 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
IFNet: Deep Imaging and Focusing for Handheld SAR with Millimeter-wave Signals
May 06, 2024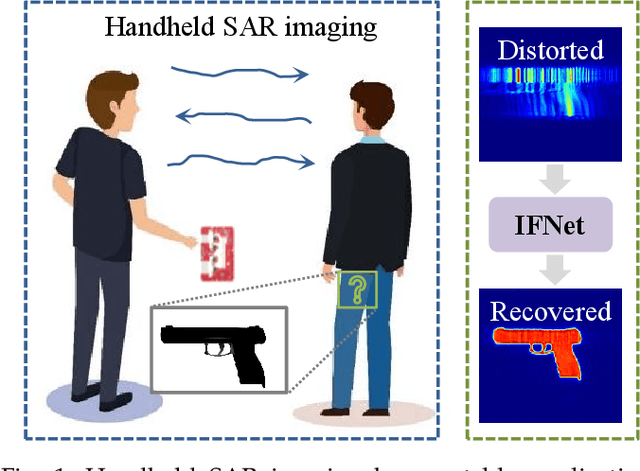
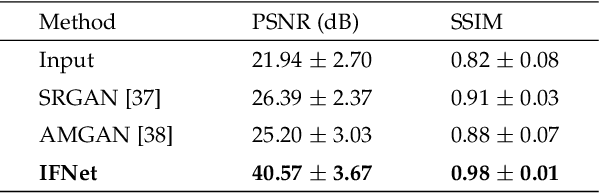
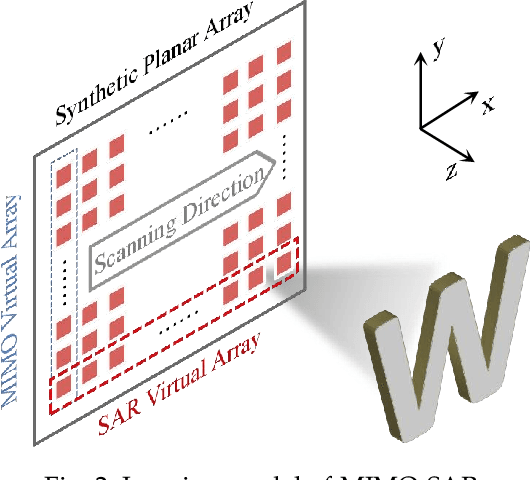

Recent advancements have showcased the potential of handheld millimeter-wave (mmWave) imaging, which applies synthetic aperture radar (SAR) principles in portable settings. However, existing studies addressing handheld motion errors either rely on costly tracking devices or employ simplified imaging models, leading to impractical deployment or limited performance. In this paper, we present IFNet, a novel deep unfolding network that combines the strengths of signal processing models and deep neural networks to achieve robust imaging and focusing for handheld mmWave systems. We first formulate the handheld imaging model by integrating multiple priors about mmWave images and handheld phase errors. Furthermore, we transform the optimization processes into an iterative network structure for improved and efficient imaging performance. Extensive experiments demonstrate that IFNet effectively compensates for handheld phase errors and recovers high-fidelity images from severely distorted signals. In comparison with existing methods, IFNet can achieve at least 11.89 dB improvement in average peak signal-to-noise ratio (PSNR) and 64.91% improvement in average structural similarity index measure (SSIM) on a real-world dataset.
DREAM-PCD: Deep Reconstruction and Enhancement of mmWave Radar Pointcloud
Sep 27, 2023Millimeter-wave (mmWave) radar pointcloud offers attractive potential for 3D sensing, thanks to its robustness in challenging conditions such as smoke and low illumination. However, existing methods failed to simultaneously address the three main challenges in mmWave radar pointcloud reconstruction: specular information lost, low angular resolution, and strong interference and noise. In this paper, we propose DREAM-PCD, a novel framework that combines signal processing and deep learning methods into three well-designed components to tackle all three challenges: Non-Coherent Accumulation for dense points, Synthetic Aperture Accumulation for improved angular resolution, and Real-Denoise Multiframe network for noise and interference removal. Moreover, the causal multiframe and "real-denoise" mechanisms in DREAM-PCD significantly enhance the generalization performance. We also introduce RadarEyes, the largest mmWave indoor dataset with over 1,000,000 frames, featuring a unique design incorporating two orthogonal single-chip radars, lidar, and camera, enriching dataset diversity and applications. Experimental results demonstrate that DREAM-PCD surpasses existing methods in reconstruction quality, and exhibits superior generalization and real-time capabilities, enabling high-quality real-time reconstruction of radar pointcloud under various parameters and scenarios. We believe that DREAM-PCD, along with the RadarEyes dataset, will significantly advance mmWave radar perception in future real-world applications.