 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisper-MCE: Whisper Model Finetuned for Better Performance with Mixed Languages
Oct 27, 2023
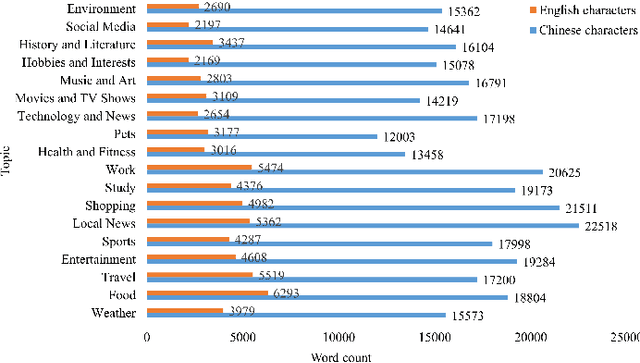
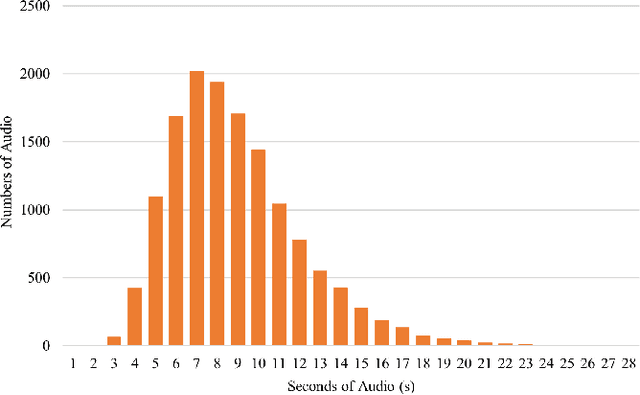

Recently Whisper has approached human-level robustness and accuracy in English automatic speech recognition (ASR), while in minor language and mixed language speech recognition, there remains a compelling need for further improvement. In this work, we present the impressive results of Whisper-MCE, our finetuned Whisper model, which was trained using our self-collected dataset, Mixed Cantonese and English audio dataset (MCE). Meanwhile, considering word error rate (WER) poses challenges when it comes to evaluating its effectiveness in minor language and mixed-language contexts, we present a novel rating mechanism. By comparing our model to the baseline whisper-large-v2 model, we demonstrate its superior ability to accurately capture the content of the original audio, achieve higher recognition accuracy, and exhibit faster recognition speed. Notably, our model outperforms other existing models in the specific task of recognizing mixed language.