluation in our paper provides insight into the vulnerabilities of VLMs and offers a reference for the safety considerations of future model developments.
Large Language Model with Region-guided Referring and Grounding for CT Report Generation
Nov 23, 2024



Computed tomography (CT) report generation is crucial to assist radiologists in interpreting CT volumes, which can be time-consuming and labor-intensive. Existing methods primarily only consider the global features of the entire volume, making it struggle to focus on specific regions and potentially missing abnormalities. To address this issue, we propose Reg2RG, the first region-guided referring and grounding framework for CT report generation, which enhances diagnostic performance by focusing on anatomical regions within the volume. Specifically, we utilize masks from a universal segmentation module to capture local features for each referring region. A local feature decoupling (LFD) strategy is proposed to preserve the local high-resolution details with little computational overhead. Then the local features are integrated with global features to capture inter-regional relationships within a cohesive context. Moreover, we propose a novel region-report alignment (RRA) training strategy. It leverages the recognition of referring regions to guide the generation of region-specific reports, enhancing the model's referring and grounding capabilities while also improving the report's interpretability. A large language model (LLM) is further employed as the language decoder to generate reports from integrated visual features, facilitating region-level comprehension. Extensive experiments on two large-scale chest CT-report datasets demonstrate the superiority of our method, which outperforms several state-of-the-art methods in terms of both natural language generation and clinical efficacy metrics while preserving promising interpretability. The code will be made publicly available.
Self-eXplainable AI for Medical Image Analysis: A Survey and New Outlooks
Oct 03, 2024



The increasing demand for transparent and reliable models, particularly in high-stakes decision-making areas such as medical image analysis, has led to the emergence of eXplainable Artificial Intelligence (XAI). Post-hoc XAI techniques, which aim to explain black-box models after training, have been controversial in recent works concerning their fidelity to the models' predictions. In contrast, Self-eXplainable AI (S-XAI) offers a compelling alternative by incorporating explainability directly into the training process of deep learning models. This approach allows models to generate inherent explanations that are closely aligned with their internal decision-making processes. Such enhanced transparency significantly supports the trustworthiness, robustness, and accountability of AI systems in real-world medical applications. To facilitate the development of S-XAI methods for medical image analysis, this survey presents an comprehensive review across various image modalities and clinical applications. It covers more than 200 papers from three key perspectives: 1) input explainability through the integration of explainable feature engineering and knowledge graph, 2) model explainability via attention-based learning, concept-based learning, and prototype-based learning, and 3) output explainability by providing counterfactual explanation and textual explanation. Additionally, this paper outlines the desired characteristics of explainability and existing evaluation methods for assessing explanation quality. Finally, it discusses the major challenges and future research directions in developing S-XAI for medical image analysis.
Dia-LLaMA: Towards Large Language Model-driven CT Report Generation
Mar 25, 2024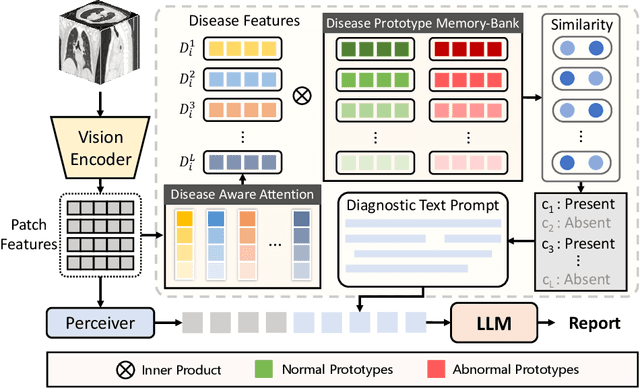


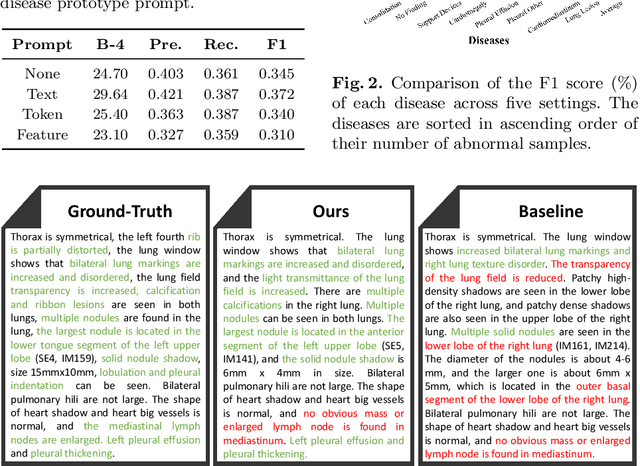
Medical report generation has achieved remarkable advancements yet has still been faced with several challenges. First, the inherent imbalance in the distribution of normal and abnormal cases may lead models to exhibit a biased focus on normal samples, resulting in unreliable diagnoses. Second, the frequent occurrence of common template sentences in the reports may overwhelm the critical abnormal information. Moreover, existing works focus on 2D chest X-rays, leaving CT report generation underexplored due to the high-dimensional nature of CT images and the limited availability of CT-report pairs. Recently, LLM has shown a great ability to generate reliable answers with appropriate prompts, which shed light on addressing the aforementioned challenges. In this paper, we propose Dia-LLaMA, a framework to adapt the LLaMA2-7B for CT report generation by incorporating diagnostic information as guidance prompts. Considering the high dimension of CT, we leverage a pre-trained ViT3D with perceiver to extract the visual information. To tailor the LLM for report generation and emphasize abnormality, we extract additional diagnostic information by referring to a disease prototype memory bank, which is updated during training to capture common disease representations. Furthermore, we introduce disease-aware attention to enable the model to adjust attention for different diseases. Experiments on the chest CT dataset demonstrated that our proposed method outperformed previous methods and achieved state-of-the-art on both clinical efficacy performance and natural language generation metrics. The code will be made publically available.
XCoOp: Explainable Prompt Learning for Computer-Aided Diagnosis via Concept-guided Context Optimization
Mar 14, 2024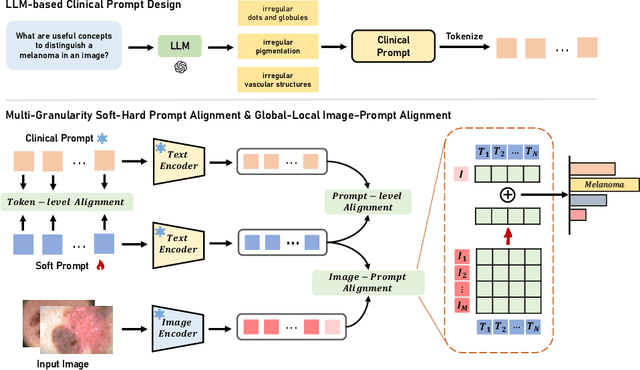
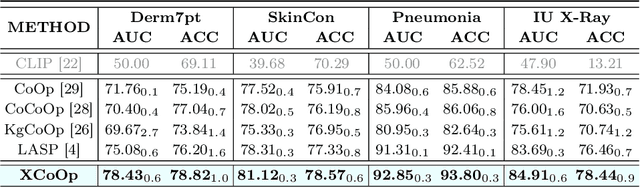
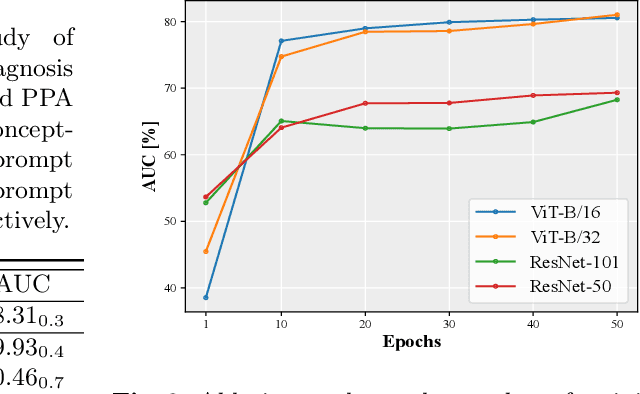
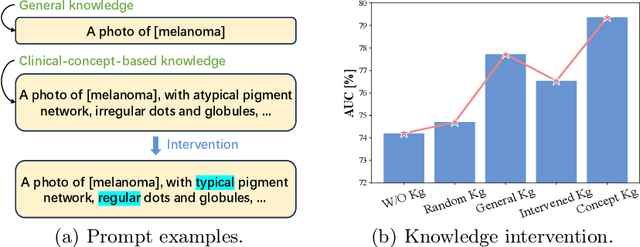
Utilizing potent representations of the large vision-language models (VLMs) to accomplish various downstream tasks has attracted increasing attention. Within this research field, soft prompt learning has become a representative approach for efficiently adapting VLMs such as CLIP, to tasks like image classification. However, most existing prompt learning methods learn text tokens that are unexplainable, which cannot satisfy the stringent interpretability requirements of Explainable Artificial Intelligence (XAI) in high-stakes scenarios like healthcare. To address this issue, we propose a novel explainable prompt learning framework that leverages medical knowledge by aligning the semantics of images, learnable prompts, and clinical concept-driven prompts at multiple granularities. Moreover, our framework addresses the lack of valuable concept annotations by eliciting knowledge from large language models and offers both visual and textual explanations for the prompts. Extensive experiments and explainability analyses conducted on various datasets, with and without concept labels, demonstrate that our method simultaneously achieves superior diagnostic performance, flexibility, and interpretability, shedding light on the effectiveness of foundation models in facilitating XAI. The code will be made publically available.
MICA: Towards Explainable Skin Lesion Diagnosis via Multi-Level Image-Concept Alignment
Jan 16, 2024Black-box deep learning approaches have showcased significant potential in the realm of medical image analysis. However, the stringent trustworthiness requirements intrinsic to the medical field have catalyzed research into the utilization of Explainable Artificial Intelligence (XAI), with a particular focus on concept-based methods. Existing concept-based methods predominantly apply concept annotations from a single perspective (e.g., global level), neglecting the nuanced semantic relationships between sub-regions and concepts embedded within medical images. This leads to underutilization of the valuable medical information and may cause models to fall short in harmoniously balancing interpretability and performance when employing inherently interpretable architectures such as Concept Bottlenecks. To mitigate these shortcomings, we propose a multi-modal explainable disease diagnosis framework that meticulously aligns medical images and clinical-related concepts semantically at multiple strata, encompassing the image level, token level, and concept level. Moreover, our method allows for model intervention and offers both textual and visual explanations in terms of human-interpretable concepts. Experimental results on three skin image datasets demonstrate that our method, while preserving model interpretability, attains high performance and label efficiency for concept detection and disease diagnosis.