 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUArt: A Novel Text-Centered Solution for Text-Based Visual Question Answering
Oct 24, 2020
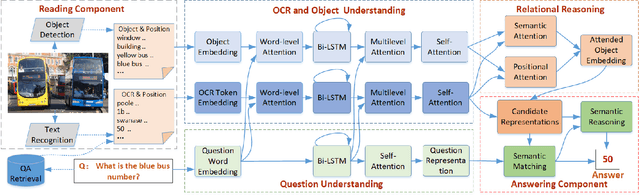

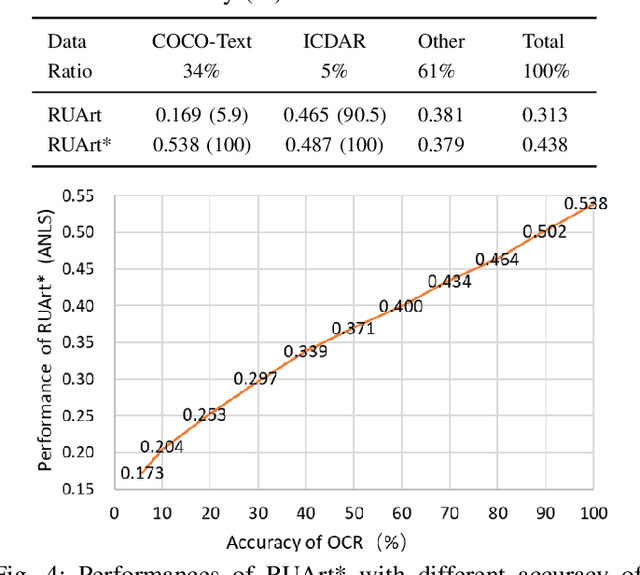
Text-based visual question answering (VQA) requires to read and understand text in an image to correctly answer a given question. However, most current methods simply add optical character recognition (OCR) tokens extracted from the image into the VQA model without considering contextual information of OCR tokens and mining the relationships between OCR tokens and scene objects. In this paper, we propose a novel text-centered method called RUArt (Reading, Understanding and Answering the Related Text) for text-based VQA. Taking an image and a question as input, RUArt first reads the image and obtains text and scene objects. Then, it understands the question, OCRed text and objects in the context of the scene, and further mines the relationships among them. Finally, it answers the related text for the given question through text semantic matching and reasoning. We evaluate our RUArt on two text-based VQA benchmarks (ST-VQA and TextVQA) and conduct extensive ablation studies for exploring the reasons behind RUArt's effectiveness. Experimental results demonstrate that our method can effectively explore the contextual information of the text and mine the stable relationships between the text and objects.