 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning under Commission and Omission Event Outliers
Jan 23, 2025

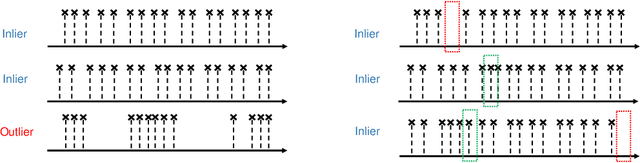
Event stream is an important data format in real life. The events are usually expected to follow some regular patterns over time. However, the patterns could be contaminated by unexpected absences or occurrences of events. In this paper, we adopt the temporal point process framework for learning event stream and we provide a simple-but-effective method to deal with both commission and omission event outliers.In particular, we introduce a novel weight function to dynamically adjust the importance of each observed event so that the final estimator could offer multiple statistical merits. We compare the proposed method with the vanilla one in the classification problems, where event streams can be clustered into different groups. Both theoretical and numerical results confirm the effectiveness of our new approach. To our knowledge, our method is the first one to provably handle both commission and omission outliers simultaneously.
Deep non-parametric logistic model with case-control data and external summary information
Sep 03, 2024The case-control sampling design serves as a pivotal strategy in mitigating the imbalanced structure observed in binary data. We consider the estimation of a non-parametric logistic model with the case-control data supplemented by external summary information. The incorporation of external summary information ensures the identifiability of the model. We propose a two-step estimation procedure. In the first step, the external information is utilized to estimate the marginal case proportion. In the second step, the estimated proportion is used to construct a weighted objective function for parameter training. A deep neural network architecture is employed for functional approximation. We further derive the non-asymptotic error bound of the proposed estimator. Following this the convergence rate is obtained and is shown to reach the optimal speed of the non-parametric regression estimation. Simulation studies are conducted to evaluate the theoretical findings of the proposed method. A real data example is analyzed for illustration.
On Non-asymptotic Theory of Recurrent Neural Networks in Temporal Point Processes
Jun 02, 2024Temporal point process (TPP) is an important tool for modeling and predicting irregularly timed events across various domains. Recently, the recurrent neural network (RNN)-based TPPs have shown practical advantages over traditional parametric TPP models. However, in the current literature, it remains nascent in understanding neural TPPs from theoretical viewpoints. In this paper, we establish the excess risk bounds of RNN-TPPs under many well-known TPP settings. We especially show that an RNN-TPP with no more than four layers can achieve vanishing generalization errors. Our technical contributions include the characterization of the complexity of the multi-layer RNN class, the construction of $\tanh$ neural networks for approximating dynamic event intensity functions, and the truncation technique for alleviating the issue of unbounded event sequences. Our results bridge the gap between TPP's application and neural network theory.
Statistical inference for case-control logistic regression via integrating external summary data
May 31, 2024Case-control sampling is a commonly used retrospective sampling design to alleviate imbalanced structure of binary data. When fitting the logistic regression model with case-control data, although the slope parameter of the model can be consistently estimated, the intercept parameter is not identifiable, and the marginal case proportion is not estimatable, either. We consider the situations in which besides the case-control data from the main study, called internal study, there also exists summary-level information from related external studies. An empirical likelihood based approach is proposed to make inference for the logistic model by incorporating the internal case-control data and external information. We show that the intercept parameter is identifiable with the help of external information, and then all the regression parameters as well as the marginal case proportion can be estimated consistently. The proposed method also accounts for the possible variability in external studies. The resultant estimators are shown to be asymptotically normally distributed. The asymptotic variance-covariance matrix can be consistently estimated by the case-control data. The optimal way to utilized external information is discussed. Simulation studies are conducted to verify the theoretical findings. A real data set is analyzed for illustration.
Efficient semi-supervised inference for logistic regression under case-control studies
Feb 23, 2024



Semi-supervised learning has received increasingly attention in statistics and machine learning. In semi-supervised learning settings, a labeled data set with both outcomes and covariates and an unlabeled data set with covariates only are collected. We consider an inference problem in semi-supervised settings where the outcome in the labeled data is binary and the labeled data is collected by case-control sampling. Case-control sampling is an effective sampling scheme for alleviating imbalance structure in binary data. Under the logistic model assumption, case-control data can still provide consistent estimator for the slope parameter of the regression model. However, the intercept parameter is not identifiable. Consequently, the marginal case proportion cannot be estimated from case-control data. We find out that with the availability of the unlabeled data, the intercept parameter can be identified in semi-supervised learning setting. We construct the likelihood function of the observed labeled and unlabeled data and obtain the maximum likelihood estimator via an iterative algorithm. The proposed estimator is shown to be consistent, asymptotically normal, and semiparametrically efficient. Extensive simulation studies are conducted to show the finite sample performance of the proposed method. The results imply that the unlabeled data not only helps to identify the intercept but also improves the estimation efficiency of the slope parameter. Meanwhile, the marginal case proportion can be estimated accurately by the proposed method.
Neural Frailty Machine: Beyond proportional hazard assumption in neural survival regressions
Mar 18, 2023We present neural frailty machine (NFM), a powerful and flexible neural modeling framework for survival regressions. The NFM framework utilizes the classical idea of multiplicative frailty in survival analysis to capture unobserved heterogeneity among individuals, at the same time being able to leverage the strong approximation power of neural architectures for handling nonlinear covariate dependence. Two concrete models are derived under the framework that extends neural proportional hazard models and nonparametric hazard regression models. Both models allow efficient training under the likelihood objective. Theoretically, for both proposed models, we establish statistical guarantees of neural function approximation with respect to nonparametric components via characterizing their rate of convergence. Empirically, we provide synthetic experiments that verify our theoretical statements. We also conduct experimental evaluations over $6$ benchmark datasets of different scales, showing that the proposed NFM models outperform state-of-the-art survival models in terms of predictive performance. Our code is publicly availabel at https://github.com/Rorschach1989/nfm
Morphological feature visualization of Alzheimer's disease via Multidirectional Perception GAN
Nov 25, 2021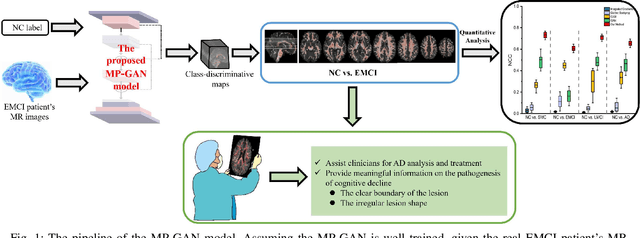
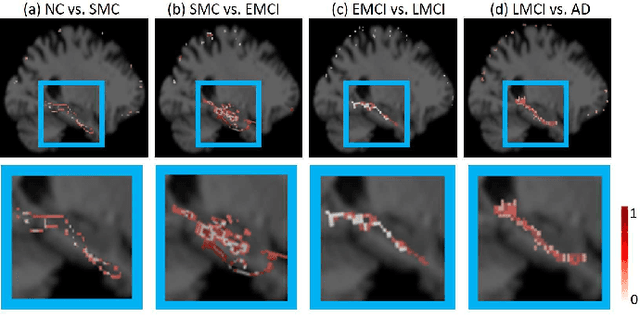
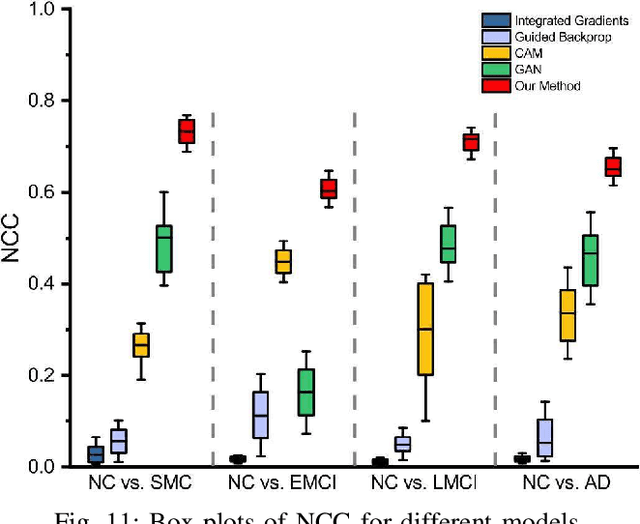
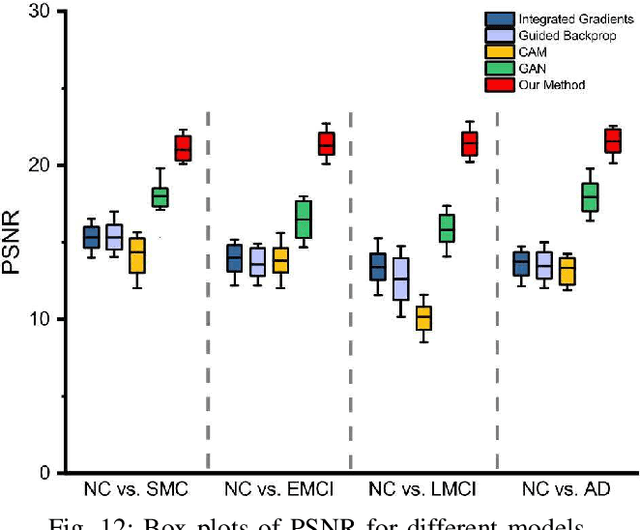
The diagnosis of early stages of Alzheimer's disease (AD) is essential for timely treatment to slow further deterioration. Visualizing the morphological features for the early stages of AD is of great clinical value. In this work, a novel Multidirectional Perception Generative Adversarial Network (MP-GAN) is proposed to visualize the morphological features indicating the severity of AD for patients of different stages. Specifically, by introducing a novel multidirectional mapping mechanism into the model, the proposed MP-GAN can capture the salient global features efficiently. Thus, by utilizing the class-discriminative map from the generator, the proposed model can clearly delineate the subtle lesions via MR image transformations between the source domain and the pre-defined target domain. Besides, by integrating the adversarial loss, classification loss, cycle consistency loss and \emph{L}1 penalty, a single generator in MP-GAN can learn the class-discriminative maps for multiple-classes. Extensive experimental results on Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate that MP-GAN achieves superior performance compared with the existing methods. The lesions visualized by MP-GAN are also consistent with what clinicians observe.
Brain Stroke Lesion Segmentation Using Consistent Perception Generative Adversarial Network
Aug 30, 2020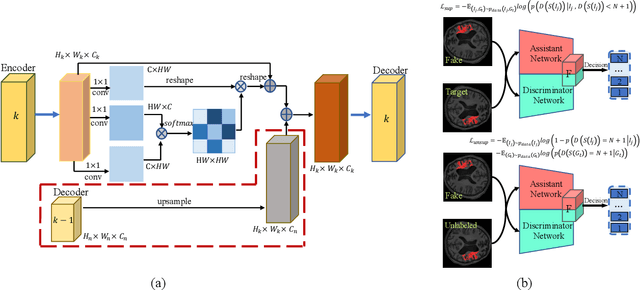
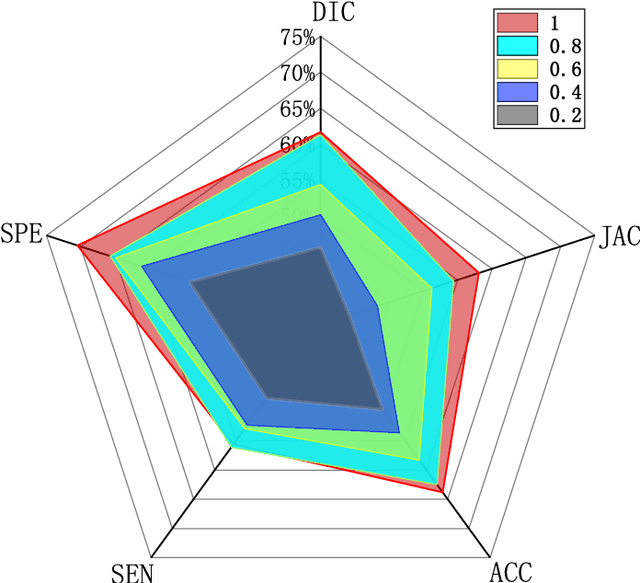

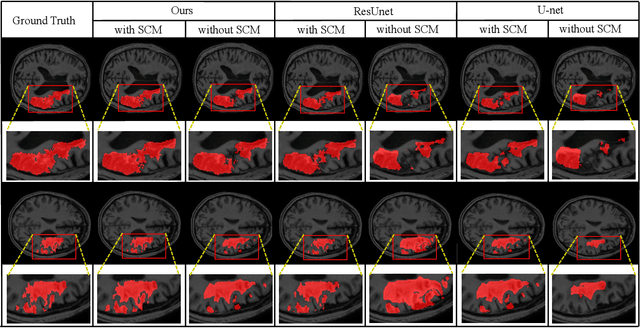
Recently, the state-of-the-art deep learning methods have demonstrated impressive performance in segmentation tasks. However, the success of these methods depends on a large amount of manually labeled masks, which are expensive and time-consuming to be collected. To reduce the dependence on full labeled samples, we propose a novel Consistent Perception Generative Adversarial Network (CPGAN) for semi-supervised stroke lesion segmentation. Specifically, we design a non-local operation named similarity connection module (SCM) to capture the information of multi-scale features. This module can selectively aggregate the features at each position by a weighted sum. Furthermore, an assistant network is constructed to encourage the discriminator to learn meaningful feature representations which are forgotten during training. The assistant network and the discriminator are used to jointly decide whether the segmentation results are real or fake. With the semi-supervised stroke lesion segmentation, we adopt a consistent perception strategy to enhance the effect of brain stroke lesion prediction for the unlabeled data. The CPGAN was evaluated on the Anatomical Tracings of Lesions After Stroke (ATLAS). The experimental results demonstrate that the proposed network achieves superior segmentation performance. In semi-supervised segmentation task, our method using only two-fifths of labeled samples outperforms some approaches using full labeled samples.
Tensorizing GAN with High-Order Pooling for Alzheimer's Disease Assessment
Aug 03, 2020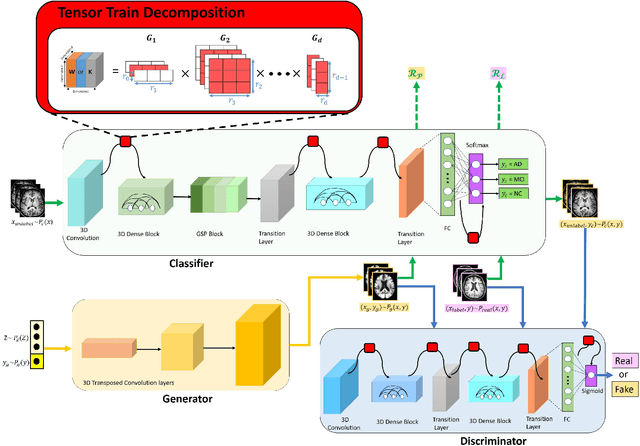
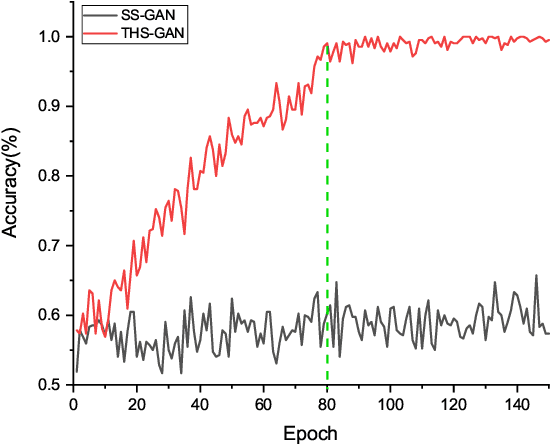

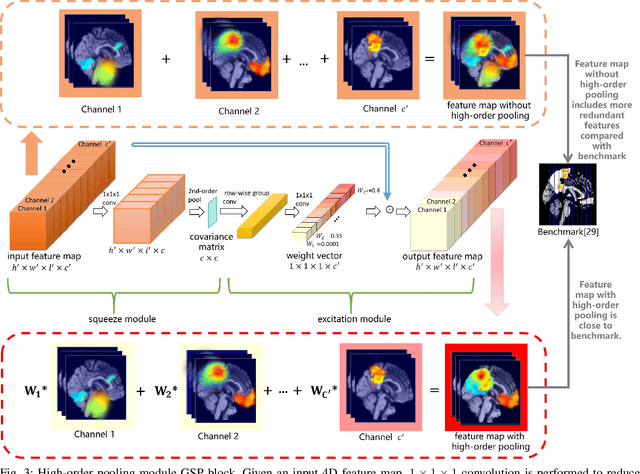
It is of great significance to apply deep learning for the early diagnosis of Alzheimer's Disease (AD). In this work, a novel tensorizing GAN with high-order pooling is proposed to assess Mild Cognitive Impairment (MCI) and AD. By tensorizing a three-player cooperative game based framework, the proposed model can benefit from the structural information of the brain. By incorporating the high-order pooling scheme into the classifier, the proposed model can make full use of the second-order statistics of the holistic Magnetic Resonance Imaging (MRI) images. To the best of our knowledge, the proposed Tensor-train, High-pooling and Semi-supervised learning based GAN (THS-GAN) is the first work to deal with classification on MRI images for AD diagnosis. Extensive experimental results on Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset are reported to demonstrate that the proposed THS-GAN achieves superior performance compared with existing methods, and to show that both tensor-train and high-order pooling can enhance classification performance. The visualization of generated samples also shows that the proposed model can generate plausible samples for semi-supervised learning purpose.
Conditional probability calculation using restricted Boltzmann machine with application to system identification
Jun 07, 2018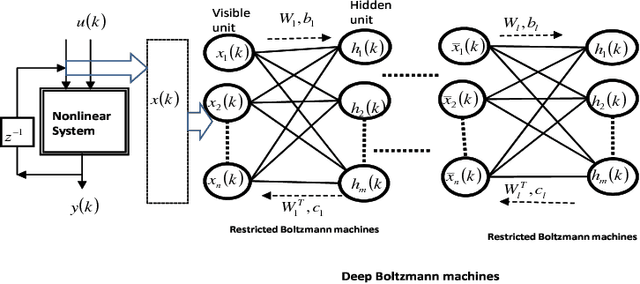
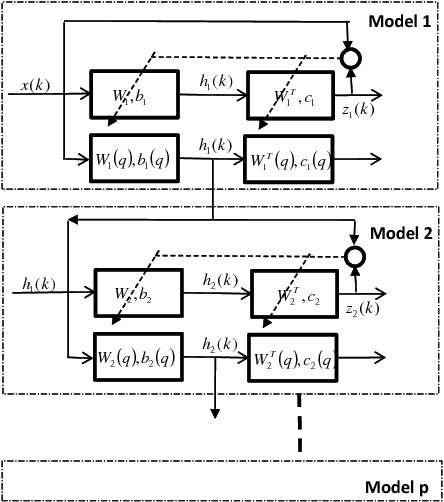
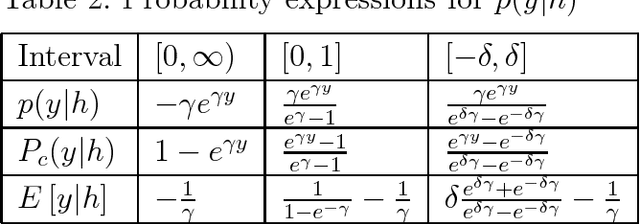
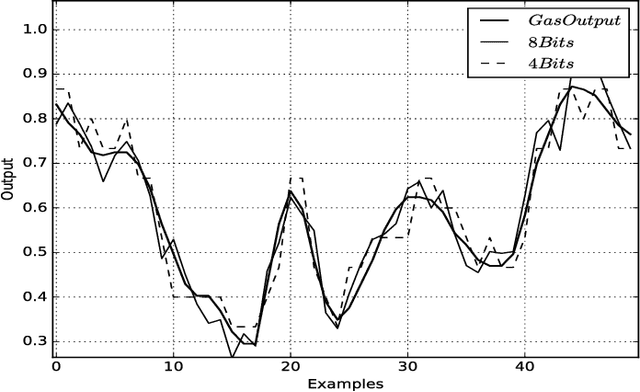
There are many advantages to use probability method for nonlinear system identification, such as the noises and outliers in the data set do not affect the probability models significantly; the input features can be extracted in probability forms. The biggest obstacle of the probability model is the probability distributions are not easy to be obtained. In this paper, we form the nonlinear system identification into solving the conditional probability. Then we modify the restricted Boltzmann machine (RBM), such that the joint probability, input distribution, and the conditional probability can be calculated by the RBM training. Binary encoding and continue valued methods are discussed. The universal approximation analysis for the conditional probability based modelling is proposed. We use two benchmark nonlinear systems to compare our probability modelling method with the other black-box modeling methods. The results show that this novel method is much better when there are big noises and the system dynamics are complex.