 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
Learning Multimodal Volumetric Features for Large-Scale Neuron Tracing
Jan 05, 2024


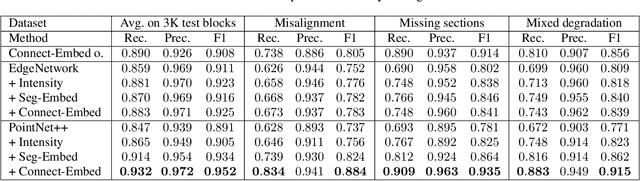
The current neuron reconstruction pipeline for electron microscopy (EM) data usually includes automatic image segmentation followed by extensive human expert proofreading. In this work, we aim to reduce human workload by predicting connectivity between over-segmented neuron pieces, taking both microscopy image and 3D morphology features into account, similar to human proofreading workflow. To this end, we first construct a dataset, named FlyTracing, that contains millions of pairwise connections of segments expanding the whole fly brain, which is three orders of magnitude larger than existing datasets for neuron segment connection. To learn sophisticated biological imaging features from the connectivity annotations, we propose a novel connectivity-aware contrastive learning method to generate dense volumetric EM image embedding. The learned embeddings can be easily incorporated with any point or voxel-based morphological representations for automatic neuron tracing. Extensive comparisons of different combination schemes of image and morphological representation in identifying split errors across the whole fly brain demonstrate the superiority of the proposed approach, especially for the locations that contain severe imaging artifacts, such as section missing and misalignment. The dataset and code are available at https://github.com/Levishery/Flywire-Neuron-Tracing.
View Adaptive Light Field Deblurring Networks with Depth Perception
Mar 13, 2023



The Light Field (LF) deblurring task is a challenging problem as the blur images are caused by different reasons like the camera shake and the object motion. The single image deblurring method is a possible way to solve this problem. However, since it deals with each view independently and cannot effectively utilize and maintain the LF structure, the restoration effect is usually not ideal. Besides, the LF blur is more complex because the degree is affected by the views and depth. Therefore, we carefully designed a novel LF deblurring network based on the LF blur characteristics. On one hand, since the blur degree varies a lot in different views, we design a novel view adaptive spatial convolution to deblur blurred LFs, which calculates the exclusive convolution kernel for each view. On the other hand, because the blur degree also varies with the depth of the object, a depth perception view attention is designed to deblur different depth areas by selectively integrating information from different views. Besides, we introduce an angular position embedding to maintain the LF structure better, which ensures the model correctly restores the view information. Quantitative and qualitative experimental results on synthetic and real images show that the deblurring effect of our method is better than other state-of-the-art methods.
Neural Message Passing for Objective-Based Uncertainty Quantification and Optimal Experimental Design
Mar 14, 2022



Real-world scientific or engineering applications often involve mathematical modeling of complex uncertain systems with a large number of unknown parameters. The complexity of such systems, and the enormous uncertainties therein, typically make accurate model identification from the available data infeasible. In such cases, it is desirable to represent the model uncertainty in a Bayesian paradigm, based on which we can design robust operators that maintain the best overall performance across all possible models and design optimal experiments that can effectively reduce uncertainty to maximally enhance the performance of such operators. While objective-based uncertainty quantification (objective-UQ) based on MOCU (mean objective cost of uncertainty) has been shown to provide effective means for quantifying and handling uncertainty in complex systems, a major drawback has been the high computational cost of estimating MOCU. In this work, we demonstrate for the first time that one can design accurate surrogate models for efficient objective-UQ via MOCU based on a data-driven approach. We adopt a neural message passing model for surrogate modeling, which incorporates a novel axiomatic constraint loss that penalizes an increase in the estimated system uncertainty. As an illustrative example, we consider the optimal experimental design (OED) problem for uncertain Kuramoto models, where the goal is to predict the experiments that can most effectively enhance the robust synchronization performance through uncertainty reduction. Through quantitative performance assessment, we show that our proposed approach can accelerate MOCU-based OED by four to five orders of magnitude, virtually without any visible loss of performance compared to the previous state-of-the-art. The proposed approach can be applied to general OED tasks, beyond the Kuramoto model.