 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeform Body Motion Generation from Speech
Paper and Code
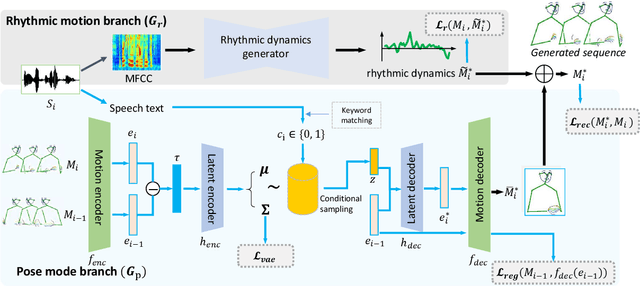
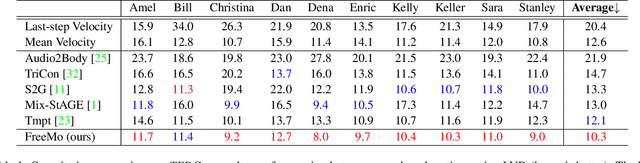
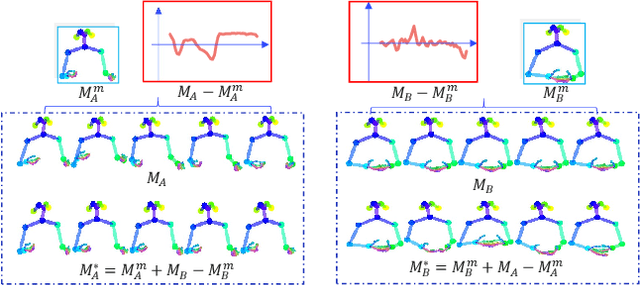
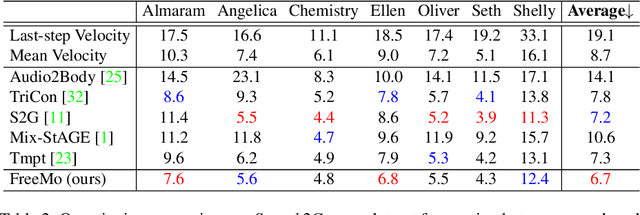
People naturally conduct spontaneous body motions to enhance their speeches while giving talks. Body motion generation from speech is inherently difficult due to the non-deterministic mapping from speech to body motions. Most existing works map speech to motion in a deterministic way by conditioning on certain styles, leading to sub-optimal results. Motivated by studies in linguistics, we decompose the co-speech motion into two complementary parts: pose modes and rhythmic dynamics. Accordingly, we introduce a novel freeform motion generation model (FreeMo) by equipping a two-stream architecture, i.e., a pose mode branch for primary posture generation, and a rhythmic motion branch for rhythmic dynamics synthesis. On one hand, diverse pose modes are generated by conditional sampling in a latent space, guided by speech semantics. On the other hand, rhythmic dynamics are synced with the speech prosody. Extensive experiments demonstrate the superior performance against several baselines, in terms of motion diversity, quality and syncing with speech. Code and pre-trained models will be publicly available through https://github.com/TheTempAccount/Co-Speech-Motion-Generation.