 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
Apr 01, 2026Unified multimodal models provide a natural and promising architecture for understanding diverse and complex real-world knowledge while generating high-quality images. However, they still rely primarily on frozen parametric knowledge, which makes them struggle with real-world image generation involving long-tail and knowledge-intensive concepts. Inspired by the broad success of agents on real-world tasks, we explore agentic modeling to address this limitation. Specifically, we present Unify-Agent, a unified multimodal agent for world-grounded image synthesis, which reframes image generation as an agentic pipeline consisting of prompt understanding, multimodal evidence searching, grounded recaptioning, and final synthesis. To train our model, we construct a tailored multimodal data pipeline and curate 143K high-quality agent trajectories for world-grounded image synthesis, enabling effective supervision over the full agentic generation process. We further introduce FactIP, a benchmark covering 12 categories of culturally significant and long-tail factual concepts that explicitly requires external knowledge grounding. Extensive experiments show that our proposed Unify-Agent substantially improves over its base unified model across diverse benchmarks and real world generation tasks, while approaching the world knowledge capabilities of the strongest closed-source models. As an early exploration of agent-based modeling for world-grounded image synthesis, our work highlights the value of tightly coupling reasoning, searching, and generation for reliable open-world agentic image synthesis.
VCapsBench: A Large-scale Fine-grained Benchmark for Video Caption Quality Evaluation
May 29, 2025Video captions play a crucial role in text-to-video generation tasks, as their quality directly influences the semantic coherence and visual fidelity of the generated videos. Although large vision-language models (VLMs) have demonstrated significant potential in caption generation, existing benchmarks inadequately address fine-grained evaluation, particularly in capturing spatial-temporal details critical for video generation. To address this gap, we introduce the Fine-grained Video Caption Evaluation Benchmark (VCapsBench), the first large-scale fine-grained benchmark comprising 5,677 (5K+) videos and 109,796 (100K+) question-answer pairs. These QA-pairs are systematically annotated across 21 fine-grained dimensions (e.g., camera movement, and shot type) that are empirically proven critical for text-to-video generation. We further introduce three metrics (Accuracy (AR), Inconsistency Rate (IR), Coverage Rate (CR)), and an automated evaluation pipeline leveraging large language model (LLM) to verify caption quality via contrastive QA-pairs analysis. By providing actionable insights for caption optimization, our benchmark can advance the development of robust text-to-video models. The dataset and codes are available at website: https://github.com/GXYM/VCapsBench.
Video-Language Alignment Pre-training via Spatio-Temporal Graph Transformer
Jul 16, 2024



Video-language alignment is a crucial multi-modal task that benefits various downstream applications, e.g., video-text retrieval and video question answering. Existing methods either utilize multi-modal information in video-text pairs or apply global and local alignment techniques to promote alignment precision. However, these methods often fail to fully explore the spatio-temporal relationships among vision tokens within video and across different video-text pairs. In this paper, we propose a novel Spatio-Temporal Graph Transformer module to uniformly learn spatial and temporal contexts for video-language alignment pre-training (dubbed STGT). Specifically, our STGT combines spatio-temporal graph structure information with attention in transformer block, effectively utilizing the spatio-temporal contexts. In this way, we can model the relationships between vision tokens, promoting video-text alignment precision for benefiting downstream tasks. In addition, we propose a self-similarity alignment loss to explore the inherent self-similarity in the video and text. With the initial optimization achieved by contrastive learning, it can further promote the alignment accuracy between video and text. Experimental results on challenging downstream tasks, including video-text retrieval and video question answering, verify the superior performance of our method.
Transformer-based Reasoning for Learning Evolutionary Chain of Events on Temporal Knowledge Graph
May 01, 2024Temporal Knowledge Graph (TKG) reasoning often involves completing missing factual elements along the timeline. Although existing methods can learn good embeddings for each factual element in quadruples by integrating temporal information, they often fail to infer the evolution of temporal facts. This is mainly because of (1) insufficiently exploring the internal structure and semantic relationships within individual quadruples and (2) inadequately learning a unified representation of the contextual and temporal correlations among different quadruples. To overcome these limitations, we propose a novel Transformer-based reasoning model (dubbed ECEformer) for TKG to learn the Evolutionary Chain of Events (ECE). Specifically, we unfold the neighborhood subgraph of an entity node in chronological order, forming an evolutionary chain of events as the input for our model. Subsequently, we utilize a Transformer encoder to learn the embeddings of intra-quadruples for ECE. We then craft a mixed-context reasoning module based on the multi-layer perceptron (MLP) to learn the unified representations of inter-quadruples for ECE while accomplishing temporal knowledge reasoning. In addition, to enhance the timeliness of the events, we devise an additional time prediction task to complete effective temporal information within the learned unified representation. Extensive experiments on six benchmark datasets verify the state-of-the-art performance and the effectiveness of our method.
Inverse-like Antagonistic Scene Text Spotting via Reading-Order Estimation and Dynamic Sampling
Jan 08, 2024Scene text spotting is a challenging task, especially for inverse-like scene text, which has complex layouts, e.g., mirrored, symmetrical, or retro-flexed. In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework dubbed IATS, which can effectively spot inverse-like scene texts without sacrificing general ones. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). To optimize and train REM, we propose a joint reading-order estimation loss consisting of a classification loss, an orthogonality loss, and a distribution loss. With the help of IBM, we can divide the initial text boundary into two symmetric control points and iteratively refine the new text boundary using a lightweight boundary refinement module (BRM) for adapting to various shapes and scales. To alleviate the incompatibility between text detection and recognition, we propose a dynamic sampling module (DSM) with a thin-plate spline that can dynamically sample appropriate features for recognition in the detected text region. Without extra supervision, the DSM can proactively learn to sample appropriate features for text recognition through the gradient returned by the recognition module. Extensive experiments on both challenging scene text and inverse-like scene text datasets demonstrate that our method achieves superior performance both on irregular and inverse-like text spotting.
Scene Text Recognition with Single-Point Decoding Network
Sep 05, 2022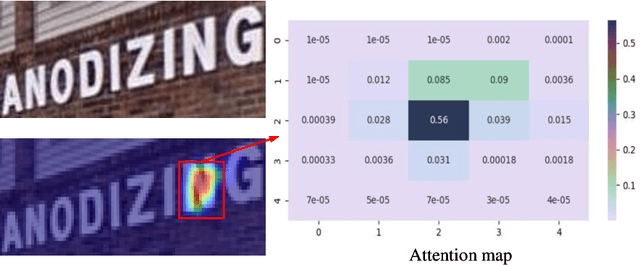
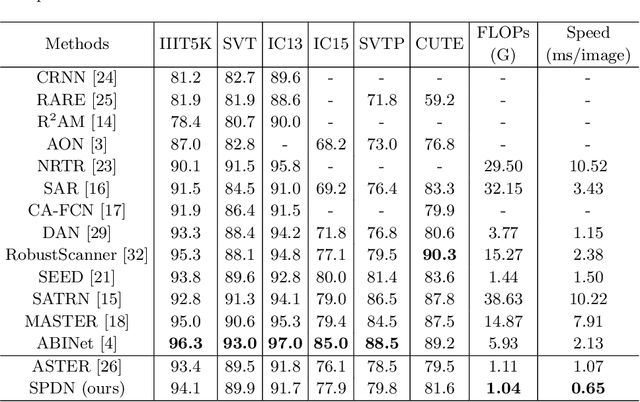
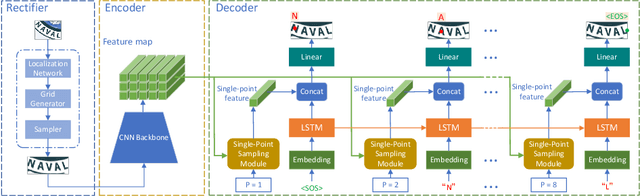
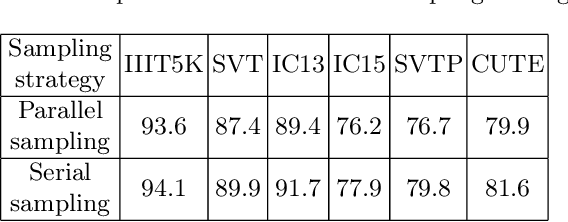
In recent years, attention-based scene text recognition methods have been very popular and attracted the interest of many researchers. Attention-based methods can adaptively focus attention on a small area or even single point during decoding, in which the attention matrix is nearly one-hot distribution. Furthermore, the whole feature maps will be weighted and summed by all attention matrices during inference, causing huge redundant computations. In this paper, we propose an efficient attention-free Single-Point Decoding Network (dubbed SPDN) for scene text recognition, which can replace the traditional attention-based decoding network. Specifically, we propose Single-Point Sampling Module (SPSM) to efficiently sample one key point on the feature map for decoding one character. In this way, our method can not only precisely locate the key point of each character but also remove redundant computations. Based on SPSM, we design an efficient and novel single-point decoding network to replace the attention-based decoding network. Extensive experiments on publicly available benchmarks verify that our SPDN can greatly improve decoding efficiency without sacrificing performance.
Arbitrary Shape Text Detection via Segmentation with Probability Maps
Aug 26, 2022
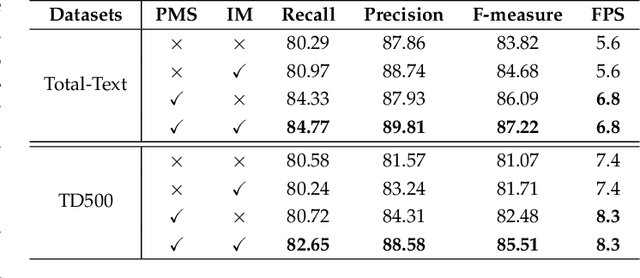

Arbitrary shape text detection is a challenging task due to the significantly varied sizes and aspect ratios, arbitrary orientations or shapes, inaccurate annotations, etc. Due to the scalability of pixel-level prediction, segmentation-based methods can adapt to various shape texts and hence attracted considerable attention recently. However, accurate pixel-level annotations of texts are formidable, and the existing datasets for scene text detection only provide coarse-grained boundary annotations. Consequently, numerous misclassified text pixels or background pixels inside annotations always exist, degrading the performance of segmentation-based text detection methods. Generally speaking, whether a pixel belongs to text or not is highly related to the distance with the adjacent annotation boundary. With this observation, in this paper, we propose an innovative and robust segmentation-based detection method via probability maps for accurately detecting text instances. To be concrete, we adopt a Sigmoid Alpha Function (SAF) to transfer the distances between boundaries and their inside pixels to a probability map. However, one probability map can not cover complex probability distributions well because of the uncertainty of coarse-grained text boundary annotations. Therefore, we adopt a group of probability maps computed by a series of Sigmoid Alpha Functions to describe the possible probability distributions. In addition, we propose an iterative model to learn to predict and assimilate probability maps for providing enough information to reconstruct text instances. Finally, simple region growth algorithms are adopted to aggregate probability maps to complete text instances. Experimental results demonstrate that our method achieves state-of-the-art performance in terms of detection accuracy on several benchmarks.
Arbitrary Shape Text Detection via Boundary Transformer
May 11, 2022



Arbitrary shape text detection is a challenging task due to its complexity and variety, e.g, various scales, random rotations, and curve shapes. In this paper, we propose an arbitrary shape text detector with a boundary transformer, which can accurately and directly locate text boundaries without any post-processing. Our method mainly consists of a boundary proposal module and an iteratively optimized boundary transformer module. The boundary proposal module consisting of multi-layer dilated convolutions will compute important prior information (including classification map, distance field, and direction field) for generating coarse boundary proposals meanwhile guiding the optimization of boundary transformer. The boundary transformer module adopts an encoder-decoder structure, in which the encoder is constructed by multi-layer transformer blocks with residual connection while the decoder is a simple multi-layer perceptron network (MLP). Under the guidance of prior information, the boundary transformer module will gradually refine the coarse boundary proposals via boundary deformation in an iterative manner. Furthermore, we propose a novel boundary energy loss (BEL) which introduces an energy minimization constraint and an energy monotonically decreasing constraint for every boundary optimization step. Extensive experiments on publicly available and challenging datasets demonstrate the state-of-the-art performance and promising efficiency of our method.
Graph Fusion Network for Multi-Oriented Object Detection
May 07, 2022
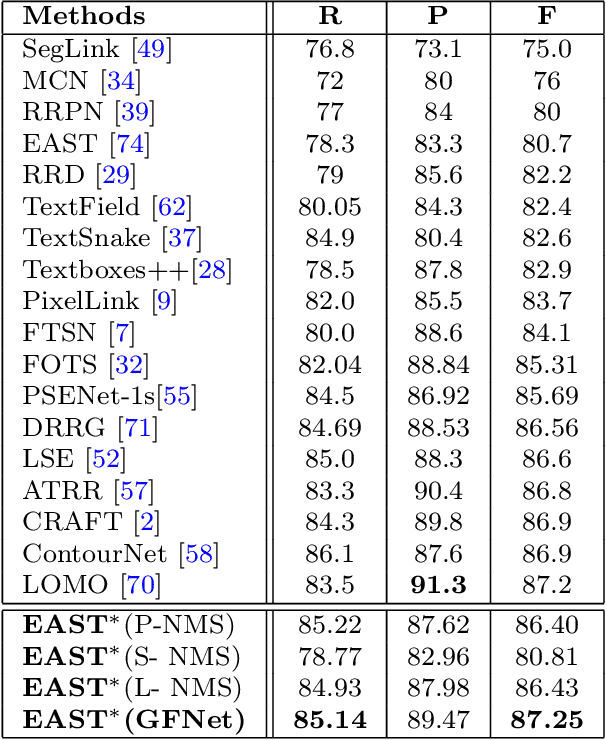
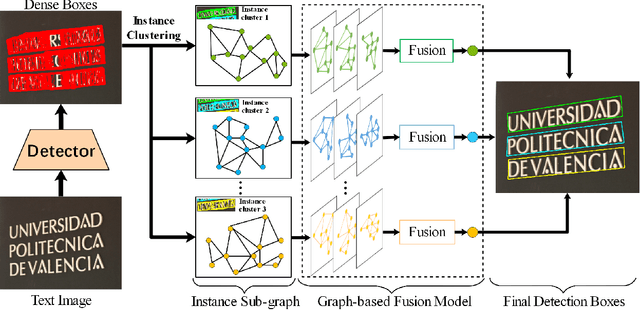
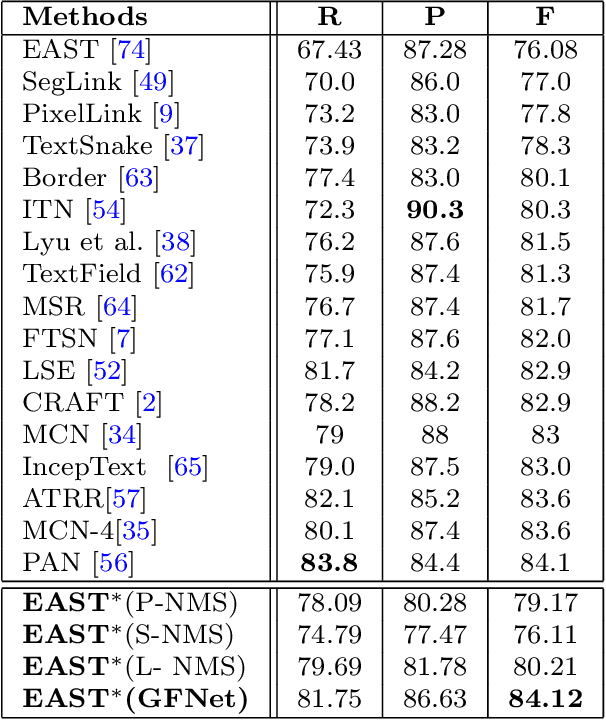
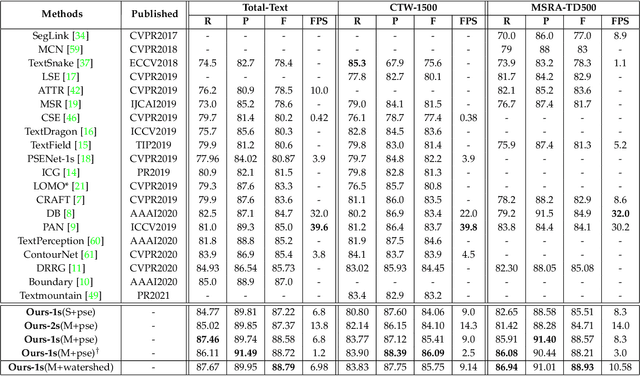
In object detection, non-maximum suppression (NMS) methods are extensively adopted to remove horizontal duplicates of detected dense boxes for generating final object instances. However, due to the degraded quality of dense detection boxes and not explicit exploration of the context information, existing NMS methods via simple intersection-over-union (IoU) metrics tend to underperform on multi-oriented and long-size objects detection. Distinguishing with general NMS methods via duplicate removal, we propose a novel graph fusion network, named GFNet, for multi-oriented object detection. Our GFNet is extensible and adaptively fuse dense detection boxes to detect more accurate and holistic multi-oriented object instances. Specifically, we first adopt a locality-aware clustering algorithm to group dense detection boxes into different clusters. We will construct an instance sub-graph for the detection boxes belonging to one cluster. Then, we propose a graph-based fusion network via Graph Convolutional Network (GCN) to learn to reason and fuse the detection boxes for generating final instance boxes. Extensive experiments both on public available multi-oriented text datasets (including MSRA-TD500, ICDAR2015, ICDAR2017-MLT) and multi-oriented object datasets (DOTA) verify the effectiveness and robustness of our method against general NMS methods in multi-oriented object detection.
Kernel Proposal Network for Arbitrary Shape Text Detection
Mar 12, 2022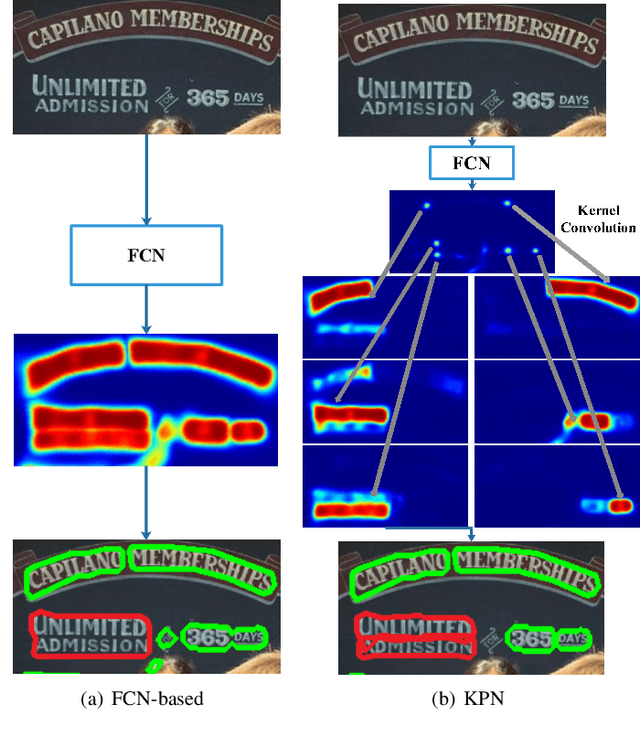


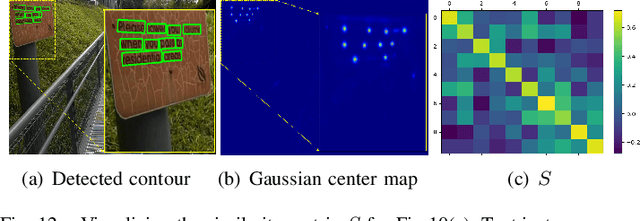
Segmentation-based methods have achieved great success for arbitrary shape text detection. However, separating neighboring text instances is still one of the most challenging problems due to the complexity of texts in scene images. In this paper, we propose an innovative Kernel Proposal Network (dubbed KPN) for arbitrary shape text detection. The proposed KPN can separate neighboring text instances by classifying different texts into instance-independent feature maps, meanwhile avoiding the complex aggregation process existing in segmentation-based arbitrary shape text detection methods. To be concrete, our KPN will predict a Gaussian center map for each text image, which will be used to extract a series of candidate kernel proposals (i.e., dynamic convolution kernel) from the embedding feature maps according to their corresponding keypoint positions. To enforce the independence between kernel proposals, we propose a novel orthogonal learning loss (OLL) via orthogonal constraints. Specifically, our kernel proposals contain important self-information learned by network and location information by position embedding. Finally, kernel proposals will individually convolve all embedding feature maps for generating individual embedded maps of text instances. In this way, our KPN can effectively separate neighboring text instances and improve the robustness against unclear boundaries. To our knowledge, our work is the first to introduce the dynamic convolution kernel strategy to efficiently and effectively tackle the adhesion problem of neighboring text instances in text detection. Experimental results on challenging datasets verify the impressive performance and efficiency of our method. The code and model are available at https://github.com/GXYM/KPN.