 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Integrity for Modern Neural Networks: Structured Drift Proofs via Norm, Rank, and Sparsity Certificates
Apr 06, 2026Fine-tuning is now the primary method for adapting large neural networks, but it also introduces new integrity risks. An untrusted party can insert backdoors, change safety behavior, or overwrite large parts of a model while claiming only small updates. Existing verification tools focus on inference correctness or full-model provenance and do not address this problem. We introduce Fine-Tuning Integrity (FTI) as a security goal for controlled model evolution. An FTI system certifies that a fine-tuned model differs from a trusted base only within a policy-defined drift class. We propose Succinct Model Difference Proofs (SMDPs) as a new cryptographic primitive for enforcing these drift constraints. SMDPs provide zero-knowledge proofs that the update to a model is norm-bounded, low-rank, or sparse. The verifier cost depends only on the structure of the drift, not on the size of the model. We give concrete SMDP constructions based on random projections, polynomial commitments, and streaming linear checks. We also prove an information-theoretic lower bound showing that some form of structure is necessary for succinct proofs. Finally, we present architecture-aware instantiations for transformers, CNNs, and MLPs, together with an end-to-end system that aggregates block-level proofs into a global certificate.
AIvilization v0: Toward Large-Scale Artificial Social Simulation with a Unified Agent Architecture and Adaptive Agent Profiles
Feb 11, 2026AIvilization v0 is a publicly deployed large-scale artificial society that couples a resource-constrained sandbox economy with a unified LLM-agent architecture, aiming to sustain long-horizon autonomy while remaining executable under rapidly changing environment. To mitigate the tension between goal stability and reactive correctness, we introduce (i) a hierarchical branch-thinking planner that decomposes life goals into parallel objective branches and uses simulation-guided validation plus tiered re-planning to ensure feasibility; (ii) an adaptive agent profile with dual-process memory that separates short-term execution traces from long-term semantic consolidation, enabling persistent yet evolving identity; and (iii) a human-in-the-loop steering interface that injects long-horizon objectives and short commands at appropriate abstraction levels, with effects propagated through memory rather than brittle prompt overrides. The environment integrates physiological survival costs, non-substitutable multi-tier production, an AMM-based price mechanism, and a gated education-occupation system. Using high-frequency transactions from the platforms mature phase, we find stable markets that reproduce key stylized facts (heavy-tailed returns and volatility clustering) and produce structured wealth stratification driven by education and access constraints. Ablations show simplified planners can match performance on narrow tasks, while the full architecture is more robust under multi-objective, long-horizon settings, supporting delayed investment and sustained exploration.
Chain of Attack: On the Robustness of Vision-Language Models Against Transfer-Based Adversarial Attacks
Nov 24, 2024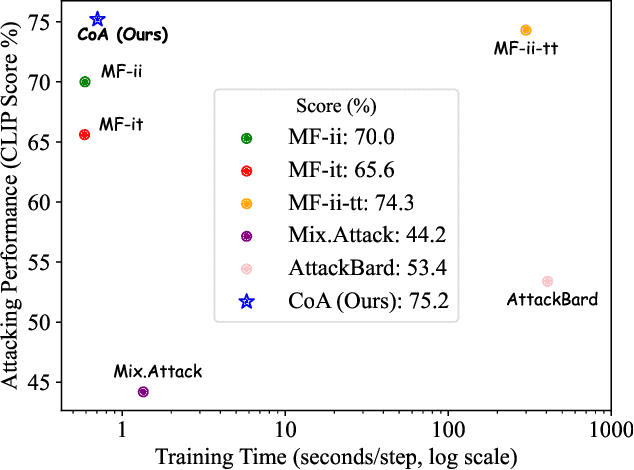
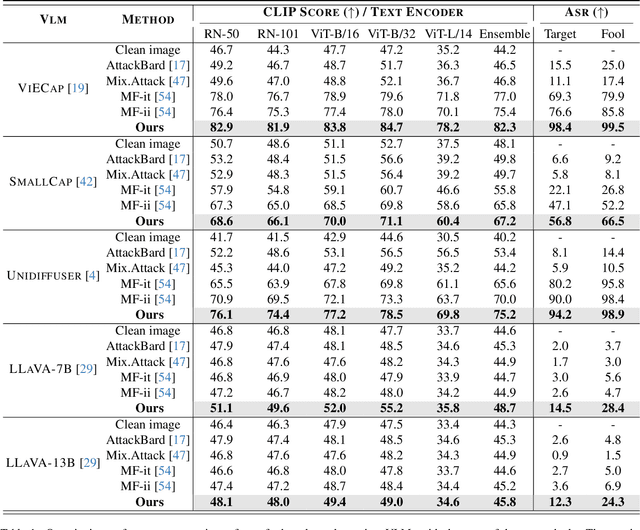
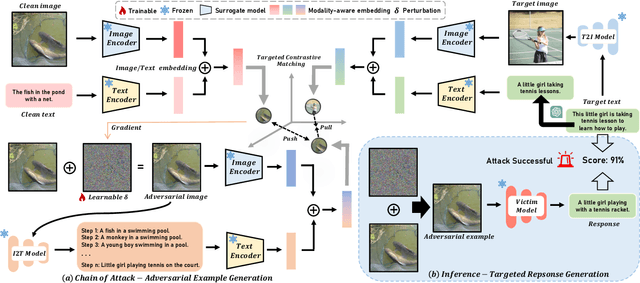
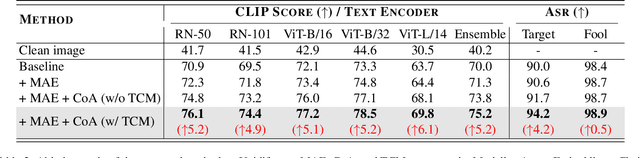
Pre-trained vision-language models (VLMs) have showcased remarkable performance in image and natural language understanding, such as image captioning and response generation. As the practical applications of vision-language models become increasingly widespread, their potential safety and robustness issues raise concerns that adversaries may evade the system and cause these models to generate toxic content through malicious attacks. Therefore, evaluating the robustness of open-source VLMs against adversarial attacks has garnered growing attention, with transfer-based attacks as a representative black-box attacking strategy. However, most existing transfer-based attacks neglect the importance of the semantic correlations between vision and text modalities, leading to sub-optimal adversarial example generation and attack performance. To address this issue, we present Chain of Attack (CoA), which iteratively enhances the generation of adversarial examples based on the multi-modal semantic update using a series of intermediate attacking steps, achieving superior adversarial transferability and efficiency. A unified attack success rate computing method is further proposed for automatic evasion evaluation. Extensive experiments conducted under the most realistic and high-stakes scenario, demonstrate that our attacking strategy can effectively mislead models to generate targeted responses using only black-box attacks without any knowledge of the victim models. The comprehensive robustness evaluation in our paper provides insight into the vulnerabilities of VLMs and offers a reference for the safety considerations of future model developments.
Efficient semi-supervised inference for logistic regression under case-control studies
Feb 23, 2024



Semi-supervised learning has received increasingly attention in statistics and machine learning. In semi-supervised learning settings, a labeled data set with both outcomes and covariates and an unlabeled data set with covariates only are collected. We consider an inference problem in semi-supervised settings where the outcome in the labeled data is binary and the labeled data is collected by case-control sampling. Case-control sampling is an effective sampling scheme for alleviating imbalance structure in binary data. Under the logistic model assumption, case-control data can still provide consistent estimator for the slope parameter of the regression model. However, the intercept parameter is not identifiable. Consequently, the marginal case proportion cannot be estimated from case-control data. We find out that with the availability of the unlabeled data, the intercept parameter can be identified in semi-supervised learning setting. We construct the likelihood function of the observed labeled and unlabeled data and obtain the maximum likelihood estimator via an iterative algorithm. The proposed estimator is shown to be consistent, asymptotically normal, and semiparametrically efficient. Extensive simulation studies are conducted to show the finite sample performance of the proposed method. The results imply that the unlabeled data not only helps to identify the intercept but also improves the estimation efficiency of the slope parameter. Meanwhile, the marginal case proportion can be estimated accurately by the proposed method.
Whisper-MCE: Whisper Model Finetuned for Better Performance with Mixed Languages
Oct 27, 2023
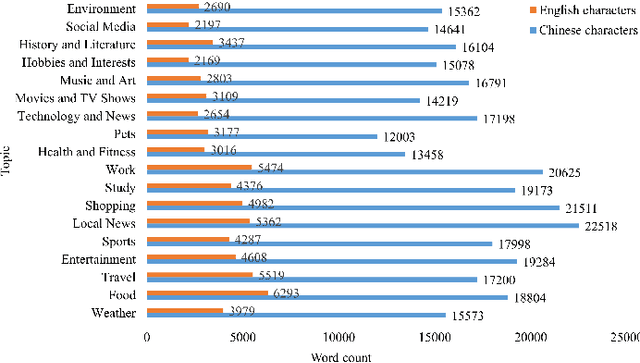
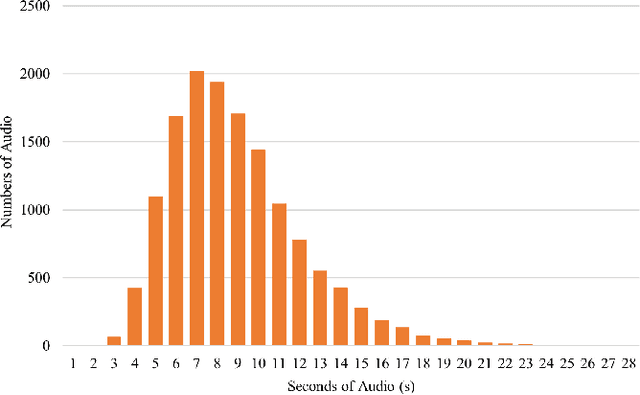

Recently Whisper has approached human-level robustness and accuracy in English automatic speech recognition (ASR), while in minor language and mixed language speech recognition, there remains a compelling need for further improvement. In this work, we present the impressive results of Whisper-MCE, our finetuned Whisper model, which was trained using our self-collected dataset, Mixed Cantonese and English audio dataset (MCE). Meanwhile, considering word error rate (WER) poses challenges when it comes to evaluating its effectiveness in minor language and mixed-language contexts, we present a novel rating mechanism. By comparing our model to the baseline whisper-large-v2 model, we demonstrate its superior ability to accurately capture the content of the original audio, achieve higher recognition accuracy, and exhibit faster recognition speed. Notably, our model outperforms other existing models in the specific task of recognizing mixed language.
Test-Time Compensated Representation Learning for Extreme Traffic Forecasting
Sep 16, 2023Traffic forecasting is a challenging task due to the complex spatio-temporal correlations among traffic series. In this paper, we identify an underexplored problem in multivariate traffic series prediction: extreme events. Road congestion and rush hours can result in low correlation in vehicle speeds at various intersections during adjacent time periods. Existing methods generally predict future series based on recent observations and entirely discard training data during the testing phase, rendering them unreliable for forecasting highly nonlinear multivariate time series. To tackle this issue, we propose a test-time compensated representation learning framework comprising a spatio-temporal decomposed data bank and a multi-head spatial transformer model (CompFormer). The former component explicitly separates all training data along the temporal dimension according to periodicity characteristics, while the latter component establishes a connection between recent observations and historical series in the data bank through a spatial attention matrix. This enables the CompFormer to transfer robust features to overcome anomalous events while using fewer computational resources. Our modules can be flexibly integrated with existing forecasting methods through end-to-end training, and we demonstrate their effectiveness on the METR-LA and PEMS-BAY benchmarks. Extensive experimental results show that our method is particularly important in extreme events, and can achieve significant improvements over six strong baselines, with an overall improvement of up to 28.2%.
Asymptotic Statistical Analysis of $f$-divergence GAN
Sep 14, 2022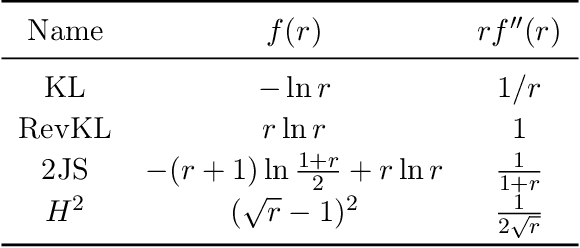
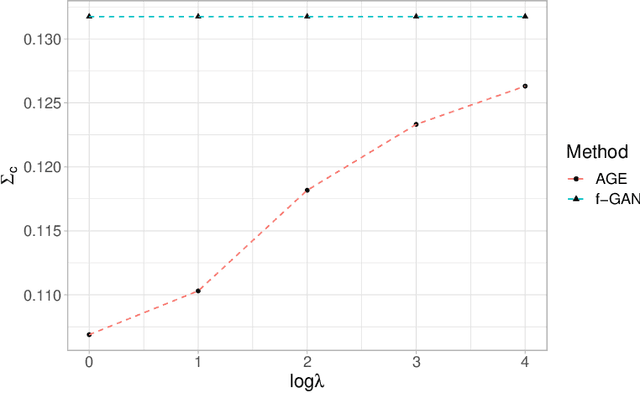
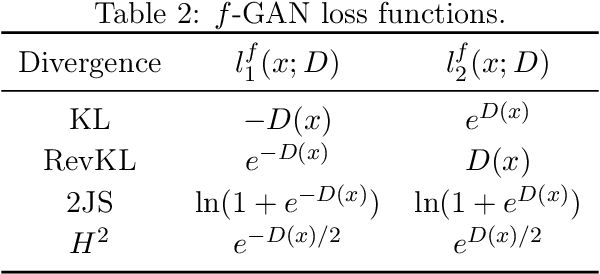
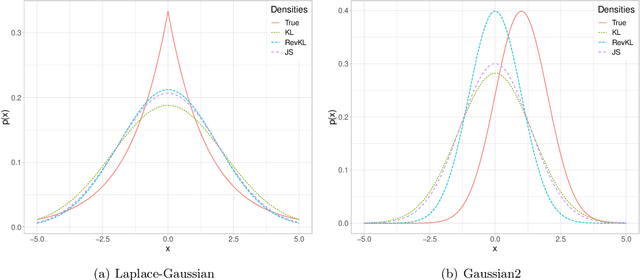
Generative Adversarial Networks (GANs) have achieved great success in data generation. However, its statistical properties are not fully understood. In this paper, we consider the statistical behavior of the general $f$-divergence formulation of GAN, which includes the Kullback--Leibler divergence that is closely related to the maximum likelihood principle. We show that for parametric generative models that are correctly specified, all $f$-divergence GANs with the same discriminator classes are asymptotically equivalent under suitable regularity conditions. Moreover, with an appropriately chosen local discriminator, they become equivalent to the maximum likelihood estimate asymptotically. For generative models that are misspecified, GANs with different $f$-divergences {converge to different estimators}, and thus cannot be directly compared. However, it is shown that for some commonly used $f$-divergences, the original $f$-GAN is not optimal in that one can achieve a smaller asymptotic variance when the discriminator training in the original $f$-GAN formulation is replaced by logistic regression. The resulting estimation method is referred to as Adversarial Gradient Estimation (AGE). Empirical studies are provided to support the theory and to demonstrate the advantage of AGE over the original $f$-GANs under model misspecification.
IDEA: Interpretable Dynamic Ensemble Architecture for Time Series Prediction
Jan 14, 2022
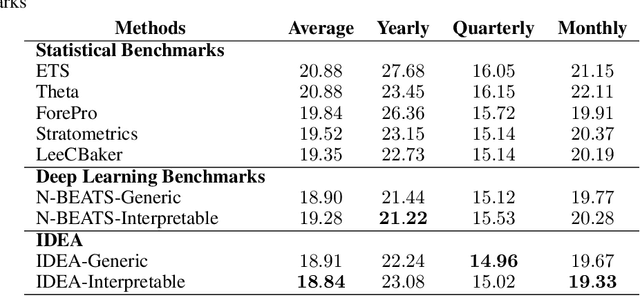
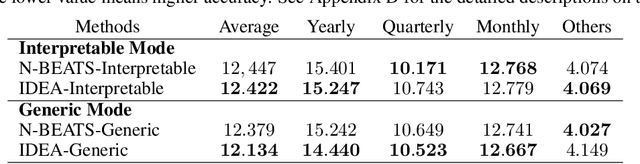
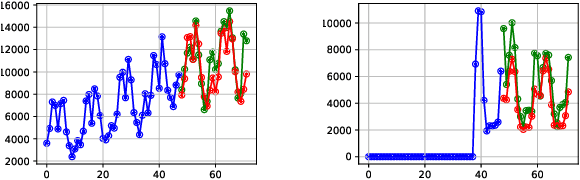
We enhance the accuracy and generalization of univariate time series point prediction by an explainable ensemble on the fly. We propose an Interpretable Dynamic Ensemble Architecture (IDEA), in which interpretable base learners give predictions independently with sparse communication as a group. The model is composed of several sequentially stacked groups connected by group backcast residuals and recurrent input competition. Ensemble driven by end-to-end training both horizontally and vertically brings state-of-the-art (SOTA) performances. Forecast accuracy improves by 2.6% over the best statistical benchmark on the TOURISM dataset and 2% over the best deep learning benchmark on the M4 dataset. The architecture enjoys several advantages, being applicable to time series from various domains, explainable to users with specialized modular structure and robust to changes in task distribution.
Bidirectional Generative Modeling Using Adversarial Gradient Estimation
Feb 21, 2020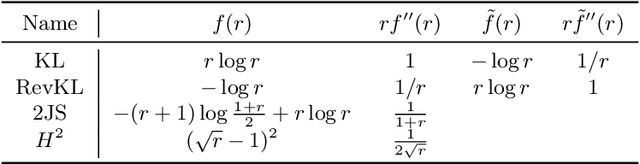
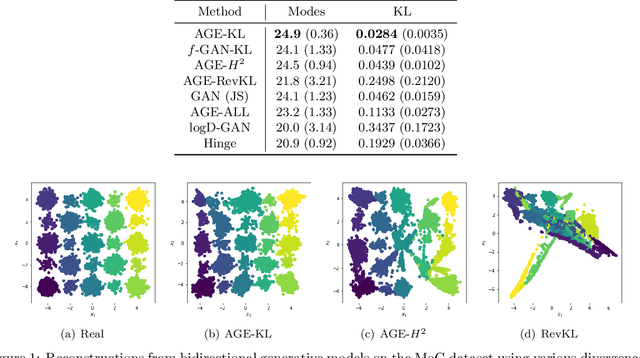


This paper considers the general $f$-divergence formulation of bidirectional generative modeling, which includes VAE and BiGAN as special cases. We present a new optimization method for this formulation, where the gradient is computed using an adversarially learned discriminator. In our framework, we show that different divergences induce similar algorithms in terms of gradient evaluation, except with different scaling. Therefore this paper gives a general recipe for a class of principled $f$-divergence based generative modeling methods. Theoretical justifications and extensive empirical studies are provided to demonstrate the advantage of our approach over existing methods.
A General Pairwise Comparison Model for Extremely Sparse Networks
Feb 20, 2020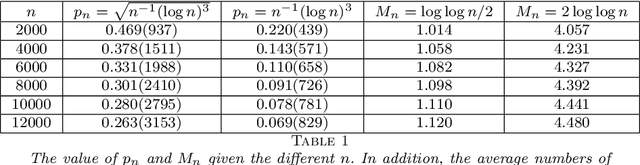
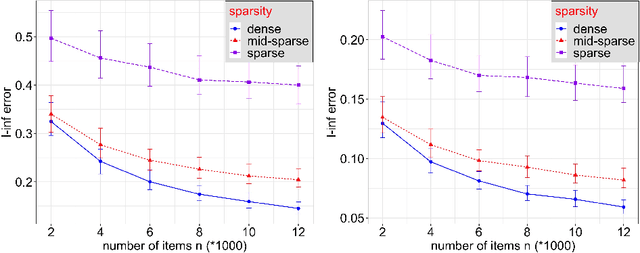
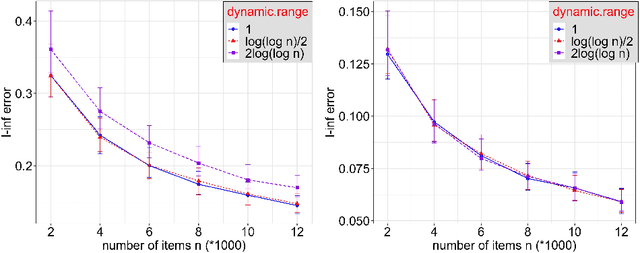
Statistical inference using pairwise comparison data has been an effective approach to analyzing complex and sparse networks. In this paper we propose a general framework for modeling the mutual interaction in a probabilistic network, which enjoys ample flexibility in terms of parametrization. Within this set-up, we establish that the maximum likelihood estimator (MLE) for the latent scores of the subjects is uniformly consistent under a near-minimal condition on network sparsity. This condition is sharp in terms of the leading order asymptotics describing the sparsity. The proof utilizes a novel chaining technique based on the error-induced metric as well as careful counting of comparison graph structures. Our results guarantee that the MLE is a valid estimator for inference in large-scale comparison networks where data is asymptotically deficient. Numerical simulations are provided to complement the theoretical analysis.