 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxiTrace: Gradient-Aligned Training for Explainable Chinese Toxicity Detection
Apr 14, 2026Existing Chinese toxic content detection methods mainly target sentence-level classification but often fail to provide readable and contiguous toxic evidence spans. We propose \textbf{ToxiTrace}, an explainability-oriented method for BERT-style encoders with three components: (1) \textbf{CuSA}, which refines encoder-derived saliency cues into fine-grained toxic spans with lightweight LLM guidance; (2) \textbf{GCLoss}, a gradient-constrained objective that concentrates token-level saliency on toxic evidence while suppressing irrelevant activations; and (3) \textbf{ARCL}, which constructs sample-specific contrastive reasoning pairs to sharpen the semantic boundary between toxic and non-toxic content. Experiments show that ToxiTrace improves classification accuracy and toxic span extraction while preserving efficient encoder-based inference and producing more coherent, human-readable explanations. We have released the model at https://huggingface.co/ArdLi/ToxiTrace.
UPDA: Unsupervised Progressive Domain Adaptation for No-Reference Point Cloud Quality Assessment
Feb 12, 2026While no-reference point cloud quality assessment (NR-PCQA) approaches have achieved significant progress over the past decade, their performance often degrades substantially when a distribution gap exists between the training (source domain) and testing (target domain) data. However, to date, limited attention has been paid to transferring NR-PCQA models across domains. To address this challenge, we propose the first unsupervised progressive domain adaptation (UPDA) framework for NR-PCQA, which introduces a two-stage coarse-to-fine alignment paradigm to address domain shifts. At the coarse-grained stage, a discrepancy-aware coarse-grained alignment method is designed to capture relative quality relationships between cross-domain samples through a novel quality-discrepancy-aware hybrid loss, circumventing the challenges of direct absolute feature alignment. At the fine-grained stage, a perception fusion fine-grained alignment approach with symmetric feature fusion is developed to identify domain-invariant features, while a conditional discriminator selectively enhances the transfer of quality-relevant features. Extensive experiments demonstrate that the proposed UPDA effectively enhances the performance of NR-PCQA methods in cross-domain scenarios, validating its practical applicability. The code is available at https://github.com/yokeno1/UPDA-main.
ReLKD: Inter-Class Relation Learning with Knowledge Distillation for Generalized Category Discovery
Dec 08, 2025Generalized Category Discovery (GCD) faces the challenge of categorizing unlabeled data containing both known and novel classes, given only labels for known classes. Previous studies often treat each class independently, neglecting the inherent inter-class relations. Obtaining such inter-class relations directly presents a significant challenge in real-world scenarios. To address this issue, we propose ReLKD, an end-to-end framework that effectively exploits implicit inter-class relations and leverages this knowledge to enhance the classification of novel classes. ReLKD comprises three key modules: a target-grained module for learning discriminative representations, a coarse-grained module for capturing hierarchical class relations, and a distillation module for transferring knowledge from the coarse-grained module to refine the target-grained module's representation learning. Extensive experiments on four datasets demonstrate the effectiveness of ReLKD, particularly in scenarios with limited labeled data. The code for ReLKD is available at https://github.com/ZhouF-ECNU/ReLKD.
ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023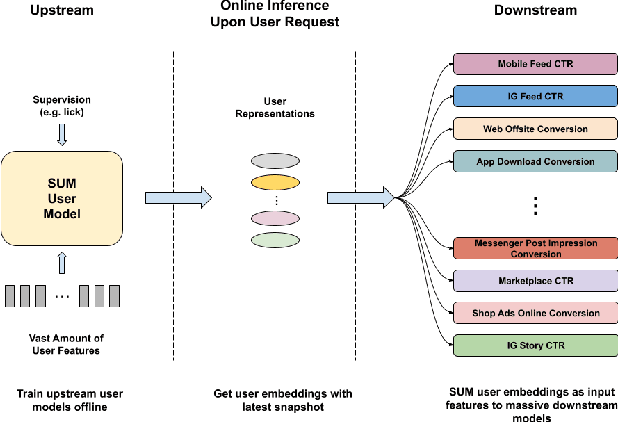
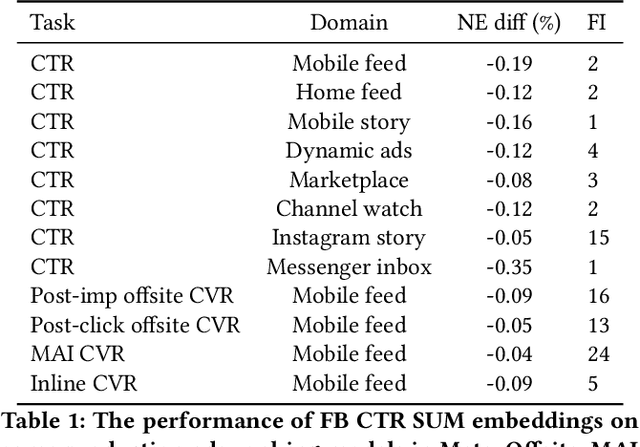
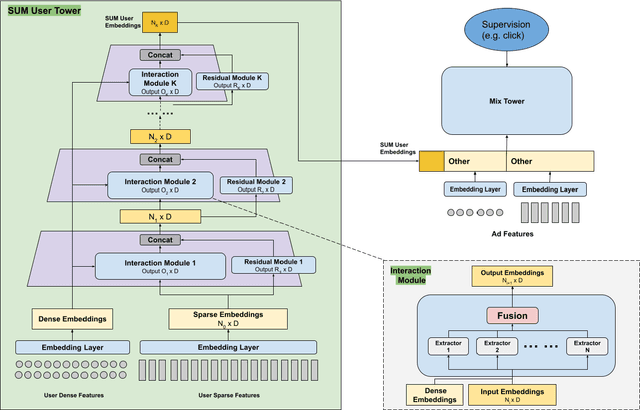

Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.
Cooperative Network Learning for Large-Scale and Decentralized Graphs
Nov 07, 2023


Graph research, the systematic study of interconnected data points represented as graphs, plays a vital role in capturing intricate relationships within networked systems. However, in the real world, as graphs scale up, concerns about data security among different data-owning agencies arise, hindering information sharing and, ultimately, the utilization of graph data. Therefore, establishing a mutual trust mechanism among graph agencies is crucial for unlocking the full potential of graphs. Here, we introduce a Cooperative Network Learning (CNL) framework to ensure secure graph computing for various graph tasks. Essentially, this CNL framework unifies the local and global perspectives of GNN computing with distributed data for an agency by virtually connecting all participating agencies as a global graph without a fixed central coordinator. Inter-agency computing is protected by various technologies inherent in our framework, including homomorphic encryption and secure transmission. Moreover, each agency has a fair right to design or employ various graph learning models from its local or global perspective. Thus, CNL can collaboratively train GNN models based on decentralized graphs inferred from local and global graphs. Experiments on contagion dynamics prediction and traditional graph tasks (i.e., node classification and link prediction) demonstrate that our CNL architecture outperforms state-of-the-art GNNs developed at individual sites, revealing that CNL can provide a reliable, fair, secure, privacy-preserving, and global perspective to build effective and personalized models for network applications. We hope this framework will address privacy concerns in graph-related research and integrate decentralized graph data structures to benefit the network research community in cooperation and innovation.
Fast Heterogeneous Federated Learning with Hybrid Client Selection
Aug 16, 2022
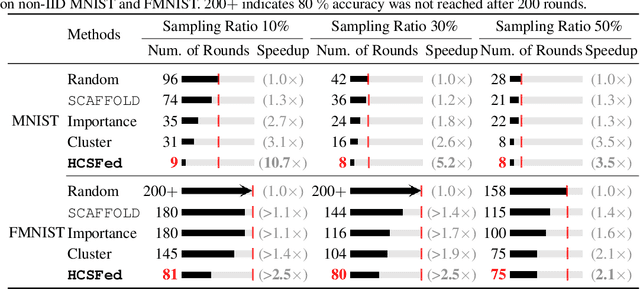
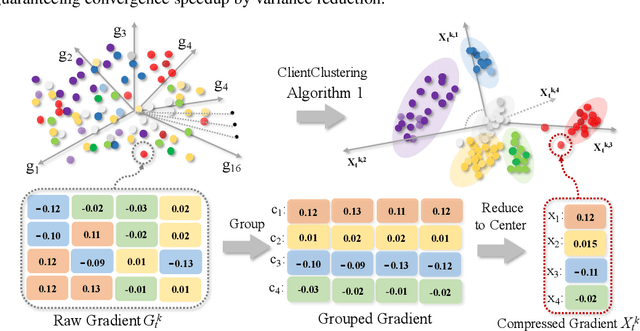
Client selection schemes are widely adopted to handle the communication-efficient problems in recent studies of Federated Learning (FL). However, the large variance of the model updates aggregated from the randomly-selected unrepresentative subsets directly slows the FL convergence. We present a novel clustering-based client selection scheme to accelerate the FL convergence by variance reduction. Simple yet effective schemes are designed to improve the clustering effect and control the effect fluctuation, therefore, generating the client subset with certain representativeness of sampling. Theoretically, we demonstrate the improvement of the proposed scheme in variance reduction. We also present the tighter convergence guarantee of the proposed method thanks to the variance reduction. Experimental results confirm the exceed efficiency of our scheme compared to alternatives.
Variance-Reduced Heterogeneous Federated Learning via Stratified Client Selection
Jan 15, 2022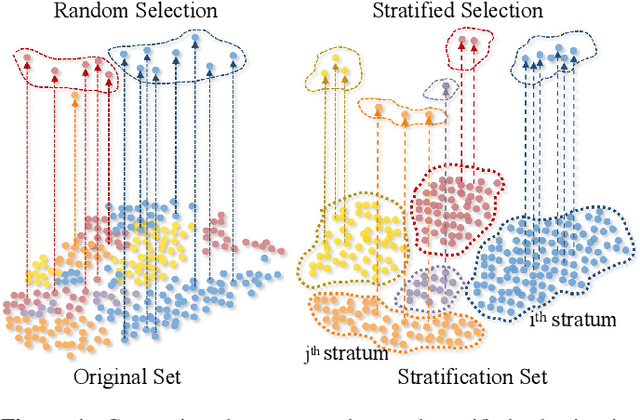
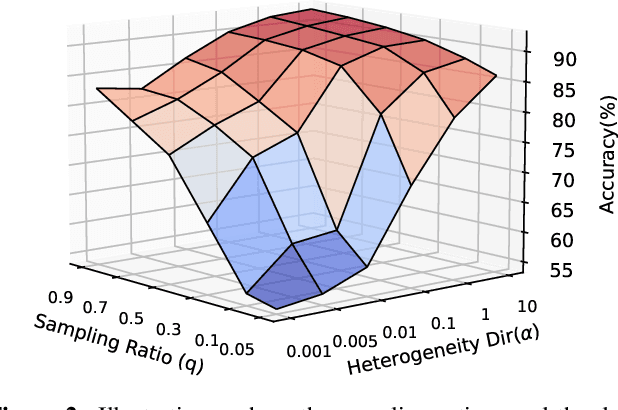
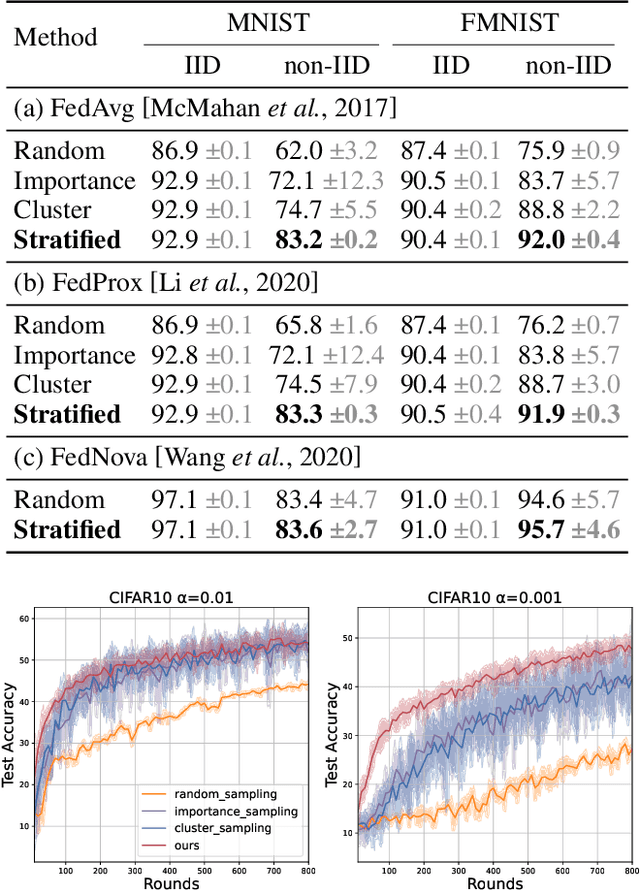
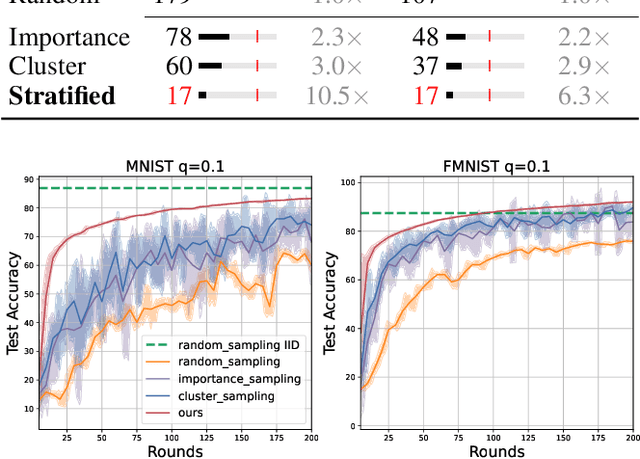
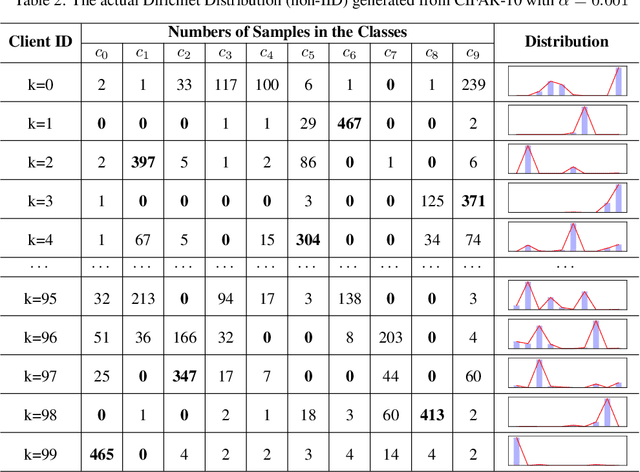
Client selection strategies are widely adopted to handle the communication-efficient problem in recent studies of Federated Learning (FL). However, due to the large variance of the selected subset's update, prior selection approaches with a limited sampling ratio cannot perform well on convergence and accuracy in heterogeneous FL. To address this problem, in this paper, we propose a novel stratified client selection scheme to reduce the variance for the pursuit of better convergence and higher accuracy. Specifically, to mitigate the impact of heterogeneity, we develop stratification based on clients' local data distribution to derive approximate homogeneous strata for better selection in each stratum. Concentrating on a limited sampling ratio scenario, we next present an optimized sample size allocation scheme by considering the diversity of stratum's variability, with the promise of further variance reduction. Theoretically, we elaborate the explicit relation among different selection schemes with regard to variance, under heterogeneous settings, we demonstrate the effectiveness of our selection scheme. Experimental results confirm that our approach not only allows for better performance relative to state-of-the-art methods but also is compatible with prevalent FL algorithms.
Multi-Person Passive WiFi Indoor Localization with Intelligent Reflecting Surface
Jan 05, 2022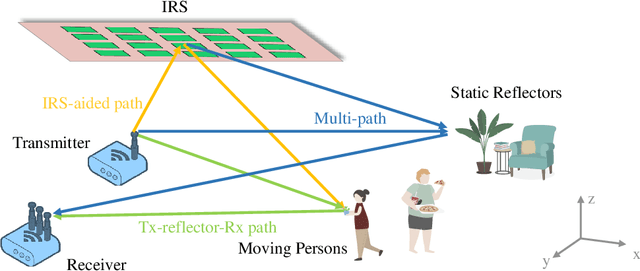
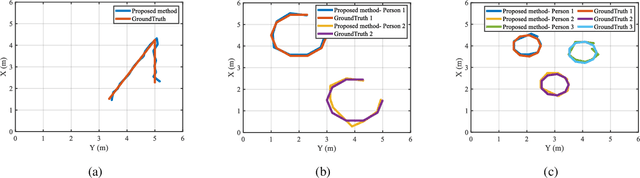
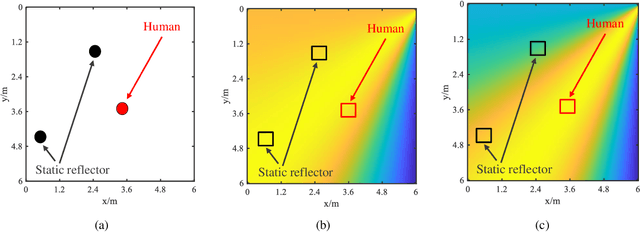
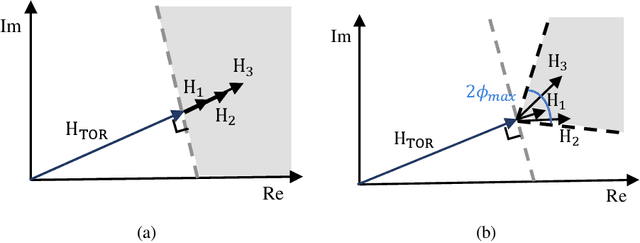
The past years have witnessed increasing research interest in achieving passive human localization with commodity WiFi devices. However, due to the fundamental limited spatial resolution of WiFi signals, it is still very difficult to achieve accurate localization with existing commodity WiFi devices. To tackle this problem, in this paper, we propose to exploit the degree of freedom provided by the Intelligent Reflecting Surface (IRS), which is composed of a large number of controllable reflective elements, to modulate the spatial distribution of WiFi signals and thus break down the spatial resolution limitation of WiFi signals to achieve accurate localization. Specifically, in the single-person scenario, we derive the closed-form solution to optimally control the phase shift of the IRS elements. In the multi-person scenario, we propose a Side-lobe Cancellation Algorithm to eliminate the near-far effect to achieve accurate localization of multiple persons in an iterative manner. Extensive simulation results demonstrate that without any change to the existing WiFi infrastructure, the proposed framework can locate multiple moving persons passively with sub-centimeter accuracy under multipath interference and random noise.
Contactless Electrocardiogram Monitoring with Millimeter Wave Radar
Dec 21, 2021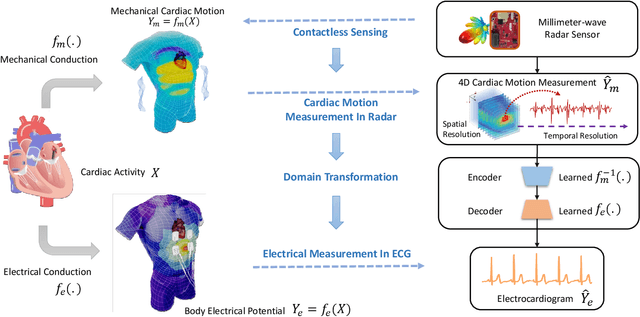

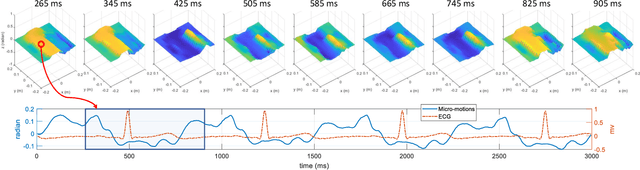
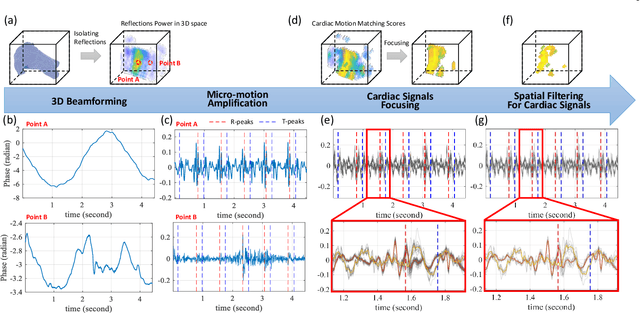
The electrocardiogram (ECG) has always been an important biomedical test to diagnose cardiovascular diseases. Current approaches for ECG monitoring are based on body attached electrodes leading to uncomfortable user experience. Therefore, contactless ECG monitoring has drawn tremendous attention, which however remains unsolved. In fact, cardiac electrical-mechanical activities are coupling in a well-coordinated pattern. In this paper, we achieve contactless ECG monitoring by breaking the boundary between the cardiac mechanical and electrical activity. Specifically, we develop a millimeter-wave radar system to contactlessly measure cardiac mechanical activity and reconstruct ECG without any contact in. To measure the cardiac mechanical activity comprehensively, we propose a series of signal processing algorithms to extract 4D cardiac motions from radio frequency (RF) signals. Furthermore, we design a deep neural network to solve the cardiac related domain transformation problem and achieve end-to-end reconstruction mapping from RF input to the ECG output. The experimental results show that our contactless ECG measurements achieve timing accuracy of cardiac electrical events with median error below 14ms and morphology accuracy with median Pearson-Correlation of 90% and median Root-Mean-Square-Error of 0.081mv compared to the groudtruth ECG. These results indicate that the system enables the potential of contactless, continuous and accurate ECG monitoring.