 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFNet: Deep Imaging and Focusing for Handheld SAR with Millimeter-wave Signals
May 06, 2024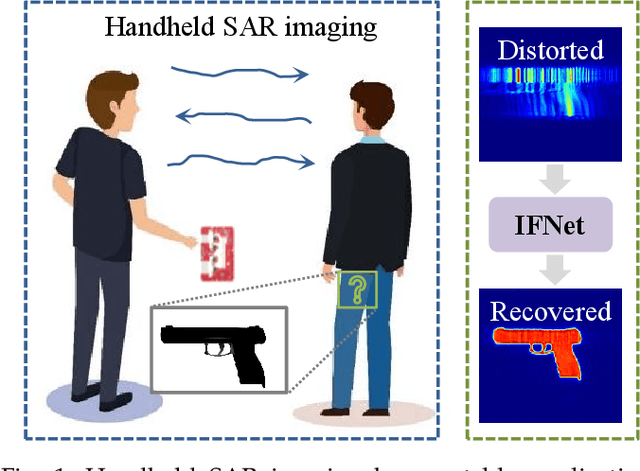
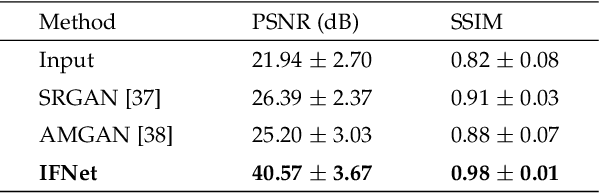

Recent advancements have showcased the potential of handheld millimeter-wave (mmWave) imaging, which applies synthetic aperture radar (SAR) principles in portable settings. However, existing studies addressing handheld motion errors either rely on costly tracking devices or employ simplified imaging models, leading to impractical deployment or limited performance. In this paper, we present IFNet, a novel deep unfolding network that combines the strengths of signal processing models and deep neural networks to achieve robust imaging and focusing for handheld mmWave systems. We first formulate the handheld imaging model by integrating multiple priors about mmWave images and handheld phase errors. Furthermore, we transform the optimization processes into an iterative network structure for improved and efficient imaging performance. Extensive experiments demonstrate that IFNet effectively compensates for handheld phase errors and recovers high-fidelity images from severely distorted signals. In comparison with existing methods, IFNet can achieve at least 11.89 dB improvement in average peak signal-to-noise ratio (PSNR) and 64.91% improvement in average structural similarity index measure (SSIM) on a real-world dataset.
Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
Mar 26, 2024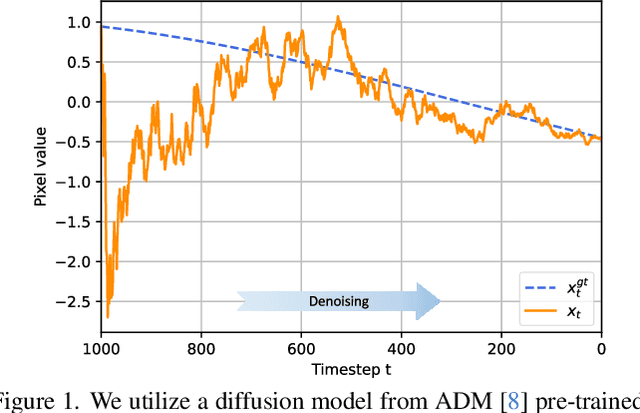
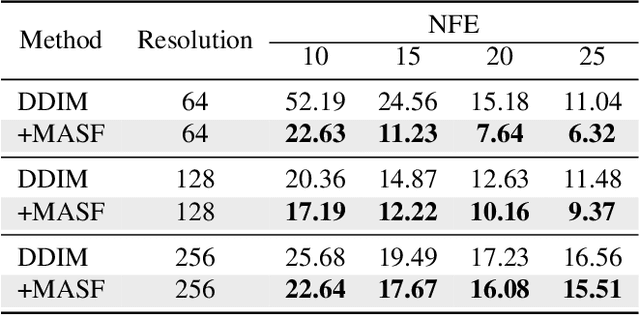

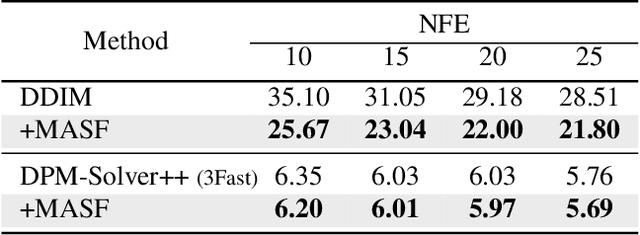
Diffusion models have recently brought a powerful revolution in image generation. Despite showing impressive generative capabilities, most of these models rely on the current sample to denoise the next one, possibly resulting in denoising instability. In this paper, we reinterpret the iterative denoising process as model optimization and leverage a moving average mechanism to ensemble all the prior samples. Instead of simply applying moving average to the denoised samples at different timesteps, we first map the denoised samples to data space and then perform moving average to avoid distribution shift across timesteps. In view that diffusion models evolve the recovery from low-frequency components to high-frequency details, we further decompose the samples into different frequency components and execute moving average separately on each component. We name the complete approach "Moving Average Sampling in Frequency domain (MASF)". MASF could be seamlessly integrated into mainstream pre-trained diffusion models and sampling schedules. Extensive experiments on both unconditional and conditional diffusion models demonstrate that our MASF leads to superior performances compared to the baselines, with almost negligible additional complexity cost.
Revisiting Single Image Reflection Removal In the Wild
Nov 29, 2023This research focuses on the issue of single-image reflection removal (SIRR) in real-world conditions, examining it from two angles: the collection pipeline of real reflection pairs and the perception of real reflection locations. We devise an advanced reflection collection pipeline that is highly adaptable to a wide range of real-world reflection scenarios and incurs reduced costs in collecting large-scale aligned reflection pairs. In the process, we develop a large-scale, high-quality reflection dataset named Reflection Removal in the Wild (RRW). RRW contains over 14,950 high-resolution real-world reflection pairs, a dataset forty-five times larger than its predecessors. Regarding perception of reflection locations, we identify that numerous virtual reflection objects visible in reflection images are not present in the corresponding ground-truth images. This observation, drawn from the aligned pairs, leads us to conceive the Maximum Reflection Filter (MaxRF). The MaxRF could accurately and explicitly characterize reflection locations from pairs of images. Building upon this, we design a reflection location-aware cascaded framework, specifically tailored for SIRR. Powered by these innovative techniques, our solution achieves superior performance than current leading methods across multiple real-world benchmarks. Codes and datasets will be publicly available.
Principled Knowledge Extrapolation with GANs
May 21, 2022
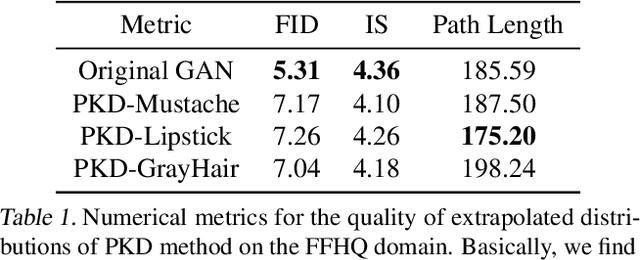
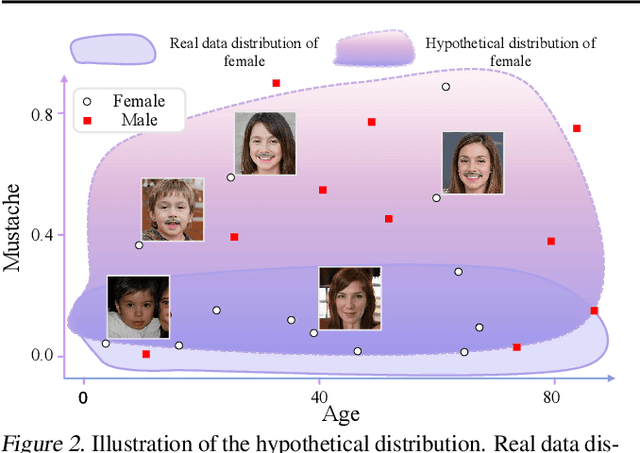

Human can extrapolate well, generalize daily knowledge into unseen scenarios, raise and answer counterfactual questions. To imitate this ability via generative models, previous works have extensively studied explicitly encoding Structural Causal Models (SCMs) into architectures of generator networks. This methodology, however, limits the flexibility of the generator as they must be carefully crafted to follow the causal graph, and demands a ground truth SCM with strong ignorability assumption as prior, which is a nontrivial assumption in many real scenarios. Thus, many current causal GAN methods fail to generate high fidelity counterfactual results as they cannot easily leverage state-of-the-art generative models. In this paper, we propose to study counterfactual synthesis from a new perspective of knowledge extrapolation, where a given knowledge dimension of the data distribution is extrapolated, but the remaining knowledge is kept indistinguishable from the original distribution. We show that an adversarial game with a closed-form discriminator can be used to address the knowledge extrapolation problem, and a novel principal knowledge descent method can efficiently estimate the extrapolated distribution through the adversarial game. Our method enjoys both elegant theoretical guarantees and superior performance in many scenarios.
Freeform Body Motion Generation from Speech
Mar 04, 2022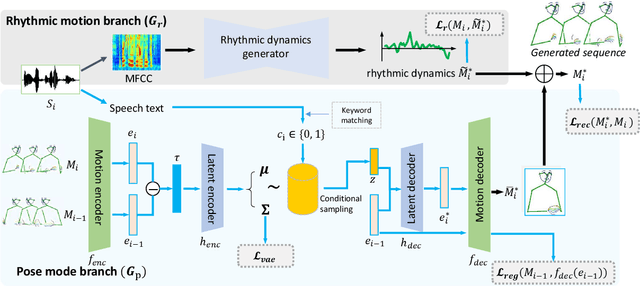
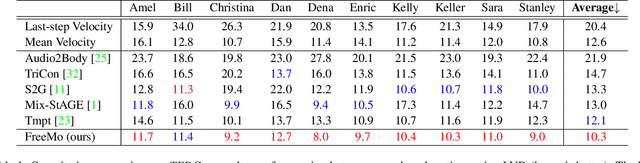
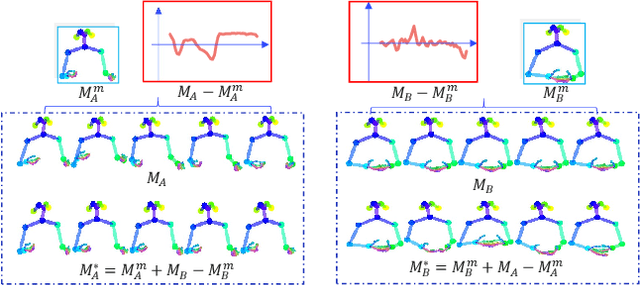
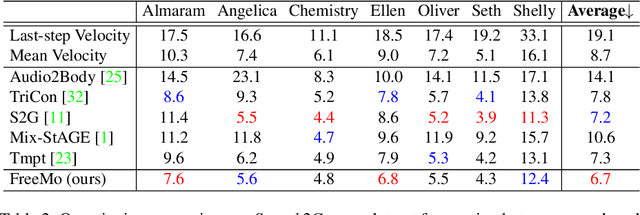
People naturally conduct spontaneous body motions to enhance their speeches while giving talks. Body motion generation from speech is inherently difficult due to the non-deterministic mapping from speech to body motions. Most existing works map speech to motion in a deterministic way by conditioning on certain styles, leading to sub-optimal results. Motivated by studies in linguistics, we decompose the co-speech motion into two complementary parts: pose modes and rhythmic dynamics. Accordingly, we introduce a novel freeform motion generation model (FreeMo) by equipping a two-stream architecture, i.e., a pose mode branch for primary posture generation, and a rhythmic motion branch for rhythmic dynamics synthesis. On one hand, diverse pose modes are generated by conditional sampling in a latent space, guided by speech semantics. On the other hand, rhythmic dynamics are synced with the speech prosody. Extensive experiments demonstrate the superior performance against several baselines, in terms of motion diversity, quality and syncing with speech. Code and pre-trained models will be publicly available through https://github.com/TheTempAccount/Co-Speech-Motion-Generation.
Contactless Electrocardiogram Monitoring with Millimeter Wave Radar
Dec 21, 2021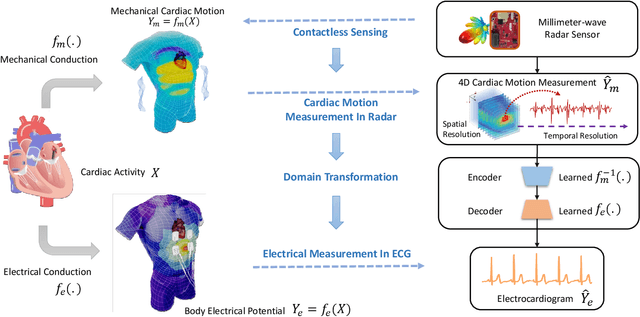

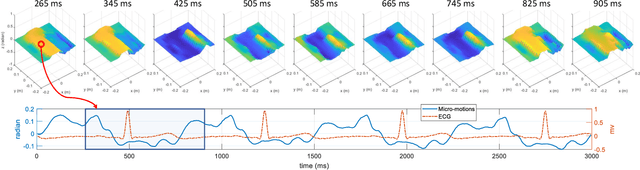
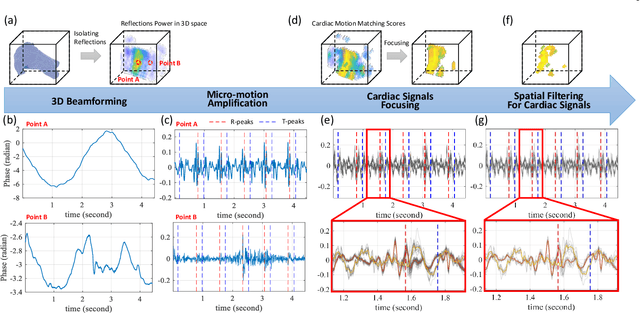
The electrocardiogram (ECG) has always been an important biomedical test to diagnose cardiovascular diseases. Current approaches for ECG monitoring are based on body attached electrodes leading to uncomfortable user experience. Therefore, contactless ECG monitoring has drawn tremendous attention, which however remains unsolved. In fact, cardiac electrical-mechanical activities are coupling in a well-coordinated pattern. In this paper, we achieve contactless ECG monitoring by breaking the boundary between the cardiac mechanical and electrical activity. Specifically, we develop a millimeter-wave radar system to contactlessly measure cardiac mechanical activity and reconstruct ECG without any contact in. To measure the cardiac mechanical activity comprehensively, we propose a series of signal processing algorithms to extract 4D cardiac motions from radio frequency (RF) signals. Furthermore, we design a deep neural network to solve the cardiac related domain transformation problem and achieve end-to-end reconstruction mapping from RF input to the ECG output. The experimental results show that our contactless ECG measurements achieve timing accuracy of cardiac electrical events with median error below 14ms and morphology accuracy with median Pearson-Correlation of 90% and median Root-Mean-Square-Error of 0.081mv compared to the groudtruth ECG. These results indicate that the system enables the potential of contactless, continuous and accurate ECG monitoring.
Radio-Assisted Human Detection
Dec 16, 2021
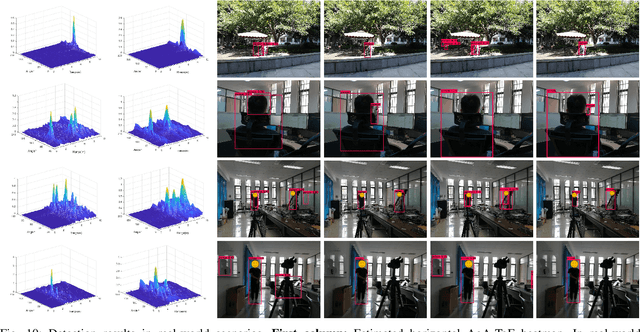
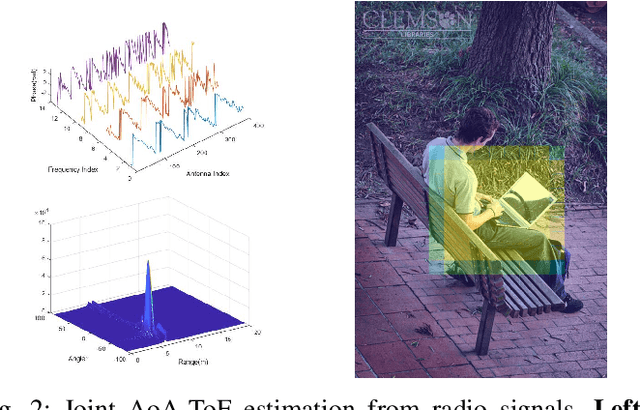
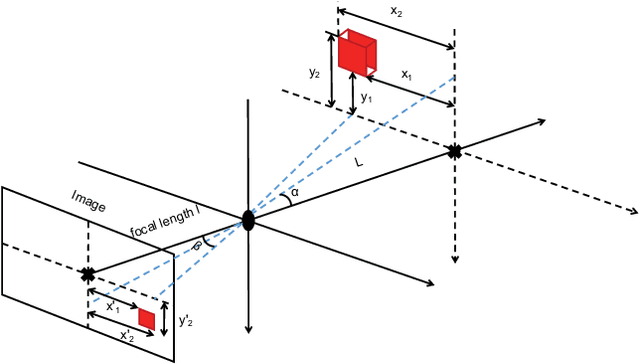
In this paper, we propose a radio-assisted human detection framework by incorporating radio information into the state-of-the-art detection methods, including anchor-based onestage detectors and two-stage detectors. We extract the radio localization and identifer information from the radio signals to assist the human detection, due to which the problem of false positives and false negatives can be greatly alleviated. For both detectors, we use the confidence score revision based on the radio localization to improve the detection performance. For two-stage detection methods, we propose to utilize the region proposals generated from radio localization rather than relying on region proposal network (RPN). Moreover, with the radio identifier information, a non-max suppression method with the radio localization constraint has also been proposed to further suppress the false detections and reduce miss detections. Experiments on the simulative Microsoft COCO dataset and Caltech pedestrian datasets show that the mean average precision (mAP) and the miss rate of the state-of-the-art detection methods can be improved with the aid of radio information. Finally, we conduct experiments in real-world scenarios to demonstrate the feasibility of our proposed method in practice.
Towards Domain-Independent and Real-Time Gesture Recognition Using mmWave Signal
Nov 11, 2021
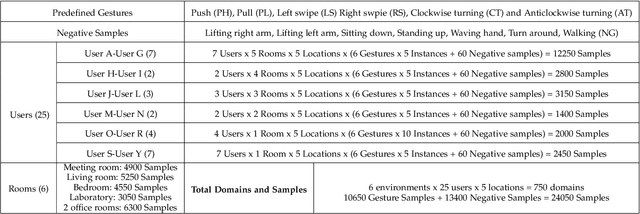


Human gesture recognition using millimeter wave (mmWave) signals provides attractive applications including smart home and in-car interface. While existing works achieve promising performance under controlled settings, practical applications are still limited due to the need of intensive data collection, extra training efforts when adapting to new domains (i.e. environments, persons and locations) and poor performance for real-time recognition. In this paper, we propose DI-Gesture, a domain-independent and real-time mmWave gesture recognition system. Specifically, we first derive the signal variation corresponding to human gestures with spatial-temporal processing. To enhance the robustness of the system and reduce data collecting efforts, we design a data augmentation framework based on the correlation between signal patterns and gesture variations. Furthermore, we propose a dynamic window mechanism to perform gesture segmentation automatically and accurately, thus enable real-time recognition. Finally, we build a lightweight neural network to extract spatial-temporal information from the data for gesture classification. Extensive experimental results show DI-Gesture achieves an average accuracy of 97.92%, 99.18% and 98.76% for new users, environments and locations, respectively. In real-time scenario, the accuracy of DI-Gesutre reaches over 97% with average inference time of 2.87ms, which demonstrates the superior robustness and effectiveness of our system.
Spatial-Temporal Correlation and Topology Learning for Person Re-Identification in Videos
Apr 15, 2021
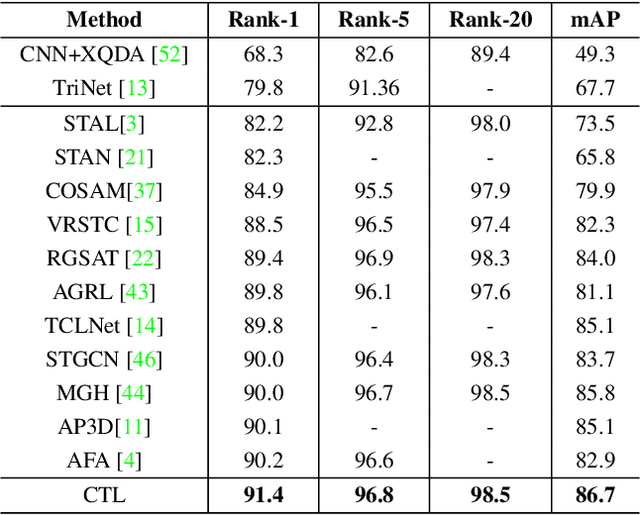
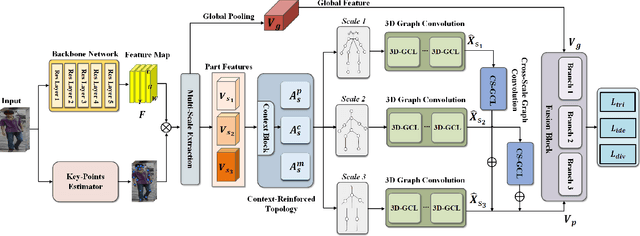
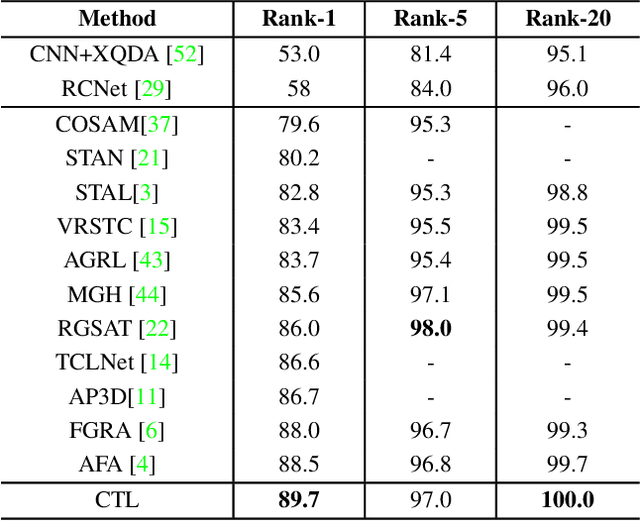
Video-based person re-identification aims to match pedestrians from video sequences across non-overlapping camera views. The key factor for video person re-identification is to effectively exploit both spatial and temporal clues from video sequences. In this work, we propose a novel Spatial-Temporal Correlation and Topology Learning framework (CTL) to pursue discriminative and robust representation by modeling cross-scale spatial-temporal correlation. Specifically, CTL utilizes a CNN backbone and a key-points estimator to extract semantic local features from human body at multiple granularities as graph nodes. It explores a context-reinforced topology to construct multi-scale graphs by considering both global contextual information and physical connections of human body. Moreover, a 3D graph convolution and a cross-scale graph convolution are designed, which facilitate direct cross-spacetime and cross-scale information propagation for capturing hierarchical spatial-temporal dependencies and structural information. By jointly performing the two convolutions, CTL effectively mines comprehensive clues that are complementary with appearance information to enhance representational capacity. Extensive experiments on two video benchmarks have demonstrated the effectiveness of the proposed method and the state-of-the-art performance.