 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmoView: Harmonizing Multi-View Constraints for Identity-Consistent Video Generation
Jun 09, 2026Current identity-consistent video generation methods struggle to preserve appearance fidelity under large viewpoint changes. While introducing multi-view reference input offers a natural solution, progress remains constrained by the lack of effective frameworks for multi-view inputs and the scarcity of multi-view data. We address these challenges by proposing HarmoView, a robust framework for identity-consistent video generation that effectively integrates multi-view cues through three architectural refinements complemented by a staged training curriculum. Specifically, we first introduce Multi-level Feature Injection to anchor identity fidelity; by injecting raw ViT features from frontal references alongside text tokens via cross-attention, MFI provides persistent low-level appearance anchors that complement the high-level identity features within DiT blocks, leading to enhanced identity preservation. Then, we employ learnable proxy tokens to unify heterogeneous reference layouts across single-/multi-view settings while simultaneously resolving the reference-view mismatch problem. Jump-RoPE is further developed for identity-wise feature isolation to reduce identity crosstalk. To activate these structural capabilities while preserving the original generative priors, we propose the Progressive View Curriculum. This four-stage training strategy employs view dropout to facilitate a stable transition from vanilla T2V generation to high-fidelity, identity-persistent spatial reasoning. Furthermore, we construct a large-scale multi-view dataset to address the issue of data scarcity. Extensive evaluation on our multi-view benchmark, comprising 100 manually-curated cases spanning 52 unique identities, demonstrates that HarmoView significantly outperforms open-source baselines and matches leading closed-source engines, achieving state-of-the-art performance in identity-consistent video generation.
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Jun 10, 2025To address key limitations in human-object interaction (HOI) video generation -- specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility -- we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Concept Complement Bottleneck Model for Interpretable Medical Image Diagnosis
Oct 20, 2024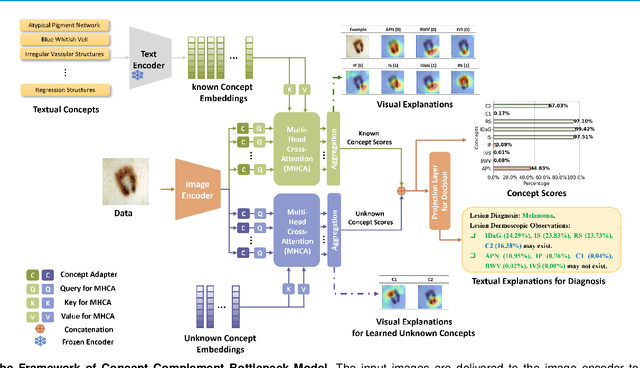
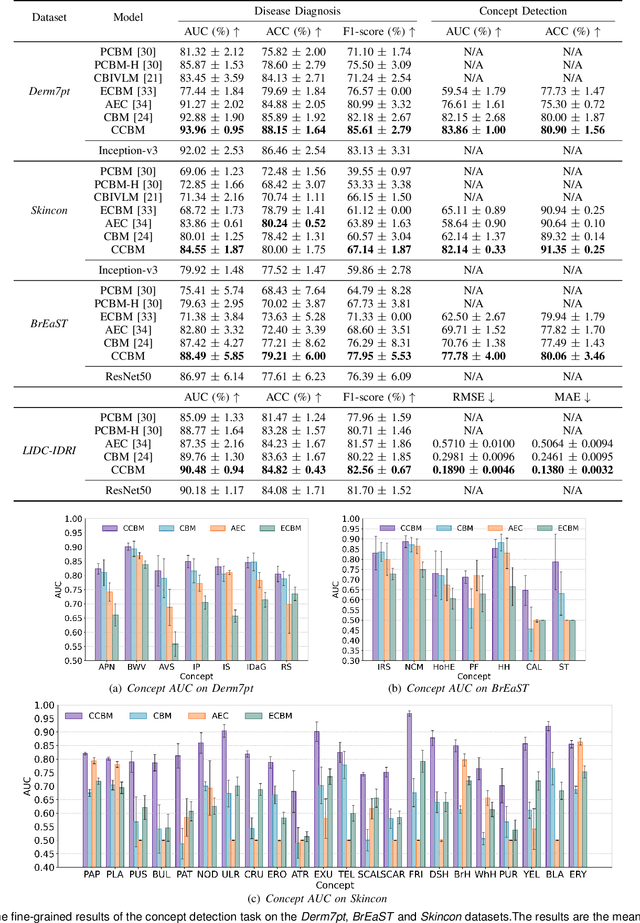
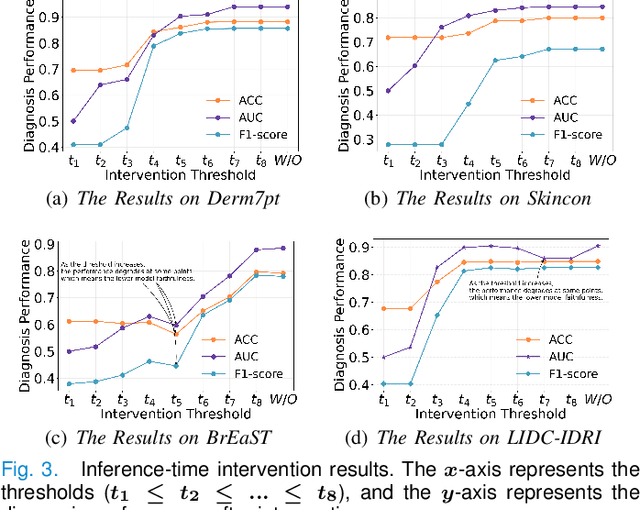
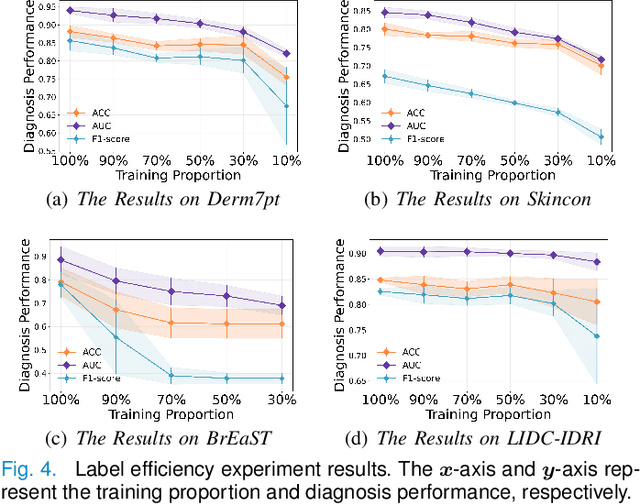
Models based on human-understandable concepts have received extensive attention to improve model interpretability for trustworthy artificial intelligence in the field of medical image analysis. These methods can provide convincing explanations for model decisions but heavily rely on the detailed annotation of pre-defined concepts. Consequently, they may not be effective in cases where concepts or annotations are incomplete or low-quality. Although some methods automatically discover effective and new visual concepts rather than using pre-defined concepts or could find some human-understandable concepts via large Language models, they are prone to veering away from medical diagnostic evidence and are challenging to understand. In this paper, we propose a concept complement bottleneck model for interpretable medical image diagnosis with the aim of complementing the existing concept set and finding new concepts bridging the gap between explainable models. Specifically, we propose to use concept adapters for specific concepts to mine the concept differences and score concepts in their own attention channels to support almost fairly concept learning. Then, we devise a concept complement strategy to learn new concepts while jointly using known concepts to improve model performance. Comprehensive experiments on medical datasets demonstrate that our model outperforms the state-of-the-art competitors in concept detection and disease diagnosis tasks while providing diverse explanations to ensure model interpretability effectively.
Self-eXplainable AI for Medical Image Analysis: A Survey and New Outlooks
Oct 03, 2024



The increasing demand for transparent and reliable models, particularly in high-stakes decision-making areas such as medical image analysis, has led to the emergence of eXplainable Artificial Intelligence (XAI). Post-hoc XAI techniques, which aim to explain black-box models after training, have been controversial in recent works concerning their fidelity to the models' predictions. In contrast, Self-eXplainable AI (S-XAI) offers a compelling alternative by incorporating explainability directly into the training process of deep learning models. This approach allows models to generate inherent explanations that are closely aligned with their internal decision-making processes. Such enhanced transparency significantly supports the trustworthiness, robustness, and accountability of AI systems in real-world medical applications. To facilitate the development of S-XAI methods for medical image analysis, this survey presents an comprehensive review across various image modalities and clinical applications. It covers more than 200 papers from three key perspectives: 1) input explainability through the integration of explainable feature engineering and knowledge graph, 2) model explainability via attention-based learning, concept-based learning, and prototype-based learning, and 3) output explainability by providing counterfactual explanation and textual explanation. Additionally, this paper outlines the desired characteristics of explainability and existing evaluation methods for assessing explanation quality. Finally, it discusses the major challenges and future research directions in developing S-XAI for medical image analysis.
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
MedDr: Diagnosis-Guided Bootstrapping for Large-Scale Medical Vision-Language Learning
Apr 23, 2024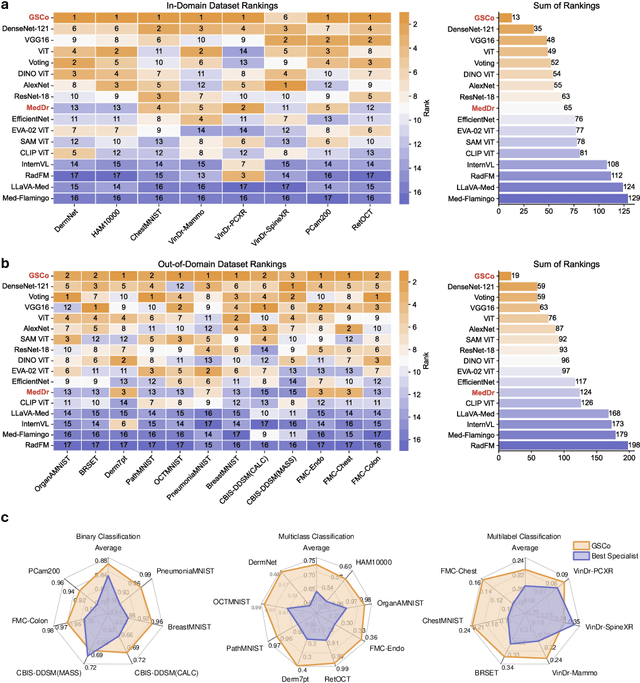

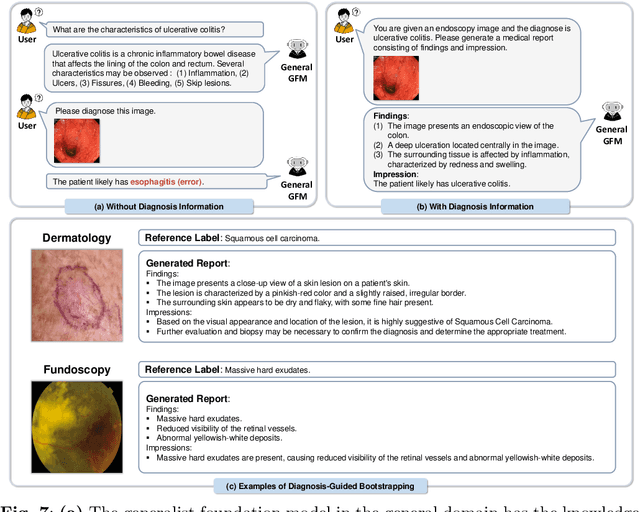
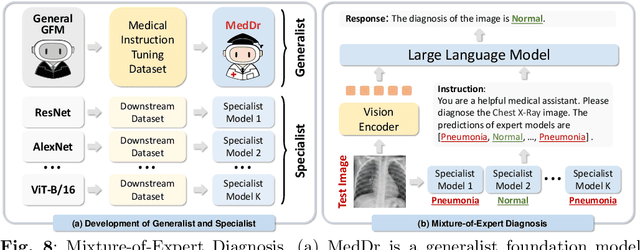
The rapid advancement of large-scale vision-language models has showcased remarkable capabilities across various tasks. However, the lack of extensive and high-quality image-text data in medicine has greatly hindered the development of large-scale medical vision-language models. In this work, we present a diagnosis-guided bootstrapping strategy that exploits both image and label information to construct vision-language datasets. Based on the constructed dataset, we developed MedDr, a generalist foundation model for healthcare capable of handling diverse medical data modalities, including radiology, pathology, dermatology, retinography, and endoscopy. Moreover, during inference, we propose a simple but effective retrieval-augmented medical diagnosis strategy, which enhances the model's generalization ability. Extensive experiments on visual question answering, medical report generation, and medical image diagnosis demonstrate the superiority of our method.
Chatbots to ChatGPT in a Cybersecurity Space: Evolution, Vulnerabilities, Attacks, Challenges, and Future Recommendations
May 29, 2023



Chatbots shifted from rule-based to artificial intelligence techniques and gained traction in medicine, shopping, customer services, food delivery, education, and research. OpenAI developed ChatGPT blizzard on the Internet as it crossed one million users within five days of its launch. However, with the enhanced popularity, chatbots experienced cybersecurity threats and vulnerabilities. This paper discussed the relevant literature, reports, and explanatory incident attacks generated against chatbots. Our initial point is to explore the timeline of chatbots from ELIZA (an early natural language processing computer program) to GPT-4 and provide the working mechanism of ChatGPT. Subsequently, we explored the cybersecurity attacks and vulnerabilities in chatbots. Besides, we investigated the ChatGPT, specifically in the context of creating the malware code, phishing emails, undetectable zero-day attacks, and generation of macros and LOLBINs. Furthermore, the history of cyberattacks and vulnerabilities exploited by cybercriminals are discussed, particularly considering the risk and vulnerabilities in ChatGPT. Addressing these threats and vulnerabilities requires specific strategies and measures to reduce the harmful consequences. Therefore, the future directions to address the challenges were presented.
Deep Learning for Signal Demodulation in Physical Layer Wireless Communications: Prototype Platform, Open Dataset, and Analytics
Mar 08, 2019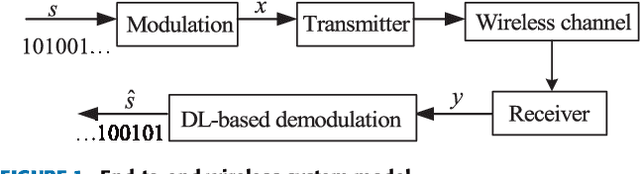

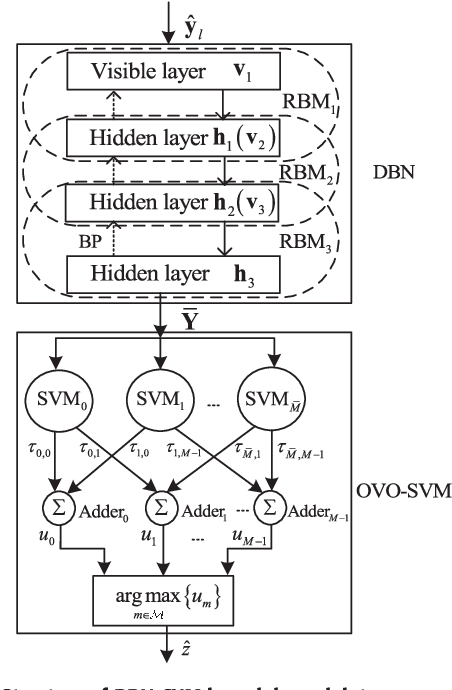
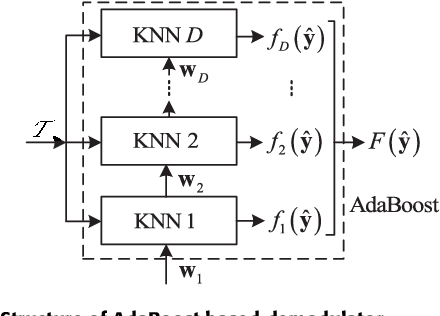
In this paper, we investigate deep learning (DL)-enabled signal demodulation methods and establish the first open dataset of real modulated signals for wireless communication systems. Specifically, we propose a flexible communication prototype platform for measuring real modulation dataset. Then, based on the measured dataset, two DL-based demodulators, called deep belief network (DBN)-support vector machine (SVM) demodulator and adaptive boosting (AdaBoost) based demodulator, are proposed. The proposed DBN-SVM based demodulator exploits the advantages of both DBN and SVM, i.e., the advantage of DBN as a feature extractor and SVM as a feature classifier. In DBN-SVM based demodulator, the received signals are normalized before being fed to the DBN network. Furthermore, an AdaBoost based demodulator is developed, which employs the $k$-Nearest Neighbor (KNN) as a weak classifier to form a strong combined classifier. Finally, experimental results indicate that the proposed DBN-SVM based demodulator and AdaBoost based demodulator are superior to the single classification method using DBN, SVM, and maximum likelihood (MLD) based demodulator.