 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal and Local Semantic Completion Learning for Vision-Language Pre-training
Paper and Code

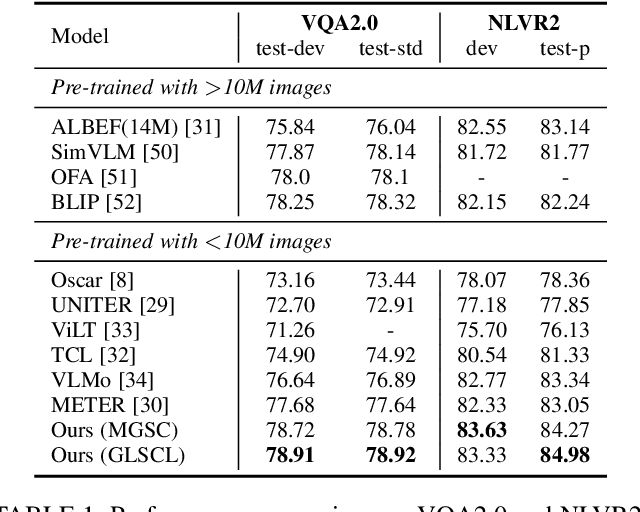
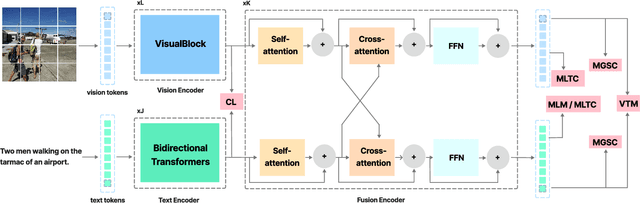
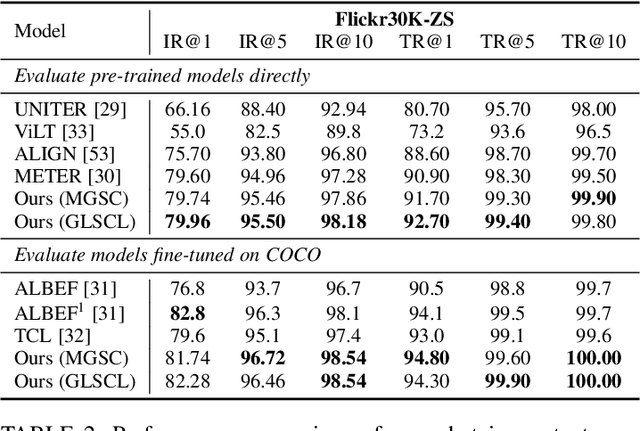
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.