 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCapsBench: A Large-scale Fine-grained Benchmark for Video Caption Quality Evaluation
May 29, 2025Video captions play a crucial role in text-to-video generation tasks, as their quality directly influences the semantic coherence and visual fidelity of the generated videos. Although large vision-language models (VLMs) have demonstrated significant potential in caption generation, existing benchmarks inadequately address fine-grained evaluation, particularly in capturing spatial-temporal details critical for video generation. To address this gap, we introduce the Fine-grained Video Caption Evaluation Benchmark (VCapsBench), the first large-scale fine-grained benchmark comprising 5,677 (5K+) videos and 109,796 (100K+) question-answer pairs. These QA-pairs are systematically annotated across 21 fine-grained dimensions (e.g., camera movement, and shot type) that are empirically proven critical for text-to-video generation. We further introduce three metrics (Accuracy (AR), Inconsistency Rate (IR), Coverage Rate (CR)), and an automated evaluation pipeline leveraging large language model (LLM) to verify caption quality via contrastive QA-pairs analysis. By providing actionable insights for caption optimization, our benchmark can advance the development of robust text-to-video models. The dataset and codes are available at website: https://github.com/GXYM/VCapsBench.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
Video-Language Alignment Pre-training via Spatio-Temporal Graph Transformer
Jul 16, 2024



Video-language alignment is a crucial multi-modal task that benefits various downstream applications, e.g., video-text retrieval and video question answering. Existing methods either utilize multi-modal information in video-text pairs or apply global and local alignment techniques to promote alignment precision. However, these methods often fail to fully explore the spatio-temporal relationships among vision tokens within video and across different video-text pairs. In this paper, we propose a novel Spatio-Temporal Graph Transformer module to uniformly learn spatial and temporal contexts for video-language alignment pre-training (dubbed STGT). Specifically, our STGT combines spatio-temporal graph structure information with attention in transformer block, effectively utilizing the spatio-temporal contexts. In this way, we can model the relationships between vision tokens, promoting video-text alignment precision for benefiting downstream tasks. In addition, we propose a self-similarity alignment loss to explore the inherent self-similarity in the video and text. With the initial optimization achieved by contrastive learning, it can further promote the alignment accuracy between video and text. Experimental results on challenging downstream tasks, including video-text retrieval and video question answering, verify the superior performance of our method.
Follow-Your-Pose v2: Multiple-Condition Guided Character Image Animation for Stable Pose Control
Jun 05, 2024



Pose-controllable character video generation is in high demand with extensive applications for fields such as automatic advertising and content creation on social media platforms. While existing character image animation methods using pose sequences and reference images have shown promising performance, they tend to struggle with incoherent animation in complex scenarios, such as multiple character animation and body occlusion. Additionally, current methods request large-scale high-quality videos with stable backgrounds and temporal consistency as training datasets, otherwise, their performance will greatly deteriorate. These two issues hinder the practical utilization of character image animation tools. In this paper, we propose a practical and robust framework Follow-Your-Pose v2, which can be trained on noisy open-sourced videos readily available on the internet. Multi-condition guiders are designed to address the challenges of background stability, body occlusion in multi-character generation, and consistency of character appearance. Moreover, to fill the gap of fair evaluation of multi-character pose animation, we propose a new benchmark comprising approximately 4,000 frames. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a margin of over 35\% across 2 datasets and on 7 metrics. Meanwhile, qualitative assessments reveal a significant improvement in the quality of generated video, particularly in scenarios involving complex backgrounds and body occlusion of multi-character, suggesting the superiority of our approach.
Follow-Your-Emoji: Fine-Controllable and Expressive Freestyle Portrait Animation
Jun 04, 2024



We present Follow-Your-Emoji, a diffusion-based framework for portrait animation, which animates a reference portrait with target landmark sequences. The main challenge of portrait animation is to preserve the identity of the reference portrait and transfer the target expression to this portrait while maintaining temporal consistency and fidelity. To address these challenges, Follow-Your-Emoji equipped the powerful Stable Diffusion model with two well-designed technologies. Specifically, we first adopt a new explicit motion signal, namely expression-aware landmark, to guide the animation process. We discover this landmark can not only ensure the accurate motion alignment between the reference portrait and target motion during inference but also increase the ability to portray exaggerated expressions (i.e., large pupil movements) and avoid identity leakage. Then, we propose a facial fine-grained loss to improve the model's ability of subtle expression perception and reference portrait appearance reconstruction by using both expression and facial masks. Accordingly, our method demonstrates significant performance in controlling the expression of freestyle portraits, including real humans, cartoons, sculptures, and even animals. By leveraging a simple and effective progressive generation strategy, we extend our model to stable long-term animation, thus increasing its potential application value. To address the lack of a benchmark for this field, we introduce EmojiBench, a comprehensive benchmark comprising diverse portrait images, driving videos, and landmarks. We show extensive evaluations on EmojiBench to verify the superiority of Follow-Your-Emoji.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024



Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
Inverse-like Antagonistic Scene Text Spotting via Reading-Order Estimation and Dynamic Sampling
Jan 08, 2024Scene text spotting is a challenging task, especially for inverse-like scene text, which has complex layouts, e.g., mirrored, symmetrical, or retro-flexed. In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework dubbed IATS, which can effectively spot inverse-like scene texts without sacrificing general ones. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). To optimize and train REM, we propose a joint reading-order estimation loss consisting of a classification loss, an orthogonality loss, and a distribution loss. With the help of IBM, we can divide the initial text boundary into two symmetric control points and iteratively refine the new text boundary using a lightweight boundary refinement module (BRM) for adapting to various shapes and scales. To alleviate the incompatibility between text detection and recognition, we propose a dynamic sampling module (DSM) with a thin-plate spline that can dynamically sample appropriate features for recognition in the detected text region. Without extra supervision, the DSM can proactively learn to sample appropriate features for text recognition through the gradient returned by the recognition module. Extensive experiments on both challenging scene text and inverse-like scene text datasets demonstrate that our method achieves superior performance both on irregular and inverse-like text spotting.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023
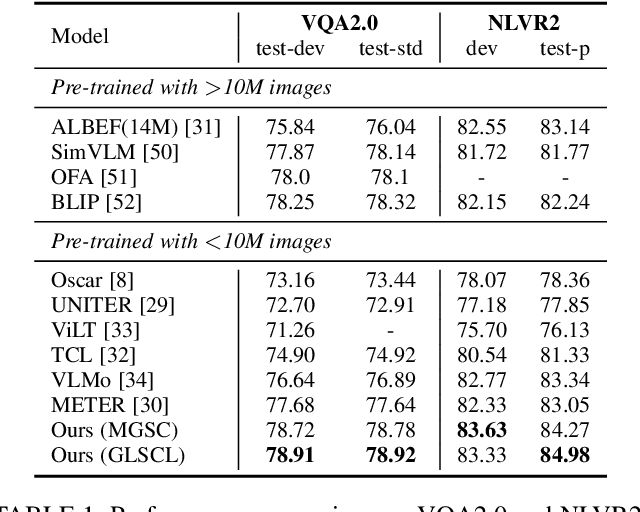
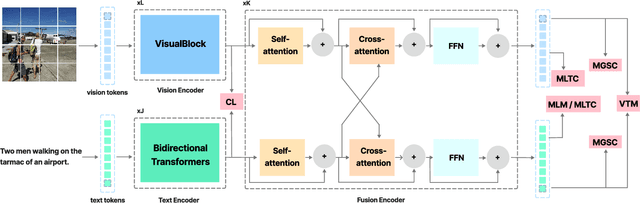
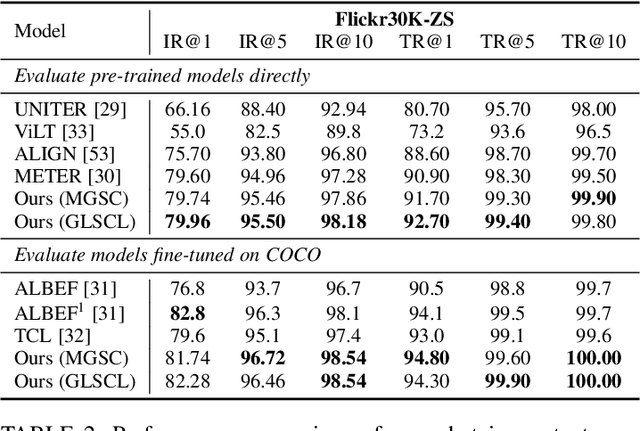
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Img2Vec: A Teacher of High Token-Diversity Helps Masked AutoEncoders
Apr 25, 2023We present a pipeline of Image to Vector (Img2Vec) for masked image modeling (MIM) with deep features. To study which type of deep features is appropriate for MIM as a learning target, we propose a simple MIM framework with serials of well-trained self-supervised models to convert an Image to a feature Vector as the learning target of MIM, where the feature extractor is also known as a teacher model. Surprisingly, we empirically find that an MIM model benefits more from image features generated by some lighter models (e.g., ResNet-50, 26M) than from those by a cumbersome teacher like Transformer-based models (e.g., ViT-Large, 307M). To analyze this remarkable phenomenon, we devise a novel attribute, token diversity, to evaluate the characteristics of generated features from different models. Token diversity measures the feature dissimilarity among different tokens. Through extensive experiments and visualizations, we hypothesize that beyond the acknowledgment that a large model can improve MIM, a high token-diversity of a teacher model is also crucial. Based on the above discussion, Img2Vec adopts a teacher model with high token-diversity to generate image features. Img2Vec pre-trained on ImageNet unlabeled data with ViT-B yields 85.1\% top-1 accuracy on fine-tuning. Moreover, we scale up Img2Vec on larger models, ViT-L and ViT-H, and get $86.7\%$ and $87.5\%$ accuracy respectively. It also achieves state-of-the-art results on other downstream tasks, e.g., 51.8\% mAP on COCO and 50.7\% mIoU on ADE20K. Img2Vec is a simple yet effective framework tailored to deep feature MIM learning, accomplishing superb comprehensive performance on representative vision tasks.