 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Heterogeneous Federated Learning with Hybrid Client Selection
Aug 16, 2022
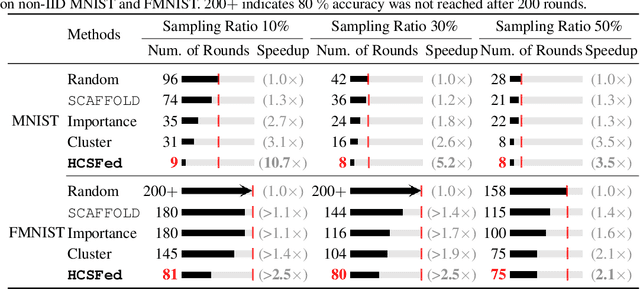
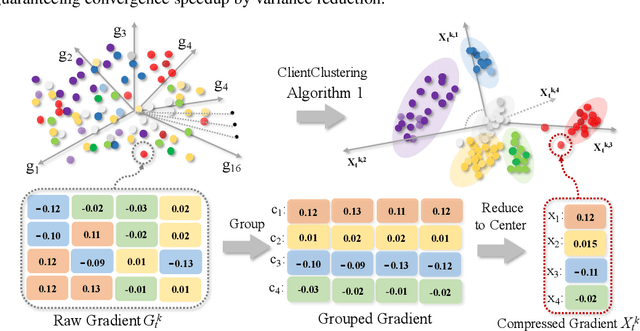
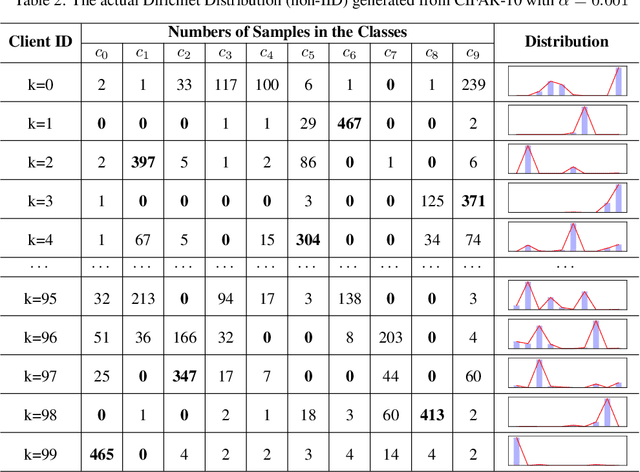
Client selection schemes are widely adopted to handle the communication-efficient problems in recent studies of Federated Learning (FL). However, the large variance of the model updates aggregated from the randomly-selected unrepresentative subsets directly slows the FL convergence. We present a novel clustering-based client selection scheme to accelerate the FL convergence by variance reduction. Simple yet effective schemes are designed to improve the clustering effect and control the effect fluctuation, therefore, generating the client subset with certain representativeness of sampling. Theoretically, we demonstrate the improvement of the proposed scheme in variance reduction. We also present the tighter convergence guarantee of the proposed method thanks to the variance reduction. Experimental results confirm the exceed efficiency of our scheme compared to alternatives.
Variance-Reduced Heterogeneous Federated Learning via Stratified Client Selection
Jan 15, 2022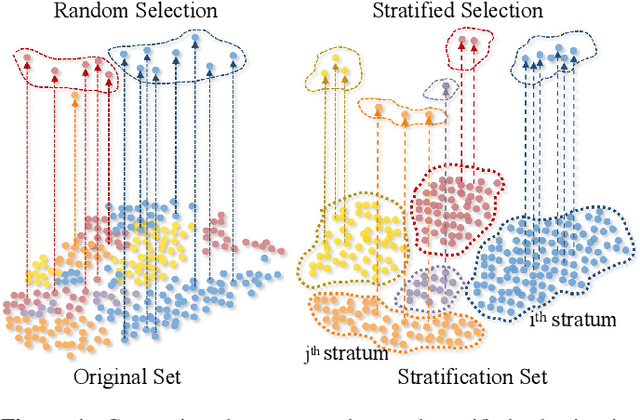
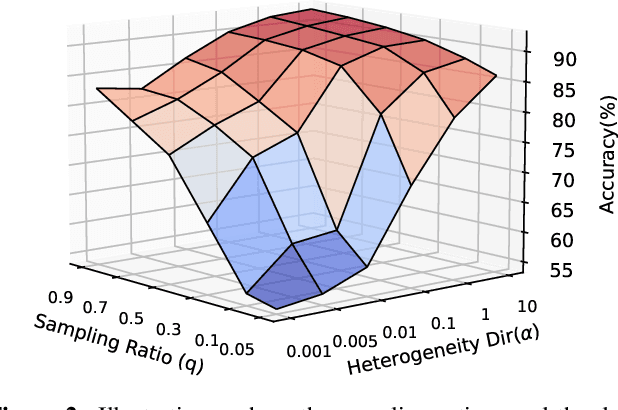
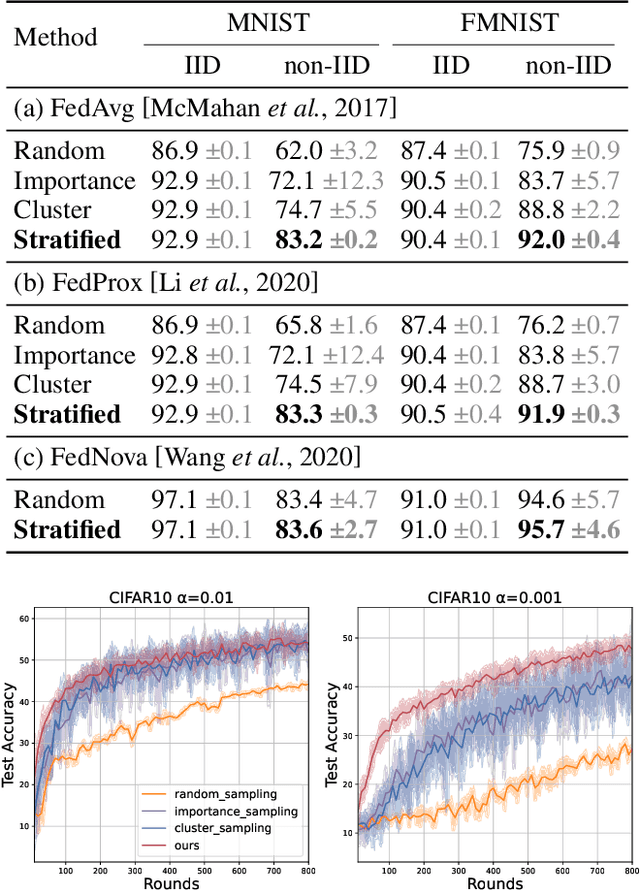
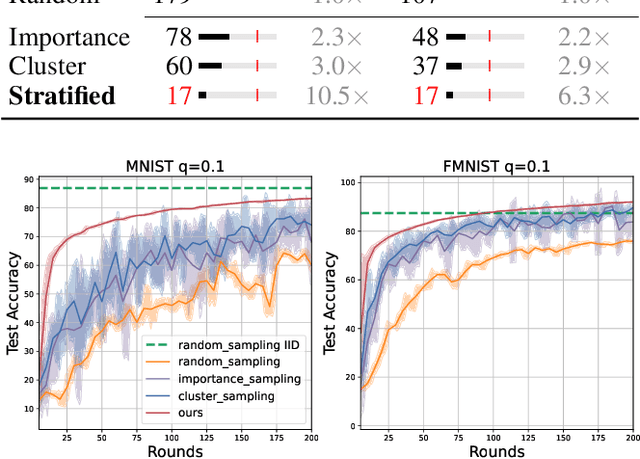
Client selection strategies are widely adopted to handle the communication-efficient problem in recent studies of Federated Learning (FL). However, due to the large variance of the selected subset's update, prior selection approaches with a limited sampling ratio cannot perform well on convergence and accuracy in heterogeneous FL. To address this problem, in this paper, we propose a novel stratified client selection scheme to reduce the variance for the pursuit of better convergence and higher accuracy. Specifically, to mitigate the impact of heterogeneity, we develop stratification based on clients' local data distribution to derive approximate homogeneous strata for better selection in each stratum. Concentrating on a limited sampling ratio scenario, we next present an optimized sample size allocation scheme by considering the diversity of stratum's variability, with the promise of further variance reduction. Theoretically, we elaborate the explicit relation among different selection schemes with regard to variance, under heterogeneous settings, we demonstrate the effectiveness of our selection scheme. Experimental results confirm that our approach not only allows for better performance relative to state-of-the-art methods but also is compatible with prevalent FL algorithms.