 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Real-World Super-Resolution via Rectified Flow Degradation Modelling
Aug 10, 2025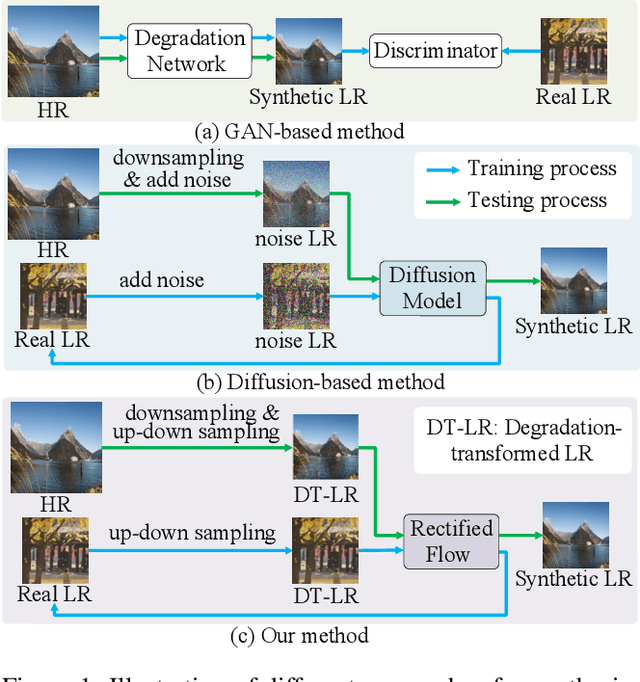
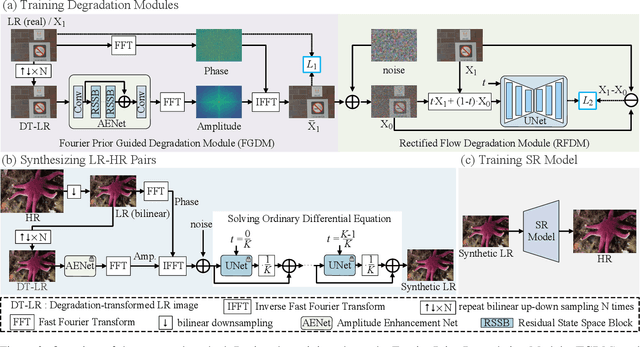

Unsupervised real-world super-resolution (SR) faces critical challenges due to the complex, unknown degradation distributions in practical scenarios. Existing methods struggle to generalize from synthetic low-resolution (LR) and high-resolution (HR) image pairs to real-world data due to a significant domain gap. In this paper, we propose an unsupervised real-world SR method based on rectified flow to effectively capture and model real-world degradation, synthesizing LR-HR training pairs with realistic degradation. Specifically, given unpaired LR and HR images, we propose a novel Rectified Flow Degradation Module (RFDM) that introduces degradation-transformed LR (DT-LR) images as intermediaries. By modeling the degradation trajectory in a continuous and invertible manner, RFDM better captures real-world degradation and enhances the realism of generated LR images. Additionally, we propose a Fourier Prior Guided Degradation Module (FGDM) that leverages structural information embedded in Fourier phase components to ensure more precise modeling of real-world degradation. Finally, the LR images are processed by both FGDM and RFDM, producing final synthetic LR images with real-world degradation. The synthetic LR images are paired with the given HR images to train the off-the-shelf SR networks. Extensive experiments on real-world datasets demonstrate that our method significantly enhances the performance of existing SR approaches in real-world scenarios.
Similarity Matters: A Novel Depth-guided Network for Image Restoration and A New Dataset
Aug 10, 2025Image restoration has seen substantial progress in recent years. However, existing methods often neglect depth information, which hurts similarity matching, results in attention distractions in shallow depth-of-field (DoF) scenarios, and excessive enhancement of background content in deep DoF settings. To overcome these limitations, we propose a novel Depth-Guided Network (DGN) for image restoration, together with a novel large-scale high-resolution dataset. Specifically, the network consists of two interactive branches: a depth estimation branch that provides structural guidance, and an image restoration branch that performs the core restoration task. In addition, the image restoration branch exploits intra-object similarity through progressive window-based self-attention and captures inter-object similarity via sparse non-local attention. Through joint training, depth features contribute to improved restoration quality, while the enhanced visual features from the restoration branch in turn help refine depth estimation. Notably, we also introduce a new dataset for training and evaluation, consisting of 9,205 high-resolution images from 403 plant species, with diverse depth and texture variations. Extensive experiments show that our method achieves state-of-the-art performance on several standard benchmarks and generalizes well to unseen plant images, demonstrating its effectiveness and robustness.
Arbitrary Time Information Modeling via Polynomial Approximation for Temporal Knowledge Graph Embedding
May 01, 2024



Distinguished from traditional knowledge graphs (KGs), temporal knowledge graphs (TKGs) must explore and reason over temporally evolving facts adequately. However, existing TKG approaches still face two main challenges, i.e., the limited capability to model arbitrary timestamps continuously and the lack of rich inference patterns under temporal constraints. In this paper, we propose an innovative TKGE method (PTBox) via polynomial decomposition-based temporal representation and box embedding-based entity representation to tackle the above-mentioned problems. Specifically, we decompose time information by polynomials and then enhance the model's capability to represent arbitrary timestamps flexibly by incorporating the learnable temporal basis tensor. In addition, we model every entity as a hyperrectangle box and define each relation as a transformation on the head and tail entity boxes. The entity boxes can capture complex geometric structures and learn robust representations, improving the model's inductive capability for rich inference patterns. Theoretically, our PTBox can encode arbitrary time information or even unseen timestamps while capturing rich inference patterns and higher-arity relations of the knowledge base. Extensive experiments on real-world datasets demonstrate the effectiveness of our method.
Transformer-based Reasoning for Learning Evolutionary Chain of Events on Temporal Knowledge Graph
May 01, 2024Temporal Knowledge Graph (TKG) reasoning often involves completing missing factual elements along the timeline. Although existing methods can learn good embeddings for each factual element in quadruples by integrating temporal information, they often fail to infer the evolution of temporal facts. This is mainly because of (1) insufficiently exploring the internal structure and semantic relationships within individual quadruples and (2) inadequately learning a unified representation of the contextual and temporal correlations among different quadruples. To overcome these limitations, we propose a novel Transformer-based reasoning model (dubbed ECEformer) for TKG to learn the Evolutionary Chain of Events (ECE). Specifically, we unfold the neighborhood subgraph of an entity node in chronological order, forming an evolutionary chain of events as the input for our model. Subsequently, we utilize a Transformer encoder to learn the embeddings of intra-quadruples for ECE. We then craft a mixed-context reasoning module based on the multi-layer perceptron (MLP) to learn the unified representations of inter-quadruples for ECE while accomplishing temporal knowledge reasoning. In addition, to enhance the timeliness of the events, we devise an additional time prediction task to complete effective temporal information within the learned unified representation. Extensive experiments on six benchmark datasets verify the state-of-the-art performance and the effectiveness of our method.
Learning Aligned Cross-Modal Representation for Generalized Zero-Shot Classification
Dec 24, 2021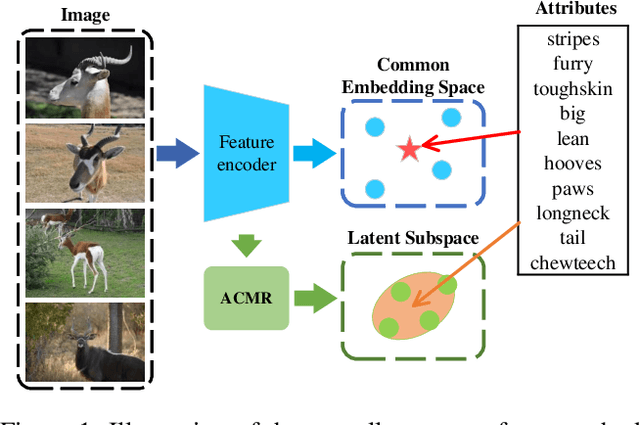



Learning a common latent embedding by aligning the latent spaces of cross-modal autoencoders is an effective strategy for Generalized Zero-Shot Classification (GZSC). However, due to the lack of fine-grained instance-wise annotations, it still easily suffer from the domain shift problem for the discrepancy between the visual representation of diversified images and the semantic representation of fixed attributes. In this paper, we propose an innovative autoencoder network by learning Aligned Cross-Modal Representations (dubbed ACMR) for GZSC. Specifically, we propose a novel Vision-Semantic Alignment (VSA) method to strengthen the alignment of cross-modal latent features on the latent subspaces guided by a learned classifier. In addition, we propose a novel Information Enhancement Module (IEM) to reduce the possibility of latent variables collapse meanwhile encouraging the discriminative ability of latent variables. Extensive experiments on publicly available datasets demonstrate the state-of-the-art performance of our method.
RUArt: A Novel Text-Centered Solution for Text-Based Visual Question Answering
Oct 24, 2020
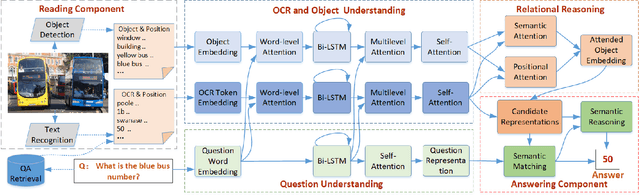

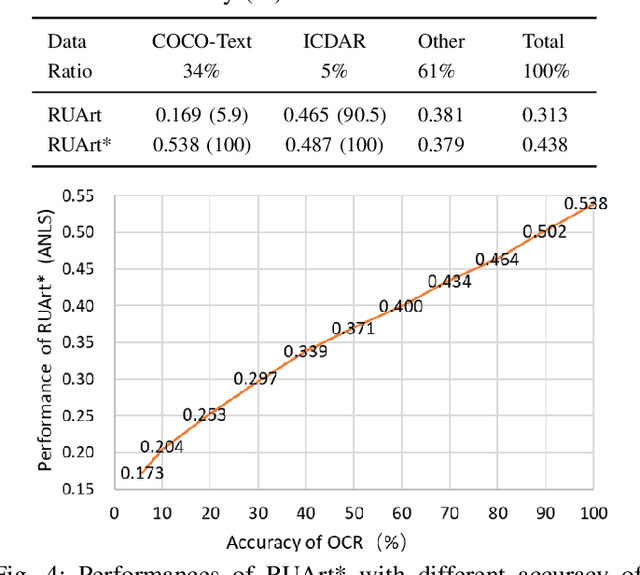
Text-based visual question answering (VQA) requires to read and understand text in an image to correctly answer a given question. However, most current methods simply add optical character recognition (OCR) tokens extracted from the image into the VQA model without considering contextual information of OCR tokens and mining the relationships between OCR tokens and scene objects. In this paper, we propose a novel text-centered method called RUArt (Reading, Understanding and Answering the Related Text) for text-based VQA. Taking an image and a question as input, RUArt first reads the image and obtains text and scene objects. Then, it understands the question, OCRed text and objects in the context of the scene, and further mines the relationships among them. Finally, it answers the related text for the given question through text semantic matching and reasoning. We evaluate our RUArt on two text-based VQA benchmarks (ST-VQA and TextVQA) and conduct extensive ablation studies for exploring the reasons behind RUArt's effectiveness. Experimental results demonstrate that our method can effectively explore the contextual information of the text and mine the stable relationships between the text and objects.